Handicap games with additional planes #2331
Comments
|
I have had a couple of very casual games and it definitely feels more like a game I might learn something from than a normal network. A couple of questions: |
|
@ihavnoid it does too many 3-3 invasions for a high handicap game
|
|
@iopq Yeah it seems that it is a problem. I tried 6 and 7 stones and it seems that it is learning that 3 3 invasion on first move is not a good idea with higher playouts (something like 10k playouts) though. The website is running 1500 playouts. |
|
@Hersmunch I dropped the acceleration mode data rather than downweighting them. It wasn't completely done from scratch though - I started from the 40B data with the endstate plane filled with the very last state of the board, and continuously ran training using the last 100k games. Now that I ran something like 200k games with 200 playouts, the initial data is all gone. |
I played a bit. I'm 3d and used 5 to 6 handicap. The bot was surprisingly strong. Many moves reminded me of games with professionals (the typical "oh, yes, of course there, now that suddenly became a problem for me!"). Some moves were clearly useless (asking me to make a clear mistake), and some useful forcing moves (kikashi) were not played while still possible. The bot sometimes failed to complicate the game and resigned early; I feel it should tenuki more often in such situations to keep the game alive. All in all, great work. |
|
I'm also 3d, played two games. First on 4 stones, I played passively and lost comfortably - it felt strong. Second game on 5 stones was odd. It wasn't apparent at first but I'm not sure it understood what's going on in some corner shapes, After dying it played a few forcing moves in the dead corner, a bit later got into a squeeze and pulled out a bad ladder. It feels like it's too reliant on the opponent answering obediently. |
|
very good! |
|
I can see that if it is still losing too terribly it will play nonsense moves. The auxillary output will also converge to zero if it feels it is hopeless - I will try to come up with a way to make that behave a bit more reasonably. |
|
Can we use the sum of endstate as the estimated score? |

|
@ihavnoid not compiled: 'pinnedOutBufferHost_es'==>opencl.cpp L357(not initialing error) |
|
@vipmath - pushed a minor fix addressing that error |
|
@ihavnoid very great thanks!! |
|
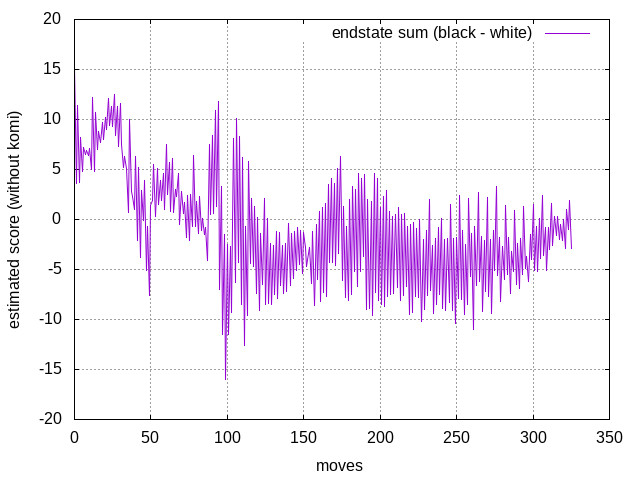
The sum of endstates seems oscillating. BTW, do you have a plan to add some outputs of endstates for GUIs? I am testing visualization of endstates and it looks interesting. For example, I can observe that an invasion increases the opponent's territory indirectly in other zones. |
|
@kaorahi I think some oscillation should be reasonable since playing every move will increase the probability of the player increasing its odd of winning. Plus, the komi's polarity should also change on every move, but the komi here is only 0.5 pts so it should be small. |
|
I think when the human makes the move suggested by the network, the expected score should not change too much (like two days ago in OpenAI Five Finals, the winrate doesn't change when Five picks a hero and only changes when human picks a hero). |
|
Well, in this case the expected score is the byproduct rather than the net output itself, so there will be errors accumulated here and there. I don't have any idea why it is oscillating with a pattern, though. |
|
Very interesting. I am around 1k level, and won on 9 stones with full effort. |

|
Thanks for your excellent work! |
|
I had this Idea for a while - to have 2 networks during a handicap games.
This has not yet been tested, on my to-do but won't be soon. |
|
Now that the weather is getting hotter, I have to shut down my machines that were used for training the nets - probably will resume when it gets colder so that the machines can contribute to heating my house. Still, I will leave https://cbaduk.net/ running. I would be happy if this gets merged into the master branch, but I still have a lot of concerns due to 1) this not really being perfect - it doesn't seem that the net will eventually learn enough to work with small number of playouts, and 2) there is no effort for training the nets using this alternative format here, and hence having code that exists for a net weight that isn't being produced here seems to be a move that is a bit odd. |
|
Nice! Glad to see other people experimenting with these ideas. One note on terminology - I think it's a not a great idea to still call it "winrate" if you're mixing a notion of score and such into it, particularly because it's no longer measuring the same type of thing as what everyone else usually uses "winrate" to mean. So the general word I've been using for it is "utility", because that's the generic word from both economics and a lot of existing agent and AI-based literature that precisely means "whatever a given agent is attempting to maximize". So in this case, you've set the utility for this new version of LZ to be a weighted sum of "winrate" and final score adjusted by uncertainty of the final ownership or endstate status. |
|
@ihavnoid I feel kind of sad that you can't contiue to train Handicap games's nets. I have a private computer system for machine learning, and I am interested in your Handicap games's nets. So if you don't mind, how about I resume it's training instead of you? If you are interested, please contact me by e-mail(trainewbie@gmail.com) |
|
For people who are interested in trying to go with a similar effort, I will clean up the code and rebase it against the latest 'next' branch. This should include:
|
|
Updated the code on : Quick way to run self-play games:
|
|
Usually I mounted two or more machines on the same disk and ran multiple minitrain.sh scripts. Or, I ran the script on a (potentially preemptive) google compute cloud machine, uploaded new nets as they appear, and download the training data periodically. Since it needs much more machines for selfplay than training, I only ran training for 6 hours a day on a single GPU - for the rest of the 18 hours all GPUs were used for self-play. |
|
@ihavnoid Great thanks for your update and detailed explanation. |
|
I used batch size of 64, and learning rate something like this: |
|
Sometimes, I have encountered error message when I used GPUs for self-play with multiple minitrain.sh scripts on Ubuntu 16.04. So I checked opencl version with clinfo. Should I install a different version of OpenCL driver? |
|
Well, if you are starting the training from scratch it seems that a random net is likely to hit self check failure - I recommend you disable self check for the first 10k games or so. If not... I don't know what to do. |
|
FYI I am using Ubuntu 18.04 on a 410.xx driver, using three GTX1080s. I did use 390.xx last year so it shouldn't be an issue, I think. |
|
@ihavnoid Thanks for your advice. I changed |
|
Great! I am also trying to train with a dataset (4700+) that clones the endstate branch and collects only my games.
|

I always wanted to learn how to play better, but I figured out that modern Go engines are just waaaaay better than mere mortals, and playing an even game with them will make things even harder to learn - and hence I always wanted an engine that is capable of playing handicapped games well. There were quite a bit of ideas that suggested good handicap game ideas, which some of them I tried and didn't work well.
Initially I tried the 'uneven playout' ideas or assigning more randomness to the losing side, but those all didn't go well due to the engines only learning to win by expecting the opponent to make some obvious mistake. The problem didn't really seem to be limited to the handicapped player having no hope of winning.
So, I decided to try some more tricks using ideas from KataGo (#2260). To be specific:
That is, winrate is calculated by the multiple of expected score and uncertainty - that is, the engine will prefer playing a chaotic game rather than giving the opponent clear territory.
With the idea, and after spending a couple of hundreds of $ on Google Compute, I got an engine that plays handicapped games (with 0.5 komi) quite reasonably well - it consistently beats me with 6 stone handicap. The problem is how to measure whether the games are 'fun', and being 'fun' is a quite subjective matter - so I would like some feedback on how the game 'feels'.
I put the current net running on a website that I am running - please visit https://cbaduk.net/ and try some handicap games and let me know how it feels. I will cleanup the code and post a branch and the net file that I have during the weekends.
The text was updated successfully, but these errors were encountered: