In this project I evaluate a search academic dataset using common learn-to-rank features, build a ranking model using the dataset, and discuss how additional features could be used and how they would impact the performance of the model.
Author: Vladimir Lezzhov
The dataset consists of feature vectors extracted from query-url pairs along with relevance judgment labels. Queries and urls are represented by IDs. The relevance judgments are obtained from a retired labeling set of a commercial web search engine (Microsoft Bing), which take 5 values from 0 (irrelevant) to 4 (perfectly relevant).
In the data files, each row corresponds to a query-url pair. The first column is relevance label of the pair, the second column is query id, and the following columns are features. The larger value the relevance label has, the more relevant the query-url pair is. A query-url pair is represented by a 136-dimensional feature vector.
Below are two rows from MSLR-WEB10K dataset:
==============================================
0 qid:1 1:3 2:0 3:2 4:2 … 135:0 136:0
2 qid:1 1:3 2:3 3:0 4:0 … 135:0 136:0
==============================================
You can read about the features included in the dataset here: https://www.microsoft.com/en-us/research/project/mslr/
LightGBM is a gradient boosting framework that uses tree based learning algorithm. It has support for learning to rank tasks. I chose LightGBM because it is a superior gradient boosting model when compared to xgboost as a baseline. It performs faster, has better accuracy, and consumes less memory.
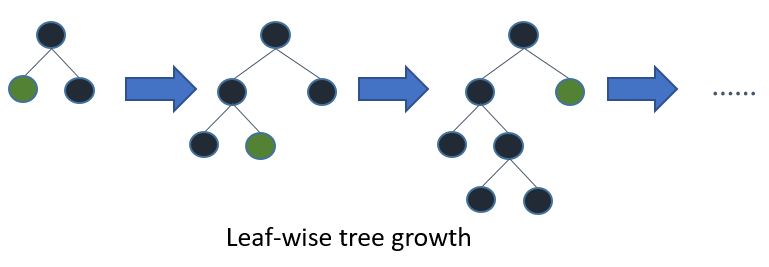
LightGBM grows tree vertically while other algorithm grows trees horizontally meaning that Light GBM grows tree leaf-wise while other algorithm grows level-wise. It will choose the leaf with max delta loss to grow. When growing the same leaf, Leaf-wise algorithm can reduce more loss than a level-wise algorithm.
I chose nDCG as the evaluation metric because it takes graded relevance values into account. It does a better job in evaluating the position of ranked items compared to MAP (which only considers binary relevance ranks, 0 or 1) or MRR (which only looks at the highest ranking document and does not consider all links).
nDCG employs a factor called smooth logarithmic discounting which improves performance. Authors of the work at http://proceedings.mlr.press/v30/Wang13.pdf show that for every pair of substantially different ranking recommender, the NDCG metric is consistently able to determine the better one.
All nDCG calculations are relative values on the interval 0.0 to 1.0. A perfect nDCG score would be 1.0. Therefore, considering the score of 0.9257691834034475, I think the model performed reasonably well.
Setup the project:
python3 setup.py install
Tuning the model hyperparameters:
python3 tune.py ../data
Training:
python3 train.py ../data
Or, to change hyperparameters from defaults during training:
python3 train.py ../data --num_leaves 66 --learning_rate 0.244 --reg_lambda 2.376
Testing:
python3 test_model.py ../data ../model.txt
Deploying:
python3 deploy.py ../data ../model.txt
Here are some possible ideas on how to improve the model's performance:
- Use the full available dataset instead of just 1 fold, possibly incorporating 5-fold cross-validation.
- Try to tune a higher number of hyperparameters
- Tune hyperparamters and train the model for a longer period of time
- Evaluate whether the removal of the features the paper found to be less useful did indeed lead to better results (compare mean nDCG scores for both cases)
- Consider overfitting and underfitting, try some of the strategies suggested here: https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html, e.g. use small max_bin, use min_data_in_leaf and min_sum_hessian_in_leaf, use bigger training data, etc
- Consider outliers for some features and remove them if necessary
- Consider if it is needed to engineer new features, or to take some out.
The following are thoughts on how additional features could be used:
- If I had an additional feature for each row of the dataset that was unique identifier for the user performing the query e.g. user_id, how could I use it to improve the performance of the model?
With the user behavior features, such as query-url click count, url click count, and url dwell time, it would be possible to employ collaborative filtering. We could create a profile of user behavior for each user_id, and compare it to trends from multiple users. This would provide a more tailored and informative approach, thus increasing model performance.
- If I had the additional features of: query_text or the actual textual query itself, as well as document text features like title_text, body_text, anchor_text, url for the document, how would I include them in my model to improve its performance?
One possibility is one-hot encoding the text features while perserving the word order, and passing them through a holographic dual LSTM learning to rank architecture, like the one described here: https://arxiv.org/pdf/1707.06372.pdf. LSTM is a good choice for processing sequential text data since it considers word order. It could then be possible to merge the model I created with the new LSTM via ensemble learning.