Before learning transformer related model, it's useful to have a look at the attention mechanism first.
Seq2seq is an Encoder–Decoder structured network with a sequence input and a sequence output. Both the input and output signal can be variable-length.
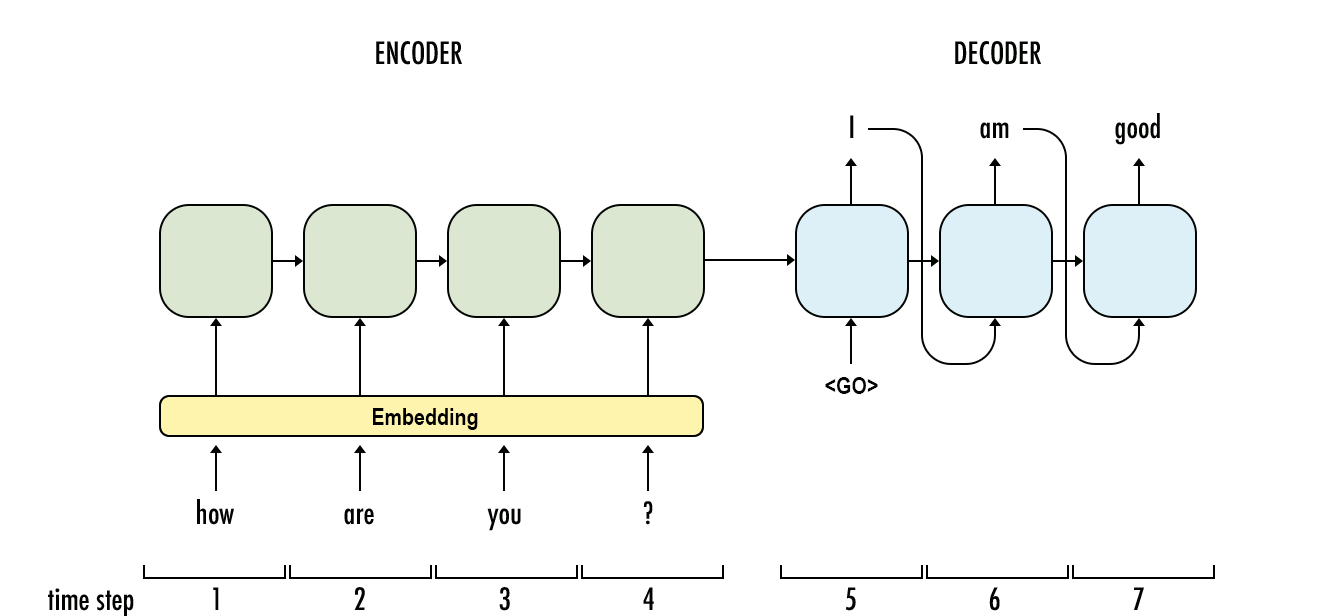
We use "attention" layer to bridge information from decoder with encoder so that we can get a context vector which can be added to the original decoder hidden states vector.
The following refers to: https://zhuanlan.zhihu.com/p/40920384
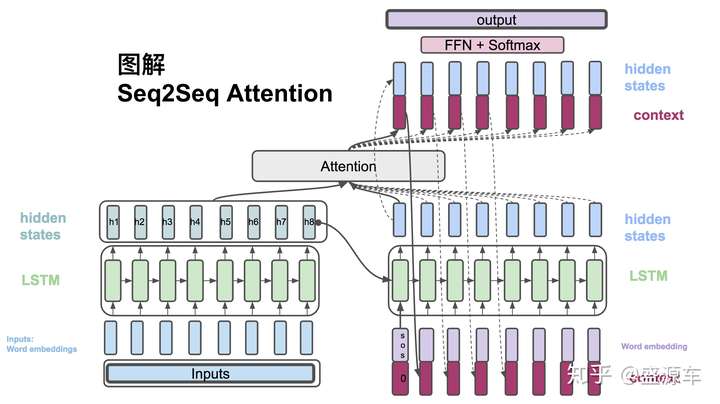
Input: x = (x1, x2, ..., xt_x), Output: y = (y1, y2, ..., yt_y)
For each encoder cell, the hidden state output at time step t:
For each decoder cell, the hidden state output at time step t:
For each hidden state in decoder (at time step i), we calculate scores with each hidden state in encoder (at time step j), which can be represented as weight:
Then we can get the weight of each hidden state in encoder for any hidden state j in decoder and get the weighted average context vector ci:
Finally, we concatenate ci and si, and apply softmax on this new vector:
As for the score function, usually, there are there methods:
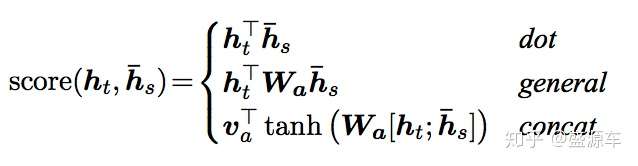
Refer to: https://blog.csdn.net/pipisorry/article/details/84946653
For the seq-to-seq problem, transformer uses scaled dot-product attention and multi-head attention instead of the traditional cnn or rnn architecture.
Traditional rnn models like LSTM or GRU have certain drawbacks:
- Sequencial calculation impedes parallel computing ability.
- Lack of long dependency information.
Encoder = 6 * (self-attention + FFNN) Decoder = 6 * (self-attention + encoder-decoder attention + FFNN), which uses outputs from encoder as inputs.
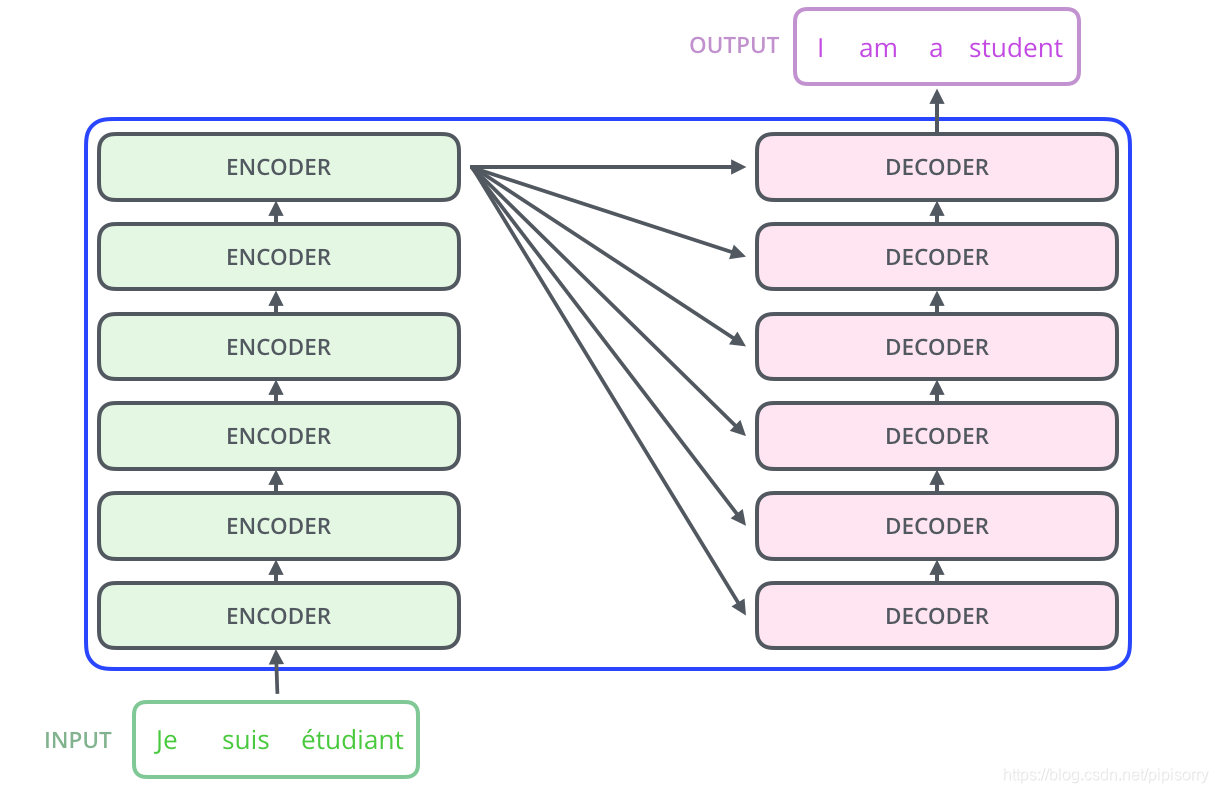
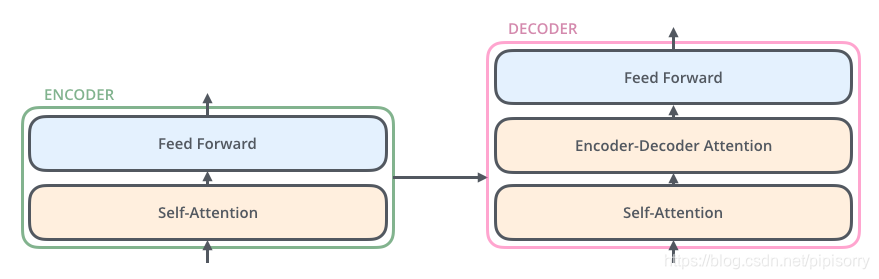
Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution.

Now we dig more into each block in encoder and decoder:
Multi-head self-attention mechanism + fully connected feed-forward network
Multi-head attention + residual connection + normalization
Multi-head attention:
Linear + scaled dot-product attention + concat + linear
Input: Query, Key, Value
Apply h different linear tranformations on Q,K,V, then concatenate all attention outputs.
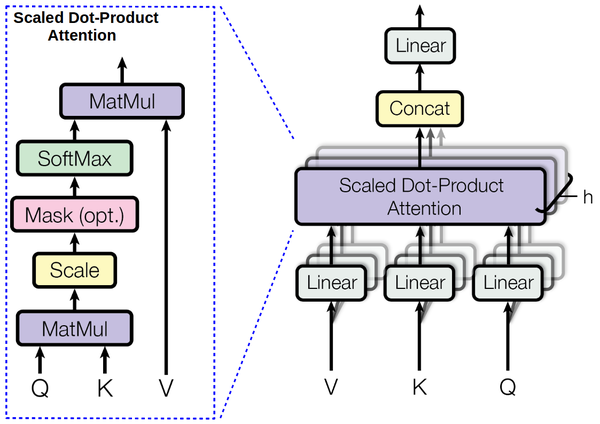
Note: In general attention mechanism, Q is the decoder hidden layer, K and V are the encoder hidden layer. While in self-attention, Q=K=V=sum of input embedding and positional embedding of encoder or decoder.
Scaled dot-product attention:
Following the equation above, here is a clear example:
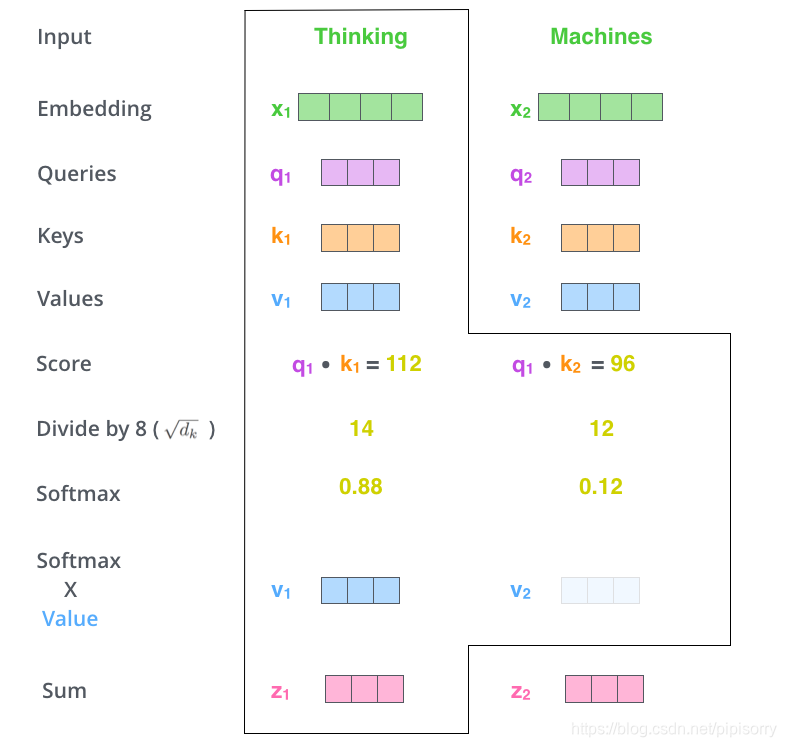
Although it's called as multi-head, in practice, it's implemented by transposing and reshaping tensors, not separating tensors.
If the output of multi-head attention is Z, then:
Same as encoder block, except that it has an attention sublayer.
Notice that the input of whole decoder is the last output of decoder (output from position i-1 as the input of position i) and the output from encoder. Besides, we can apply parallel computing on encoder, however, as for decoder, just like rnn model, we can only use the last (and before) position's output as input.
Without position information, transformer is just a high-level word-bag model. In order to represent sequence information, positional encoding is added on the input embedding.
以下出于时间效率考虑,换成中文来写。主要简单记录下对这些预训练语言模型相对粗浅的理解,以防遗忘。
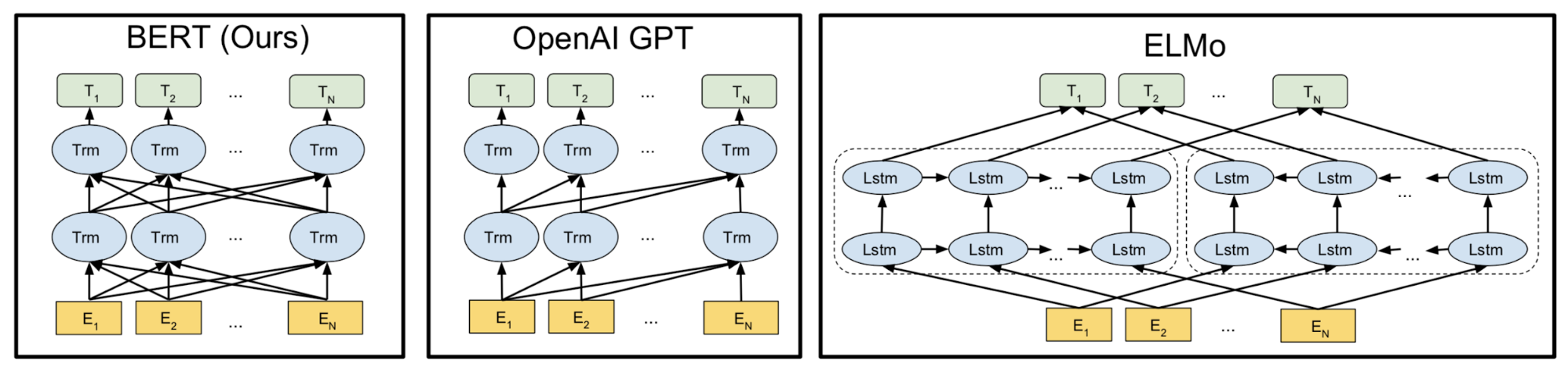
Bert区别于gpt这些模型的要点在于是双向结构,而非单向。专业术语描述是auto encoder模型而非auto regression模型。单向的意思指的是自然语句预测下一个单词时,是利用该单词上文信息单向预测,没有用到下文信息。gpt的实现方案就是以transformer架构作为基础模块、单元,如下图所示,以当前关注对象左边的所有输入作为transformer cell的输入,依次从左到右预测。该方案虽然很适合于文本生成任务,但是伴随的缺点是没有捕获当前关注对象的下文信息。显然,人类的自然语言是上下文相关的,前面的话语的理解有时候需要下文的说明才会明白整句话的含义。bert基于此,将下文信息从右到左传递,以期让当前关注对象同时获得上下文信息。值得注意的是gpt的从左到右架构,模型在训练或预测的时候只用到了上文的信息预测当前关注对象,当前关注对象的准确值不作为输入(因为当前关注对象是作为它的下一个单词的上文输入),而是作为gold value来和predict value对比求loss,因此不需要掩盖(mask)该对象(不会有信息泄露问题)。但是bert不一样,为了利用上下文的信息,并且同时保证当前关注对象不会信息泄露,所以需要将当前关注对象的value值mask,用mask作为输入,其他词照常输入(可以说gpt当前位置是为了预测下一个单词,而bert当前位置预测当前单词)。这带来了一个挑战,如果整句话训练的时候每次只有一个单词mask,计算效率太低,因此该论文提出将15%左右的输入mask掉,提高效率,同时又不能太多mask,否则失去了大量的有效信息。第二个挑战就是老生常谈的训练和预测不匹配问题。最终预测时整句话的输入是没有mask值的,与训练过程的范式不一致。至于其他例如position embedding和训练任务定义这里就不详述。
Bert区别于elmo的要点在于用transformer架构替换双LSTM架构。用自注意力模型实现长文本依赖提取,解决LSTM在长文本上的不足。这里值得注意的一点是,LSTM在局部关系的获取能力较强。在文本生成任务,从偏离样本采样纠错的过程中,由于LSTM能做到局部修正,因此如果能逐步修正近距离词,就可以将坏句子修复。而transformer严重依赖位置信息,所以在两句不合理的句子之间,其很难分辨哪种不合理更好一些。
综上bert一个比较明显的缺点是预测训练过程不匹配,以及其范式在文本生成任务天然不利。并且由于采用transformer的架构,会带来其固有的一些问题。
同时需要注意,这里提到的所有语言模型依然是以统计作为基础的学习。不具备推理能力。
xlnet主要解决bert在文本生成上的短板,以及预测训练不匹配的问题。主要是:
- 将auto encode模型换成auto regression模型的思路,即类似LSTM或gpt从左到右单向传播。但是为了利用上下文的信息,所以引入了排序机制。通过使得上下文同时出现在当前关注对象前面的概率比较大的采样策略,采样出多种排序策略。语言模型的训练目标就是使得所有排序策略的期望最大化。由此来说,貌似就不需要mask标签,但是实际模型中,是采用bert形式的结构,输入信息还是双向的(虽然在排序序列中看起来是单向),因此还是要采用mask标签,保留位置encoding。同时注意排序的方式会增加计算负担。
- 借鉴transformer xl的思路,即RNN的思路,分段循环机制,用上一分段辅助预测下一分段,有效应用在长文本问题。
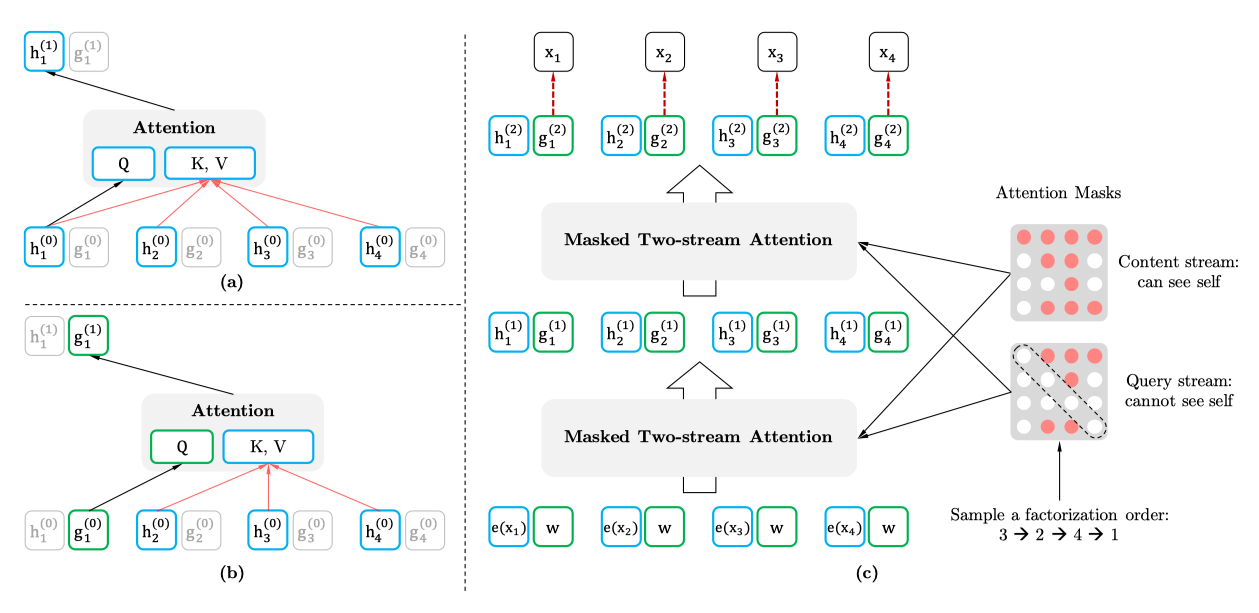
- 另一个比较经典值得一提的是双流机制。前面的分析提到,gpt、lstm从左到右的单向预测是不需要mask标签的,将原来的单词输入进去,也不会有信息泄露的问题。但是在xlnet里,因为排序后,当前关注对象同时利用了上下文的单词信息,第一个问题,如果当前关注对象未知(不作为输入,将其mask),预测出其位置对应的值后,再将其预测值作为输入预测排序顺序后置单词时,会有累积误差;第二个问题如果当前关注对象已知(作为输入,不mask),为了保留其位置信息,当前关注对象作为当前关注对象预测值的输入,显然会有信息泄露问题。
针对这个问题,xlnet提出了双流机制,即一股流是content stream h,知道当前关注对象的值,即将其作为直接输入,该股流不参与最终结果的预测。第二股流是query stream g,将当前关注对象mask,以mask输入。最终结果的预测由g来给出。通过h,可以始终以正确的输入来预测当前关注对象,不会有累积误差,解决第一个问题。通过g,当前关注对象的实际输入输出始终是mask值和其他位置的信息,不会有信息泄露问题,解决第二个问题。
在下文中会介绍两个transformer的变形,主要是基于transformer自身结构的调整,没有应用预训练语言模型架构。prophetnet网络的出发点是,在seq2seq问题或者传统的自回归问题背景下,transformer利用上文信息进行下一个单词的预测,因为1.只参考局部信息,2.加上两元组合比长依赖关系更加强烈,3.只预测一个单词,没有捕捉到未来的字符,4.在decode的过程采用贪婪解码,倾向于维持局部一致性,所以整体来说全局一致性和长依赖欠拟合。
为了解决这个问题,prophetnet很自然地提出了将之前只预测下一个单词的结构改成预测n-gram的结构。例如bigram即预测后面两个单词。值得注意的是,这边是直接用上文的信息同时预测后面n个单词,而不是将预测出来的单词再次作为输入。基于此,可能一开始想到的最基本的思想就是,网络最后一层的输出在dictionary size大小的vector里选择n个id作为输出,这个的问题是不知道预测出来的单词的顺序。prophetnet的改进思路是借鉴xlnet的双流机制,n+1个输入预测n个后面的单词,第一个是跟原本网络一样的main stream self-attention,另外n个是predict stream self-attention。要注意这n+1个网络共享参数。

训练任务文章称因为不能获得大量标注数据,所以采用mass, bart等采用的去噪自编码(用噪音破坏输入序列,任务是恢复原始的输入序列)任务来训练,如下图。

reformer的起步思想主要是解决transformer在长序列问题计算效率、存储效率过低的问题。因此在深入了解reformer之前,需要了解为什么transformer或者更广泛来说神经网络占用memory很大。可以参考这篇文章的总结。
在reformer文章里,作者主要提到:1. 最大transformer最大单层参数就占用2GB,输入的长序列64k token,1024embedding size,batch 8又要占用2GB。2.用来训练bert的corpus占用17GB。3. 实际transformer N层是单层的N倍,每一层的activation输出都要存储,因为计算反向梯度的时候会用到每一层的activation输出。4. 前馈层dff比注意力层dmodel深度更大,占用一大部分memory。5. 输入序列长度L的attention注意力计算就是O(L^2),64k的序列输入就可以耗光memory。
所以针对这些,reformer提出以下几个解决思路(具体也可以参考这两个链接1链接2)
针对计算自注意力时需要O(L^2)的时间和空间复杂度,考虑改进算法将其计算和空间复杂度提升到O(LlogL)。
具体做法是认为softmax获得attention的方式是稀疏的,本质attention会比较关注权重较大的key,因此只要将attention权重最大的32或64个key找到即可。故而借鉴最近邻算法,用哈希方式将各个向量编码,通过排序的方式把相近的向量聚集在同个bucket。不过该方式无法保证每个bucket里一定有query或者key,作者将Q投影矩阵认为与K投影矩阵相等,因此相当于只在query或者key所有向量里做哈希。
具体的哈希算法采用LSH方法,将所有向量投影到一个球面,将球面切分为n个bucket,在同个bucket的向量具有相同的哈希值。为了在概率上降低误差,通过多次的随机旋转向量,来判断是否都处于同个bucket来确定向量是否具有相同哈希值。

reformer里面采用的是angular lsh的方案。同时因为有时候相似的向量会有小概率情况出现在不同buckets,所以用multiple rounds的并集来降低这种情况出现的概率。

计算的过程中,不是按照bucket来划分,是按照chunk分块来划分,当前chunk会计算其以及前后两个chunk里处于同个bucket的attention。某种意义上限制了其计算间隔超过一个chunk但同处于一个bucket里的向量的attention,相当于强加一个先验。需要注意的是,即使是传统的注意力模型,实际implement时也不是O(L*L),为了减轻memory的压力,每次只计算一个qi,反向梯度计算时再重新计算。牺牲时间效率换取O(L)空间。

另一个需要注意的是,因为qk共享值,所以这边token对自己是没有attention的,如果有的话对自己的attention永远是最大的。
transformer encoder decoder N层结构需要存储N层激活输出,使用revnet仅存储一层激活输出副本,反向推导出每一层的激活,用时间换空间的方式节省空间存储。revnet虽然改了网络结构,但是只对结果有微小差别。

普通网络及resnet结构,都无法通过输出反推出输入。将resnet结构改为revnet即可。在reformer架构里,F为注意力层,G为前馈层。Y₁= X₁+Attention(X₂) Y₂= X₂+FeedForward(Y₁)。同时注意layer normalization被移动到residual blocks里面了。

前馈层的embedding维度比注意力层大很多,认为前馈层的计算独立于序列的各个位置,所以将输入输出分块成多个chunk,也是用时间换空间的方式,降低存储压力。因此revnet的输出以及注意力计算也是chunk分块。如果是large vocabulary,对log probability of outputs也分块。分块只是影响工程实现,numerically identical to transformer。因为reformer通常处理的序列长度和batch数量比较多,所以可以在计算过程中将没有用到的层参数转移到cpu。
