Improve Geometry:::Union() performance using clustering #692
Conversation
|
The thing I don't understand here is, isn't CascadedUnion already effectively doing this? The tree puts near-to-each-other things early in the union order. Is this on top of, or in replacement of, cascadedunion? |
|
This is on top of cascaded union. This prevents the pieces that don't intersect from going into the overlay engine together. |
|
Counter-intuitive. I'd have thought, working bottom-up, the disjoint parts would mostly come together near the end and get quickly no-opped with an envelope intersection test. |
|
The first and last columns ("geometry clusters" and "envelope clusters") give some idea of this. Canadian subdivisions (last row) form 175k geometry clusters but only 7k envelope clusters. |
4360e90
to
db7f0ce
Compare
|
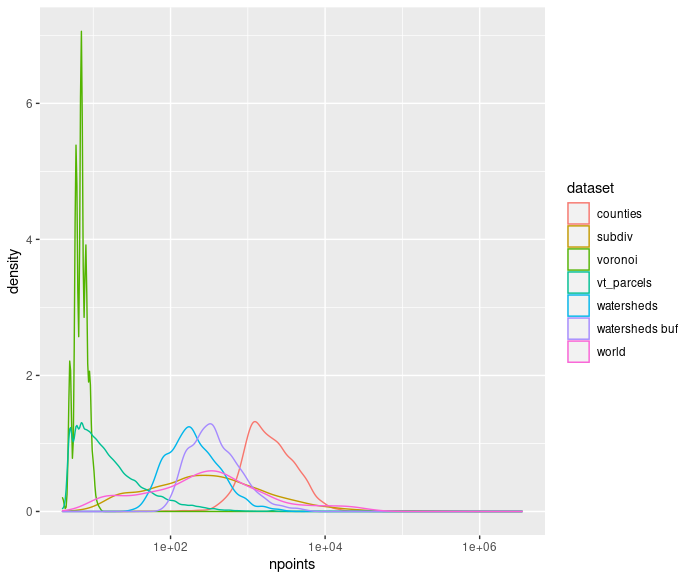
Maybe it's possible to do a reasonable algorithm selection based on average number of vertices/polygon. Above a certain number of vertices/polygon the union operation can be expected to be expensive enough that the pre-clustering isn't going to slow things down too much even if it accomplishes nothing. Here are the vertex count distributions for the current test datasets. The datasets that see meaningful slowdown (voronoi, parcels) have ~2 orders of magnitude fewer vertices than the others.
|
db7f0ce
to
7a7763f
Compare
|
Updated to revert changes to the default union strategy. Instead, |
This PR implements a pre-clustering step for
Geometry::Union()to divide inputs into disjoint sets before performing the union operation. Performance testing shows a large benefit in datasets with many disjoint polygons and no significant penalty in datasets with no disjoint polygons.I tried using envelope intersection, geometry intersection, and geometry distance as the basis for the clustering. The testing results show that geometry distance is preferred, since its performance is essentially equivalent to geometry intersection and is safe in the case where snap-rounding causes connected outputs from disjoint inputs. Timings are as follows, using
geosop unionwith 5 repeats (-r 5) for all except the most complex dataset where only one iteration was performed.main[s]The datasets are available in https://drive.google.com/drive/folders/1YNDsce_YiewgOiafPeJJOF4_AXlenX1C?usp=sharing