🔍 See our paper: "Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models"
🔍 See our newest Video Generation paper: "Mora: Enabling Generalist Video Generation via A Multi-Agent Framework"

)
📧 Please let us know if you find a mistake or have any suggestions by e-mail: lis221@lehigh.edu
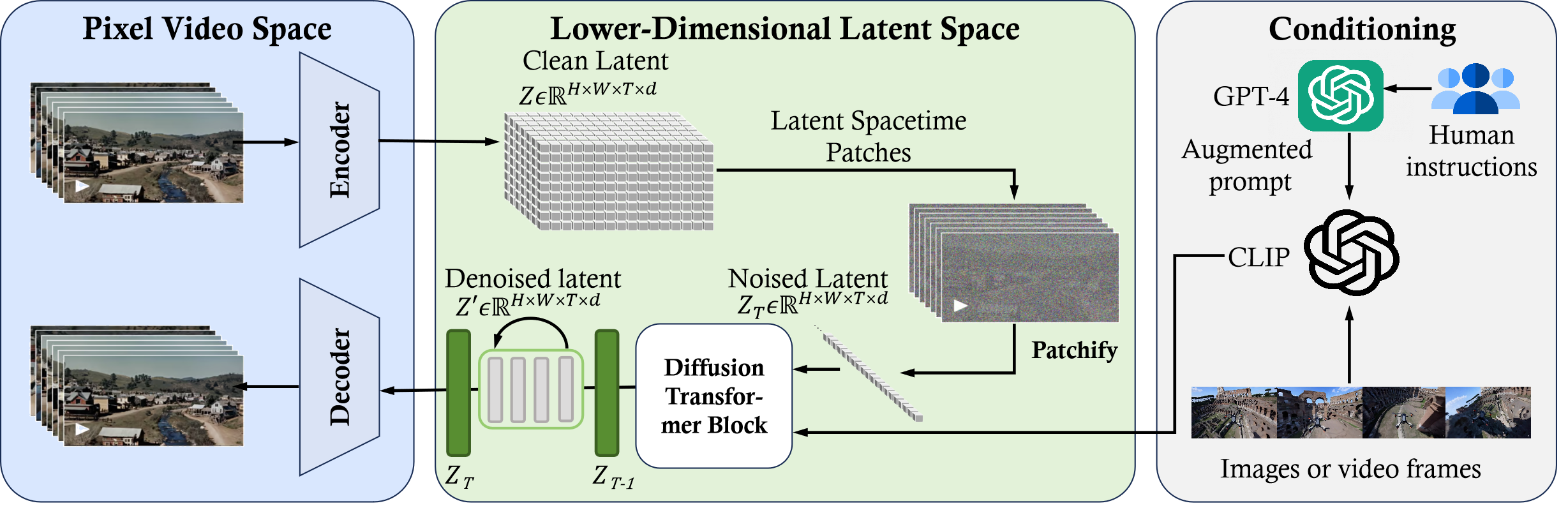
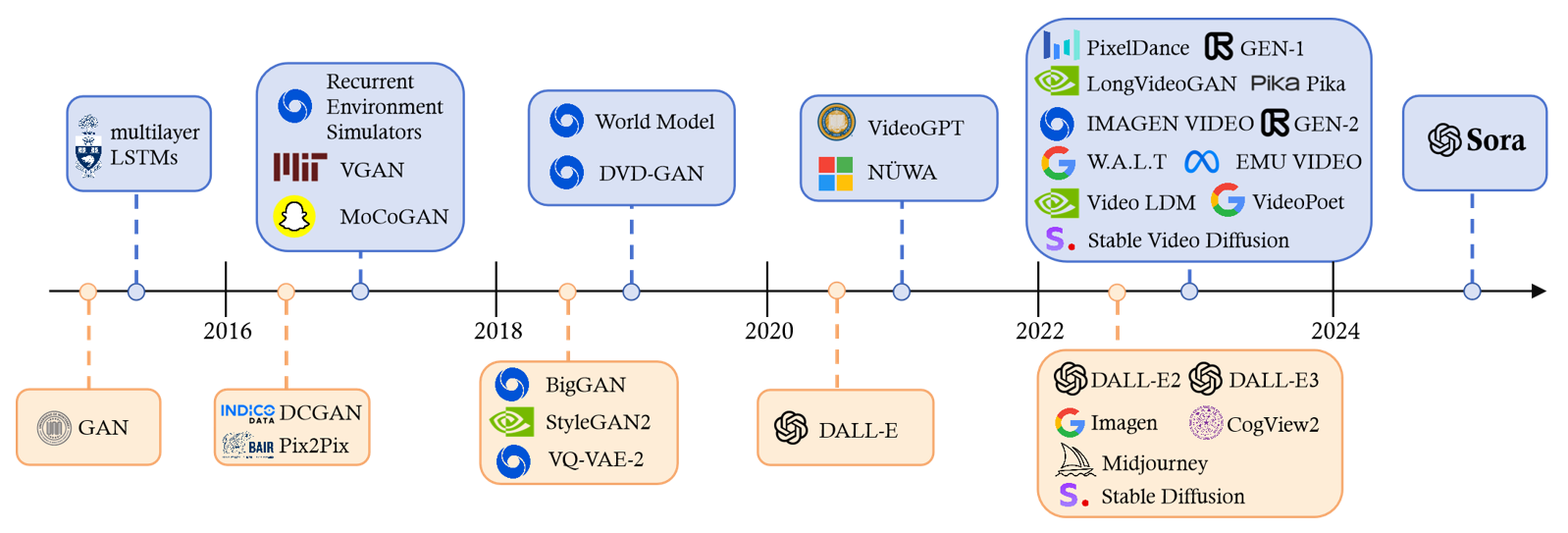
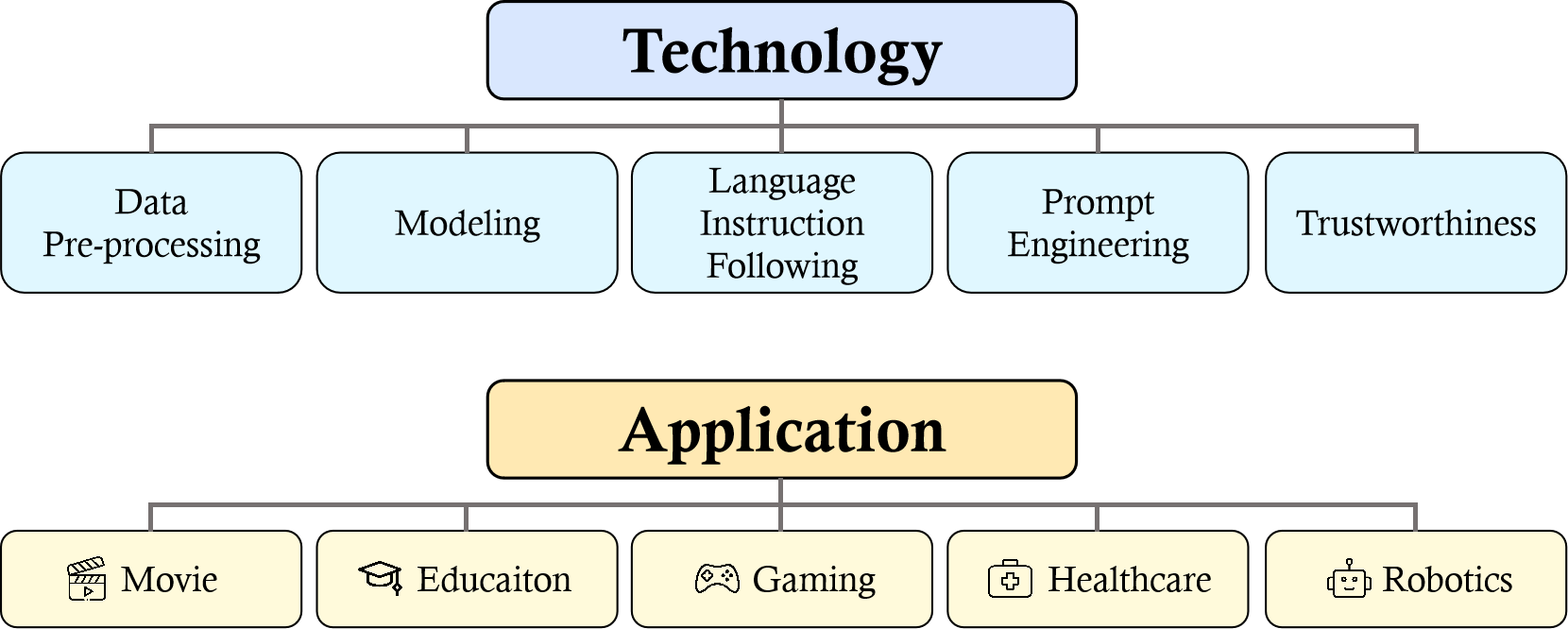
Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and shows potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model's background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora's development and investigate the underlying technologies used to build this "world simulator". Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from filmmaking and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
- 📄 [28/02/2024] Our paper has been uploaded to arXiv and was selected as the Daily Paper by Hugging Face.
- (NeurIPS'23) Patch n’Pack: Navit, A Vision Transformer for Any Aspect Ratio and Resolution [paper]
- (ICLR'21) An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale [paper][code]
- (arXiv 2013.12) Auto-Encoding Variational Bayes [paper]
- (ICCV'21) Vivit: A Video Vision Transformer [paper][code]
- (ICML'21) Is Space-Time Attention All You Need for Video Understanding? [paper][code]
- (NeurIPS'17) Neural Discrete Representation Learning [paper][code]
- (CVPR'22) High-Resolution Image Synthesis with Latent Diffusion Models [paper][code]
- (JMLR'22) Cascaded Diffusion Models for High Fidelity Image Generation [paper]
- (ICLR'22) Progressive Distillation for Fast Sampling of Diffusion Models [paper][code]
- Imagen Video: High Definition Video Generation with Diffusion Models [paper]
- (CVPR'23) Align Your Latents: High-Resolution Video Synthesis with Latent Diffusion Models [paper]
- (ICCV'23) Scalable Diffusion Models with Transformers [paper]
- (CVPR'23) All Are Worth Words: A ViT Backbone for Diffusion Models [paper][code]
- (ICCV'23) Masked Diffusion Transformer Is a Strong Image Synthesizer [paper][code]
- (arXiv 2023.12) DiffiT: Diffusion Vision Transformers for Image Generation [paper][code]
- (CVPR'24) GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation [paper]
- (arXiv 2023.09) LAVIE: High-Quality Video Generation with Cascaded Latent Diffusion Models [paper][code]
- (arXiv 2024.01) Latte: Latent Diffusion Transformer for Video Generation [paper][code]
- (arXiv 2024.03) Scaling Rectified Flow Transformers for High-Resolution Image Synthesis [paper]
- Improving Image Generation with Better Captions [paper]
- (arXiv 2022.05) CoCa: Contrastive Captioners are Image-Text Foundation Models [paper][code]
- (arXiv 2022.12) VideoCoCa: Video-Text Modeling with Zero-Shot Transfer from Contrastive Captioners [paper]
- (CVPR'23) InstructPix2Pix: Learning to Follow Image Editing Instructions [paper][code]
- (NeurlPS'23) Visual Instruction Tuning [paper][code]
- (ICML'23) mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image, and Video [paper][code]
- (arXiv 2022.05) GIT: A Generative Image-to-text Transformer for Vision and Language [paper][code]
- (CVPR'23) Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning [paper][code]
- (arXiv 2023.10) Unleashing the Potential of Prompt Engineering in Large Language Models: A Comprehensive Review [paper]
- (arXiv 2023.04) Boosted Prompt Ensembles for Large Language Models [paper][code]
- (NeurIPS'23) Optimizing Prompts for Text-to-Image Generation [paper][code]
- (CVPR'23) VoP: Text-Video Co-operative Prompt Tuning for Cross-Modal Retrieval [paper][code]
- (ICCV'23) Tune-a-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation [paper][code]
- (CVPR'22) Image Segmentation Using Text and Image Prompts [paper][code]
- (ACM Computing Surveys'23) Pre-Train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing [paper][code]
- (EMNLP'21) The Power of Scale for Parameter-Efficient Prompt Tuning [paper][code]
- (arXiv 2024.02) Jailbreaking Attack Against Multimodal Large Language Models [paper][code]
- (arXiv 2023.09) A Survey of Hallucination in Large Foundation Models [paper][code]
- (arXiv 2024.01) TrustLLM: Trustworthiness in Large Language Models [paper][code]
- (ICLR'24) AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models [paper][code]
- (NeurIPS'23) DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models [paper][code]
- Jailbroken: How Does LLM Safety Training Fail? [paper][code]
- (arXiv 2023.10) HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination & Visual Illusion in Large Vision-Language Models [paper][code]
- (arXiv 2023.09) Bias and Fairness in Large Language Models: A Survey [paper][code]
- (arXiv 2023.02) Fair Diffusion: Instructing Text-to-Image Generation Models on Fairness [paper][code]
- (arXiv 2023.06) MovieFactory: Automatic Movie Creation from Text Using Large Generative Models for Language and Images [paper]
- (ACM Multimedia'23) MobileVidFactory: Automatic Diffusion-Based Social Media Video Generation for Mobile Devices from Text [paper]
- (arXiv 2024.01) Vlogger: Make Your Dream A Vlog [paper] [code]
- (arXiv 2023.09) CCEdit: Creative and Controllable Video Editing via Diffusion Models [paper] [code]
- (TVCG'24) Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance [paper] [code]
- (ICLR'24) AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models Without Specific Tuning [paper] [code]
- (arXiv 2023.07) Animate-a-Story: Storytelling with Retrieval-Augmented Video Generation [paper] [code]
- (CVPR'23) Conditional Image-to-Video Generation with Latent Flow Diffusion Models [paper] [code]
- (arXiv 2023.11) Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation [paper] [code]
- (CVPR'22) Make It Move: Controllable Image-to-Video Generation with Text Descriptions [paper] [code]
- (AAAI'23) VIDM: Video Implicit Diffusion Models [paper] [code]
- (CVPR'23) Video Probabilistic Diffusion Models in Projected Latent Space [paper] [code]
- (CVPR'23) Physics-Driven Diffusion Models for Impact Sound Synthesis from Videos [paper] [code]
- (arXiv 2024.01) Dance-to-Music Generation with Encoder-Based Textual Inversion of Diffusion Models [paper]
- (bioRxiv 2023.11) Video Diffusion Models for the Apoptosis Forecasting [paper]
- (PRIME'23) DermoSegDiff: A Boundary-Aware Segmentation Diffusion Model for Skin Lesion Delineation [paper] [code]
- (ICCV'23) Multimodal Motion Conditioned Diffusion Model for Skeleton-Based Video Anomaly Detection [paper] [code]
- (arXiv 2023.01) MedSegDiff-V2: Diffusion Based Medical Image Segmentation with Transformer [paper] [code]
- (MICCAI'23) Diffusion Transformer U-Net for Medical Image Segmentation [paper]
- (IEEE RA-L'23) DALL-E-Bot: Introducing Web-Scale Diffusion Models to Robotics [paper]
- (CoRL'22) StructDiffusion: Object-Centric Diffusion for Semantic Rearrangement of Novel Objects [paper][code]
- (arXiv 2022.05) Planning with Diffusion for Flexible Behavior Synthesis [paper][code]
- (arXiv 2022.11) Is Conditional Generative Modeling All You Need for Decision-Making? [paper][code]
- (IROS'23) Motion Planning Diffusion: Learning and Planning of Robot Motions with Diffusion Models [paper][code]
- (ICLR'24) Seer: Language Instructed Video Prediction with Latent Diffusion Models [paper][code]
- (arXiv 2023.02) GenAug: Retargeting Behaviors to Unseen Situations via Generative Augmentation [paper][code]
- (arXiv 2022.12) CACTI: A Framework for Scalable Multi-Task Multi-Scene Visual Imitation Learning [paper][code]
@misc{2024SoraReview,
title={Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models},
author={Yixin Liu and Kai Zhang and Yuan Li and Zhiling Yan and Chujie Gao and Ruoxi Chen and Zhengqing Yuan and Yue Huang and Hanchi Sun and Jianfeng Gao and Lifang He and Lichao Sun},
year={2024},
eprint={2402.17177},
archivePrefix={arXiv},
primaryClass={cs.CV}
}