testcase minimization
Comparison: https://langston-barrett.github.io/treereduce/overview.html#comparison-to-other-tools
- Distributed Execution Minimizer (DEMi), a fuzzing and test case reducing tool for distributed systems. https://github.com/NetSys/demi
- (Language-agnostic) https://github.com/comby-tools/comby-reducer
- Rust treereduce - A fast, parallel, syntax-aware test case reducer based on tree-sitter grammars.
- Python shrinkray
- Python preduce. Language-agnostic.
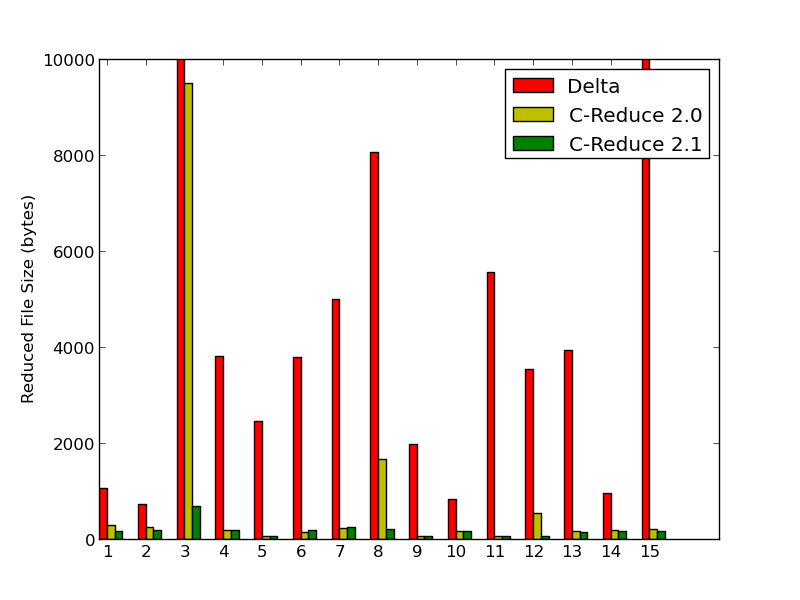
- C-Reduce, according to comparison C-Reduce is significantly better than Delta
- C-Vise https://github.com/marxin/cvise
- Delta-Debugging algorithm, see paper Simplifying Failure-Inducing Input, Ralf Hildebrandt and Andreas Zeller, 2000. Implementations:
- https://www.st.cs.uni-saarland.de/dd/
- SMT-LIB https://github.com/ddsmt/ddSMT, a delta debugger for SMT benchmarks in SMT-LIB v2.
- Python (reference implementation) https://www.st.cs.uni-saarland.de/dd/DD.py
- Python https://github.com/br0ns/ddmin
- Python picire - Parallel Delta Debugging Framework
- Python https://github.com/MarkusTeufelberger/afl-ddmin-mod/blob/master/afl-ddmin-mod.py
- Perl https://github.com/mpflanzer/delta/blob/master/delta
- JS https://github.com/wala/jsdelta
- Rust https://github.com/jubnzv/dd,
ddmplements basic delta debugging technique for tools that work with the Lua language. It modifies the AST of the given Lua program to find bugs in the tool. - https://en.wikipedia.org/wiki/Delta_debugging#Software
- https://github.com/MarkusTeufelberger/afl-ddmin-mod
- halfempty
- DustMite https://dlang.org/blog/2020/04/13/dustmite-the-general-purpose-data-reduction-tool/
- afl-tmin, description
- lithium (testcase reduction algorithm is a modified version of the "ddmin" algorithm in Andreas Zeller's paper, Simplifying and Isolating Failure-Inducing Input)
- picipreny - Hierarchical Delta Debugging Framework.
- perses - language-agnostic program reducer using ANTLR grammar.
- (without implementation) Generalized Tree Reduction (GTR), Jibesh Patra Satia Herfert and Michael Pradel -- Automatically Reducing Tree-Structured Test Inputs.
- (without implementation) "ORBS: language-independent program slicing"
- AFL: https://github.com/mirrorer/afl/blob/2fb5a3482ec27b593c57258baae7089ebdc89043/docs/technical_details.txt#L291-L313
{kind=link}
The actual minimization algorithm is:
1) Attempt to zero large blocks of data with large stepovers. Empirically,
this is shown to reduce the number of execs by preempting finer-grained
efforts later on.
2) Perform a block deletion pass with decreasing block sizes and stepovers,
binary-search-style.
3) Perform alphabet normalization by counting unique characters and trying
to bulk-replace each with a zero value.
4) As a last result, perform byte-by-byte normalization on non-zero bytes.
Instead of zeroing with a 0x00 byte, afl-tmin uses the ASCII digit '0'. This
is done because such a modification is much less likely to interfere with
text parsing, so it is more likely to result in successful minimization of
text files.
The algorithm used here is less involved than some other test case
minimization approaches proposed in academic work, but requires far fewer
executions and tends to produce comparable results in most real-world
applications.

Learning
- Glossary
- Books:
- Courses
- Learning Tools
- Bugs And Learned Lessons
- Cheatsheets
Tools / Services / Tests
- Quality Assurance Tools
- Test Runners
- Testing-As-A-Service
- Conformance Test Suites
- Test Infrastructure
- Fault injection
- TTCN-3
- Continuous Integration
- Speedup your CI
- Performance
- Formal Specification
- Toy Projects
- Test Impact Analysis
- Formats
Functional testing
- Automated testing
- By type:
WIP sections
Community
Links