第二周Live: Monero White Paper Introduction
文字稿整理:夏玮欹 wiki编辑:顺达
这篇白皮书写的很学术,不管是从写结构上还是对所用算法的描述上。可以说在水文众多的白皮书领域,算是诚心之作。
但是从专业上来看和学术论文还是有一定的差距,比如说:有的算法描述的不是很清楚,很多细节都理解不了。而且公式的符号代表什么意思,有时候也没有说清楚。所以如果要完全明白可能需要看一些补充资料,或者直接去看看代码。
从白皮书的角度简单介绍Monero(门罗币XMR)的思路
Monero是基于BTC的一种数字货币。首先白皮书先列出了BTC五点不足,哪有尝试要解决的问题。
- Lack of Untraceability & Unlinkability
- Proof of Work pricing function
- Irregular emission
- Hard coded constants
- Bulky scripts
第一点: 最主要是比特币没有办法保证Untraceability & Unlinkability。
这两个词的意思:在一个transaction里面,既不知道这个transaction是谁发的,也不知道是发给谁的。如果你能实现这两个性质的话就是一个完全匿名的系统。
白皮书对于这两个词的定义:
- Untraceability:对一个incoming transaction,你没有办法知道是谁发的
- Unlinkability,那就是说对于两个transaction你没有办法证明他们是不是发给同一个人。
注意:这里的“同一个人”并不一定是指同一个地址,而是指一个名字,可以是真名,或者是假名。
BTC显然不满足Untraceability,因为所有交易的发送方和接收方的地址都是公共的,大家都可以看到。对于Unlinkability也有一些研究证明,在比特币的网络中,你是可以发现交易信息和用户身份的一些关联。
Monera最主要的特点就是可以实现这两个性质。
第二点: 白皮书讨论一下Proof of Work,是属于CPU Bound,就是说要用很多CPU才能算出这个Proof of Work的哈希函数。这一点并不合理。作者认为在现代计算机架构的这种情况,应该用Memory Bound的题目来作为Pricing function更加合理。
第三点: BTC挖矿发奖励的速率是不连续的。大概每过四年就会减半,这样对大家的激励会出现一定的问题。
第四点: BTC很多参数都是hardcoded。由于比特币要求百分之五十一的人达成共识这个特性,所以每次改变参数的时候需要多数人的支持。所以参数改变起来非常困难,整个系统更新都比较慢。
第五点: BTC的script。BTC的script本身可以支持很复杂的交易,但是出于安全考虑很多功能都不能用,或者从来就没用过。并且一个很简单的script,就非常的冗长。Monero在不牺牲功能前提下把script做得短小精悍了一些。
Monero实现Untraceability & Unlinkability的主要数学工具是椭圆曲线加密。一般加密算法通常都是通过一些易验证难计算的数学题来实现。 (椭圆曲线加密在《精通比特币》一书中有详细说明,这里作者虽然说了一些,但就不记录了。)
Monera的实现思路:
- Unlinkability
每次交易的时候,公钥和私钥都是一次性的。你每次要发送交易的时候,发送方会根据自己要发送的内容和接收方一个公开的public key生成一个一次性的地址,然后往这个地址里面打钱,这样就实现了Unlinkability。
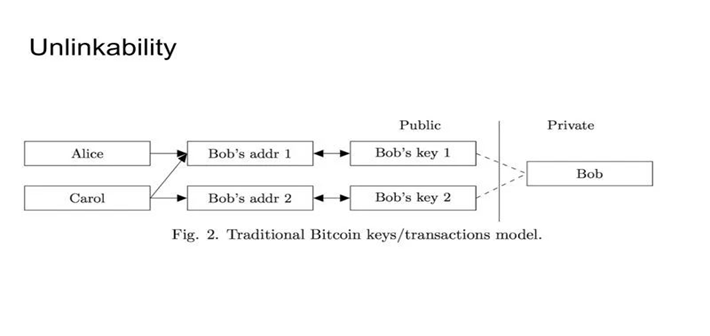
在BTC中,如果我们想要实现Unlinkability,我需要注册一堆小号弄一大堆公钥地址,然后呢对于不同的想给我发钱的人,我给他们不同的地址。那这样的话,每一个地址,就相当于只有一个人知道,那么在外人看来这两个人就不会把我关联起来。 但这种方法其实是你对BTC的一个hack,不是BTC这个系统它本身所支持的。
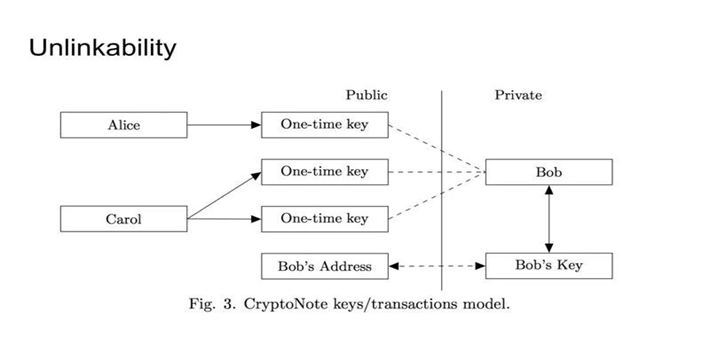
Monero本身就支持这个性质。假设你一个人有一对私钥和公钥。公钥是public的大家都可以看到。但是每次发钱的时候并不是往你这个public key里面打钱,而是发送方会根据他自己发送的内容和你这个地址生成一个一次性的地址,就像图里写的One-time key这样。那么这三个One-time key在外界看来没有办法联系到是你这个人本身。
- Untraceability
Monero实现Untraceability的方法主要是通过ring signature。(白皮书中的一个亮点)
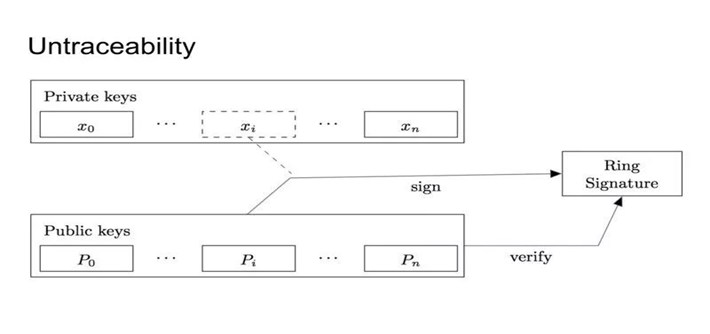
Ring signature的祖先比较简单,好理解的形式是group signature,翻译过来应该叫做群签名。 Group signature的思想其实特别简单:我用我的私钥签名,但是我不给大家我的公钥,而是我的公钥和我一大批我朋友的公钥,这样别人就只能证明这个签名是来自我们当中一个,但是并不能定位我这个人。
但是这个方法有一个很大的问题:管理这一堆公钥的manager知道这个群里面都有谁,他知道每个公钥对应的是谁,那么他如果不爽就可以任何时候都可以揭露用户的隐私。
之后又有人在这上面发明了一种叫做traceable ring signature的算法,主要是为了解决不诚实的signer的问题。
比如说:你参加美国大选。用环形签名就没人知道哪票是你投的,那么你可能直接会Trump投十票。那你要想捣乱的话也可以给Hilary投一票的同时也给Trump投一票。 这个算法主要就是来解决这种捣乱的人。
如果你投同一个人但是投了很多次,你所有的票就会被link起来。别人虽然不知道你是谁,但是他们就知道这些票来自同一个人,那么虽然他Trump投了十票,但还是会被算为一票。 但是你如果你投了两个人,那么你的身份直接就会被揭发出来。也就是说一会儿说这都是红的一会儿说这个东西是黑的,这个是不行的,我们是不允许这种事情存在,如果你干了这个事情我们就要把你揭发出来。
Monero的Untraceability主要就是基于traceable ring signature这篇文章。他弱化了traceable的部分,然后自己做了一些改变。投两票给Trump可以对应double spending。每一次你的一次性private key只能用来sign一次。如果你sign两次就会被发现,那么就防止了你把一块钱发两遍。
如果看图来表示这个Untraceability的实现就是,你用某一个私钥签名了,但是别人不知道是哪个私钥。大家可以用一个公钥的集合来验证你这个签名是有效的。
BTC设计的时候,中本聪设想的是一个CPU投一票。但是后来就出现了GPU和ASIC这种在计算能力上超越CPU很多,但是投资并没有比CPU明显提高的这样一些硬件。相当于你如果你有这些customized的硬件,你就比别人有优势,但是你的投资又没有显著提高。
所以白皮书里提出了这样一个愿望:如果你想你的voting power增长,那么你的投资的数额至少是要随你voting power增长而线性增长的。即,如果你想拥有比别人更多的投票权利,那么你就要增加你的投资。
显然哈希计算没有办法这个满足这个要求。根据现在计算机硬件的情况,白皮书里说我们应该用memory来限制投票能力可能是更合理的。
那我们想如果Proof of Work这个题目并不是算哈希,而是在一大块内存中读取一些随机位置的值然后返回,那么那些customized的硬件可能就没有那么大优势。
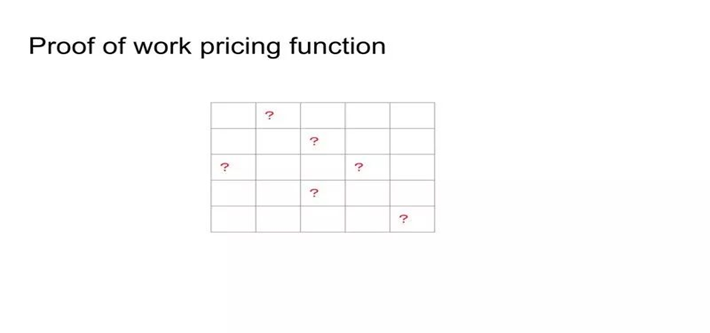
如上图中,在一大片内存里面放一些值。然后要求把红色问号儿的那些值都读出来,大概简单来说可以这么理解。
这样一来,CPU是比较擅长random access内存里面滴内容,而GPU或ASIC这些customized的硬件比较擅长迭代顺序的那种计算。所以那些拥有customized硬件的人可能就没有这么有优势。毕竟我们还要排除一种情况,就是用ASIC这些人。是用计算的方法来省内存,也就是他们用时间去换空间。
这个Memory里面放的东西,我们姑且把它叫做一个题目。这些题目现在有的算法是说,把这个Memory分块,然后一个块的内容可以通过另一些块计算出来。这样的话,如果你有ASIC,你肯定就不希望把整个内存的内容都存下来,而是说我就存比如一半,假如说每个块都是基于先前的块算出来的话,那我就存一半。所以如果你要求我给你返回的那个块我没有的话,那我就现场计算。这样的话我的计算资源就有优势。
如果能设计一种题目使得这种lazy computing的方法,比你直接去内存里面读更慢,那么这种算法就会使得ASIC和GPU这种硬件失去优势。
现在有一种叫做s creep的算法。现在LTC和有些BTC的fork都在使用。这种算法给出的题目中,每一块的内容都是基于前一块儿,所以呢lazy computing的方法还是可以让这些ASIC的用户有机可乘。
Monero白皮书也并没有仔细描述她想要什么算法,但是提了一句,是想让Memory每一块的值依赖于之前所有块的值,这样你lazy computing的代价就更大。但是这种Proof of Work合不合理还需要看他具体的算法描述和仔细分析。如果这只是一个新东西,实现不好的话它就是一个漏洞。从理论上来看这并没有算哈希那么直观,大家一看就知道复杂度是什么样的。
BTC发币的速度大概每过四年就会减半,在大约2020年的时候会从每个块12.5个变成6.25个。看上去似乎还行,但是在2012年11月28号,比特币的奖励从五十个下降到了二十五个。大家似乎就不认为这个还行,觉得有点不能忍。
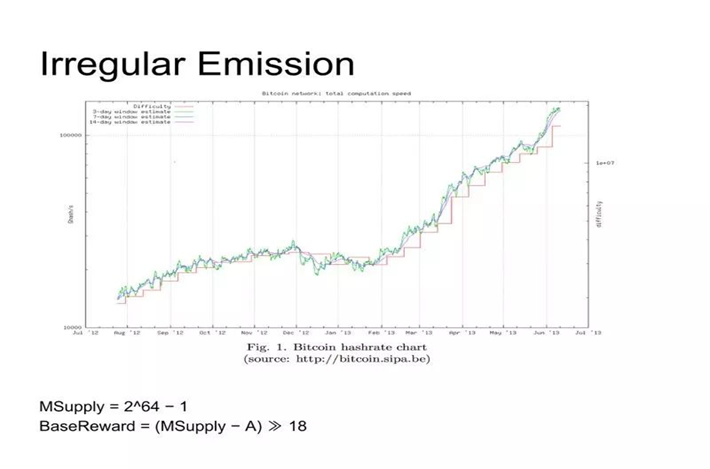
如上图,在十二月初到一月的时候,整个网络的算哈希的速度有一个非常明显的下降。Monero在白皮书中说,在这个断点的时候,大家心理上就会有一个很大的不平衡,大家都罢工的话,全网算力下降,这个时候就是那些有恶意的人可以进对整个网络进行攻击的好时机。
Monero中没有这种每过一段时间减一半这样有这么大断层的东西。先定一个最大的发行量,然后我们每次的reward,是基于最大的发行量减去已经发行量的一个算法,所以它相对平缓一些。
写死不好的原因:BTC要求百分之五十一的人共识才可以,所以软件更新的时候需要百分之五十一的人参加更新。
发生在2013年3月的故事:当时大家觉得每个块的大小不太够了,于是就升级了一次。升级了之后有一些比较大的块是可以被新升级的这些用户验证的,但是没有升级的用户是验证不了的,这是因为他们用的database的问题。
有一个人在论坛上就发了一个帖说,因为这次升级他搞了一个double spending的攻击。他发了一个很大的交易块,然后他发现他自己的交易被放在了一个很大的块里面,被那些已经更新了客户端验证了。验证之后,他往一个交易所里面转账,然后这个交易所就把他转的这个数额post给他了。给他之后,他发现他这个交易并没有被没有更新的那些人验证,于是他就又发了一遍。又发了一遍,最后更新的人的那条链roll back到没有更新的那条链上,于是他的相当于他成功实现了一次double spending。
Monero让这些参数可以自己随时间进行变化。比如,块的大小的确认:取最近n个块的大小的中位数。块的上限就是这个中位数的两倍。这个方法确实是可以随时间变化的,但是它也有问题。
比如他把最近n个块儿的都提得特别大,都是当前中位数的两倍,然后下一次你的中位数就会提升两倍,那么你的容量就会变成原来两倍大。如果你可以一直干这个事情你这块容量是可以指数增加的。虽然这种攻击不是很容易实现,但是它也是有可能的。
然后为了防止这个事情发生,Monero设计了一个对于大块的惩罚,相当于如果你这块特别大的话你就要交更多的交易费。如果大家都用起来的话显然不是很容易接受,比如说双十一的时候大家都购物,然后块就会特别大,于是转账的手续费就会增加,大家肯定不开心,于是影响你这个币的推广。

- 实现Untraceability & Unlinkability有很多参数,这些参数是否能够调好对整个系统有很大影响。
- 从商业上来说,这个项目可能在进一步增加大家隐私上会带来更大好处。比如可以逃避监管,获得更大隐私。