Setup for CIFAR-10 LARGE #7
Comments
|
Hi @zaccharieramzi , Thanks for the question! You should use the settings in the code. It's in general very important to keep the number of epochs the same. I believe you should be able to get the same level of results with the settings in the code (e.g., #1 (comment)). My impression is that your accuracy should be ~91.5% after ~100 epochs and ~92.5% after ~150-160 epochs, so maybe you can compare your log with that. |
|
I don't necessarily understand why the number of epochs would change something in the early behavior, especially such a huge drop. I will relaunch in full with 220 epochs nonetheless to make sure everything is similar to the original setup except paths. |
|
Not sure about the exact setting that you are running with, but the code is using cosine annealing learning rate decay (see https://github.com/locuslab/mdeq/blob/master/tools/cls_train.py#L203). If you only change the "END_EPOCH" entry in the config file to 50, then that will probably not be the "same" training process as the 220-epoch version indeed. |
|
Surely this must be it! Indeed if in classification we don't use such a tool, then the decay is not going to be correctly tuned. I will update this issue as soon as I get the info. EDITIt's indeed working (at least I don't see the drop I was seeing before). Thanks for being so patient, and closing this. |
Hi,
I am currently trying to replicate the results of MDEQ for the CIFAR-10 dataset using the LARGE configuration.
I noticed that there were discrepancies between the supplementary material of the paper and the file in the code.
I wanted to know which configs allowed you to achieve 93.8 top1 acc.
Discrepancies I noted: batch size, weight decay, # channels, # epochs, thresholds, dropout.
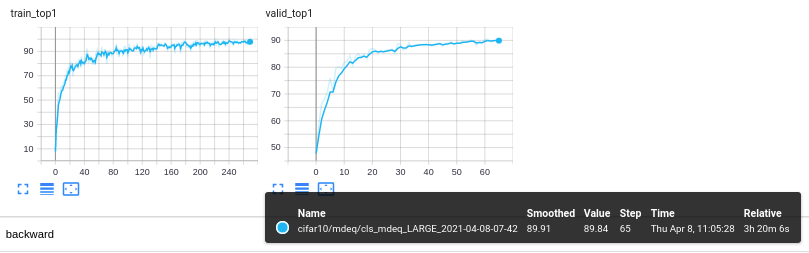
Currently, with the content of the file in the code unchanged (except paths, # epochs and resume), this is my learning curve (I did it in 2 steps because I originally had set 50 epochs):
The text was updated successfully, but these errors were encountered: