{kind=link}
dscc is a set of experiments trying to classify unlabeled data by combining clustering and classfication methods.
- Python3.5
- numpy
- scikit-learn
- pandas
- pylab
- bokeh (Guide)
git clone https://github.com/lpimem/dscc
python -m dscc.mainWe used @mblondel 's fuzzy k-means implementation: https://gist.github.com/mblondel/1451300
(the following is my part of the report)
In this section, We will first discuss alternative methods in feature extraction, dimensionality reduction, and clustering phases. For clarity, we implemented a framework in python to evaluate these different methods. Then, we will present our evaluation results among alternative approaches and the fuzzy-kmean method we adopted. In the last of this part, we will discuss Gaussian Mixture which is a related algorithm to Fuzzy K-Means.
In our work, data (students’ scores) are in numeric forms by nature. However, other real life problems may be not so convenient. For example, in natural language processing, we need to extract values from text corpus to get the number features we need to train the model. In our comparison part, we will extract features from 20-news-group data and apply TF-IDF transformation.
In our scheme, we used Principle Component Analysis (PCA) to reduce dimensionality of students’ scores. PCA works by computing the variance among original features[4]. Other unsupervised dimension reduction methods include random projections and feature agglomeration. The random projection(RP) method trades accuracy for processing times (time) and model size (space)[5]. It’s suitable for distance based methods such as nearest neighbors algorithms. Feature agglomeration (FA) applies a clustering method called hierarchical clustering to the features to group similar features to reduce the number of features. When applied to large numbers of features by joining a connectivity matrix, the feature agglomeration method can be computationally expensive.
Unlike PCA, RP and FA which are unsupervised methods to cut feature numbers, other approaches such as univariance and variance threshold requires knowledge of the labels to determine which feature to keep and which to remove[6]. For purpose of demonstration, we will use one supervised univariance method called ‘select k best’ for comparison. 4.1.3 Clustering methods As aforementioned, fuzzy k-means is a special case of k-means. K-means works by measuring variance among samples such that that ineriat is minimized. As in our assumptions, we already know the number of clusters, k-means can also be used to perform the clustering part in lieu of the fuzzy version.
Spectral clustering models is built upon k-means methods. It first does a low-dimension embedding of the affinity matrix[8] and then does a k-means on the low-dimension plane. It is suitable for small numbers of features. Hierarchical Clustering[9] does it work by following a linkage strategy or joining with a connection matrix to merge or split clusters. It is not computationally efficient when numbers of samples is large and no connection restriction can be applied to filter out possibilities. Nearest-neighbors is suitable for distance-related clustering tasks. As such algorithms makes no assumption on the numbers of clusters, it doesn’t fit our scenario well and we didn’t include such cases in our comparison experiment.
We implemented a python-based program to compare the accurate scores of different alternative methods against the PCA + fuzzy k-means method we used. Specifically, we used two categories of documents from 20newsgroups[10] data, and compared SelectKBest method against PCA for dimensionality reduction, K-Means, Spectral Clustering, and Agglomerative Clustering against Fuzzy K-Means for clustering. For classification, we used support vector machine with a rbf(radical basis function) kernel.
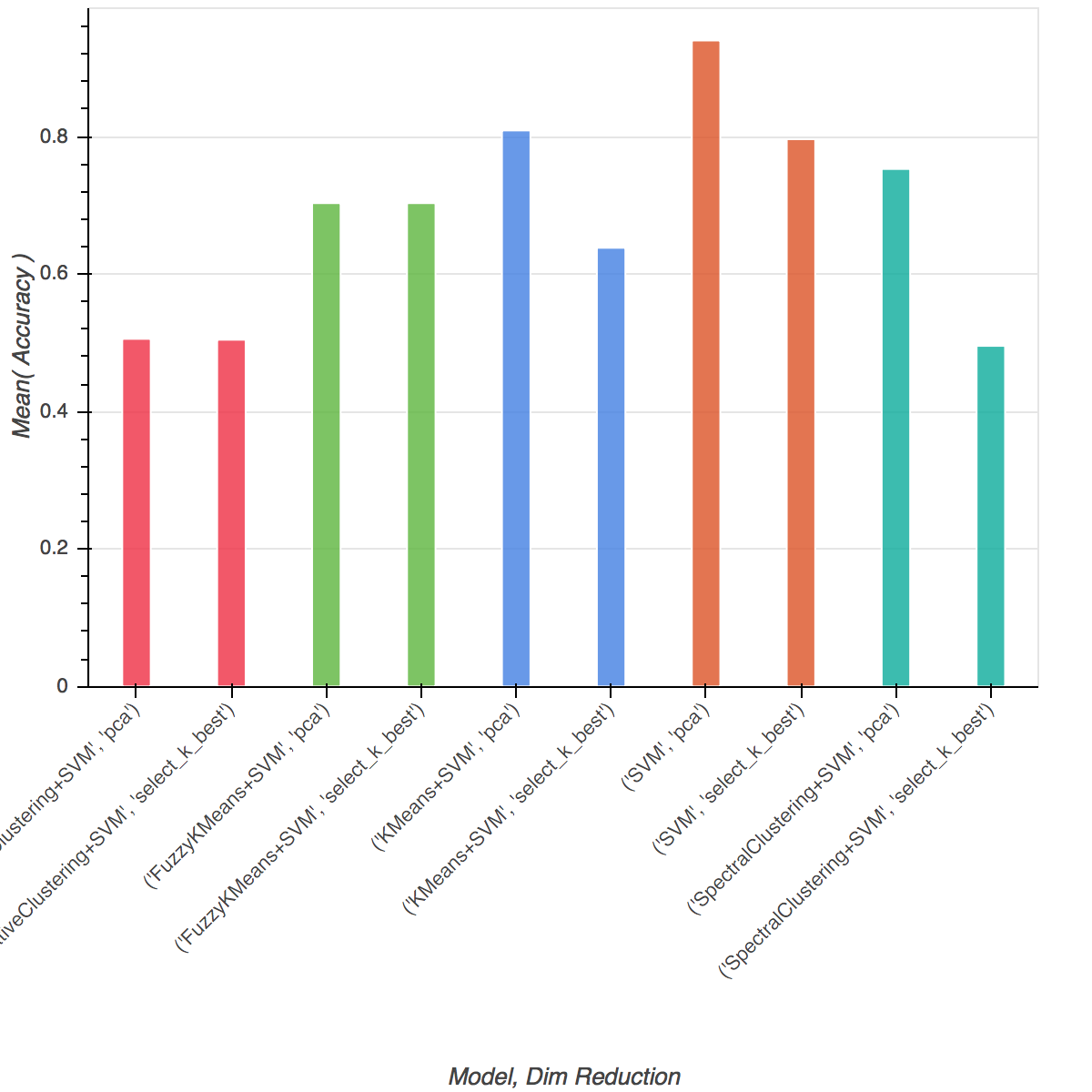 Figure-4 Comparison of Alternative methods
Figure-4 Comparison of Alternative methods
Figure-4 shows the comparison result of our test. The bare SVM + PCA method out performs all other clustering+SVM methods as expected. Our comparison shows aside from fuzzy k-means, other clustering methods could also be effective with respect to accuracy of the trained classifier. For detailed result data, please see Appendix table II.
[4] Sk-Learn: Unsupervised Dimensionality Reduction http://scikit-learn.org/stable/modules/unsupervised_reduction.html
[5] Sk-learn: Random Projection http://scikit-learn.org/stable/modules/random_projection.html#random-projection
[6] Sk-learn: Feature Selection http://scikit-learn.org/stable/modules/feature_selection.html
[7] Winkler, R., Klawonn, F., & Kruse, R. Fuzzy c-means in high dimensional spaces. 2012. Contemporary Theory and Pragmatic Approaches in Fuzzy Computing Utilization, 1.
[8] "spectral-clustering — Scikit-Learn 0.18.1 Documentation". 2016. Scikit-Learn.Org. Accessed December 6 2016. http://scikit-learn.org/stable/modules/clustering.html#spectral-clustering.
[9] "hierarchical-clustering — Scikit-Learn 0.18.1 Documentation". 2016. Scikit-Learn.Org. Accessed December 6 2016. http://scikit-learn.org/stable/modules/clustering.html#hierarchical-clustering.
[10] "5.6.2. The 20 Newsgroups Text Dataset — Scikit-Learn 0.18.1 Documentation". 2016. Scikit-Learn.Org. Accessed December 6 2016. http://scikit-learn.org/stable/datasets/twenty_newsgroups.html.