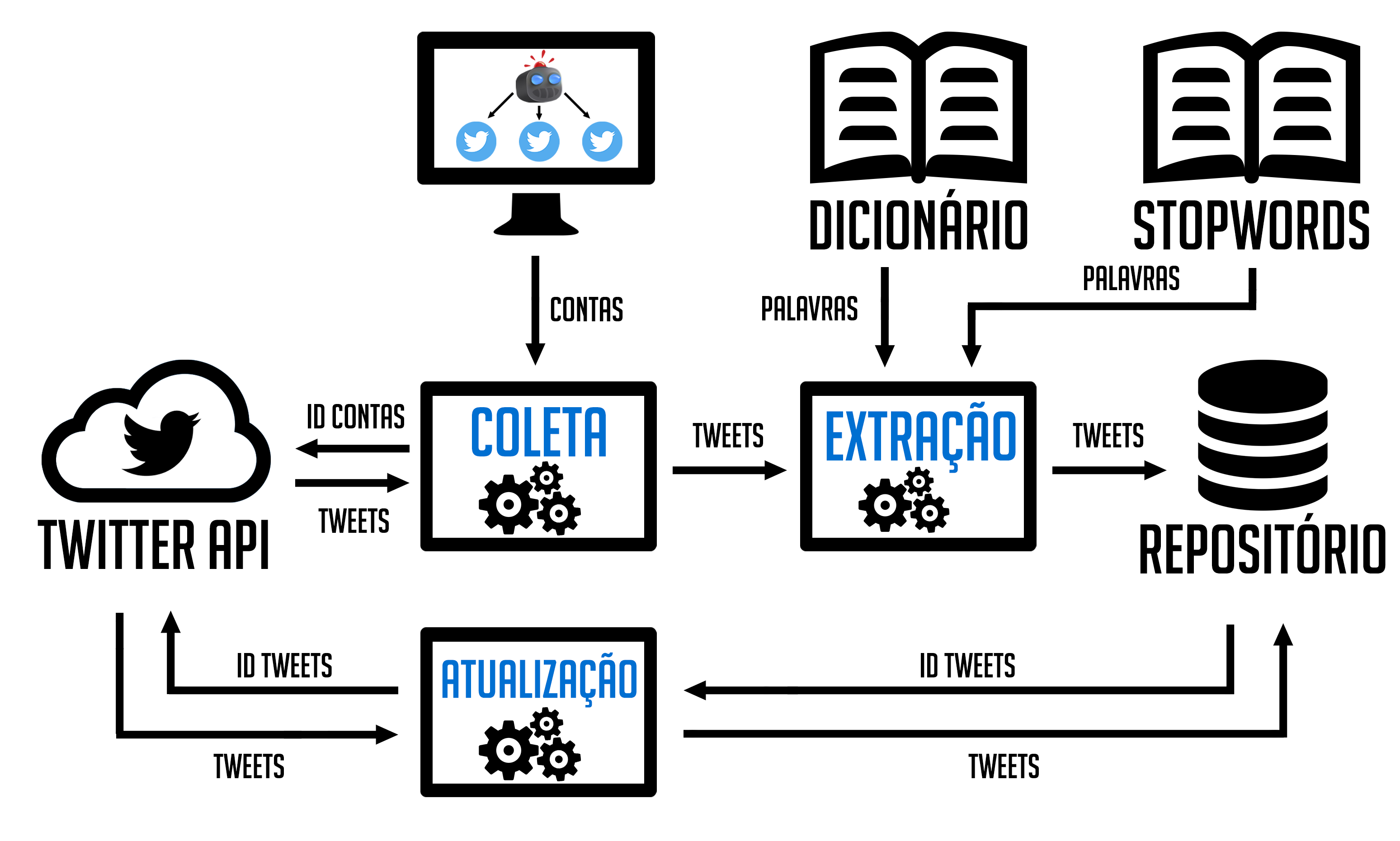
Algoritmos desenvolvidos para coleta e processamento de tweets que foram utilizados em projetos durante o curso de Bacharelado em Sistemas de Informação na Universidade Federal de Santa Maria.
O projeto foi desenvolvido em Python (helper, src), utilizando uma base de dados estruturada em MySQL (tweetGather_bd.sql). Para realização de análises iniciais, a parte visualização com alguns gráficos e tabelas foi desenvolvida em PHP, utilizando HTML, CSS e JS (display).
No que corresponde a parte de coleta, estão disponíveis códigos para coleta de tweets via streaming e atualização dos dados de engajamento. Já no contexto de processamento, estão disponíveis códigos para:
- Operações no banco de dados; dicionários de palavras;
- Geração de arquivo de log;
- Pré-processamento do texto dos tweets;
- Análise de sentimentos (utilizando a biblioteca TextBlob);
- Preparação de arquivos do tipo ARFF para utilização no Weka conforme necessidades do projeto (mais detalhes sobre esse processo encontram-se no capítulo 3.4.1 sobre Balanceamento das Instâncias no PDF do TCC, logo abaixo, página 29);
- Algoritmo Naive Bayes para classificação dos tweets utilizando o texto pré-processado.
Maiores detalhes sobre a utilização dos algoritmos e resultados obtidos podem ser encontrados no artigo publicado e trabalho de conclusão de curso gerado.
Para instalação dos requisitos necessários utilizar o comando:
$ pip3 install -r requirements.txt
Criar conta na plataforma Twitter Developers e gerar as chaves e tokens de acesso. Criar um arquivo helper/authenticate.py com a seguinte estrutura:
def api_tokens(verify):
keys = {}
keys['consumer_key'] = "consumer_key"
keys['consumer_secret'] = "consumer_secret"
keys['access_token'] = "access_token"
keys['access_token_secret'] = "access_token_secret"
return keysTrabalho de Concolusão de Curso - PDF:
Título: Utilização de algoritmos de aprendizado de máquina para prever a popularidade de tuítes
Orientador: Sérgio Luís Sardi Mergen
Instituição: Universidade Federal de Santa Maria (UFSM)
Repositório: ufsm-tcc-si-2018
Artigo publicado no ERBD 2018 - PDF
Título: Análise da Popularidade de Tuítes com Base em Características Extraídas de seu Conteúdo
Orientador: Sérgio Luís Sardi Mergen
Instituição: Universidade Federal de Santa Maria (UFSM)
🏆 Premiação: Melhor artigo de pesquisa do evento
Arquitetura de coleta e processamento dos dados