Tensors must have same number of dimensions : got 5 and 3 #238
Comments
|
CCT is only supporting 2D images and I don't think Phil has 3D ViTs incorporated into the library. Luckily they aren't that difficult to write from scratch. I'm not very familiar with voxel based networks but a quick Google search shows some 3D ViT githubs and a few survey papers. So I would look at those to see how they transform the data. |
|
@satwiksunnam19 let me know if this helps https://github.com/lucidrains/vit-pytorch#3d-vit @stevenwalton would be happy to offer a 3D CCT version, if you haven't completed it already Satwik |
@lucidrains I have completed the vit-3d model and it's working good and i can add my vit-3d project to your GitHub , if you're willing me to do so. |
|
@satwiksunnam19 that would be a great contribution! 🙏 |
|
@satwiksunnam19 i went ahead and added it, thank you for reporting that it works well! |
|
Hello @lucidrains @stevenwalton Can you change the perspective to the 3d model and explain how the flattened patches and there sizes are determined? I'm confused at this part. please respond to this ASAP. |
|
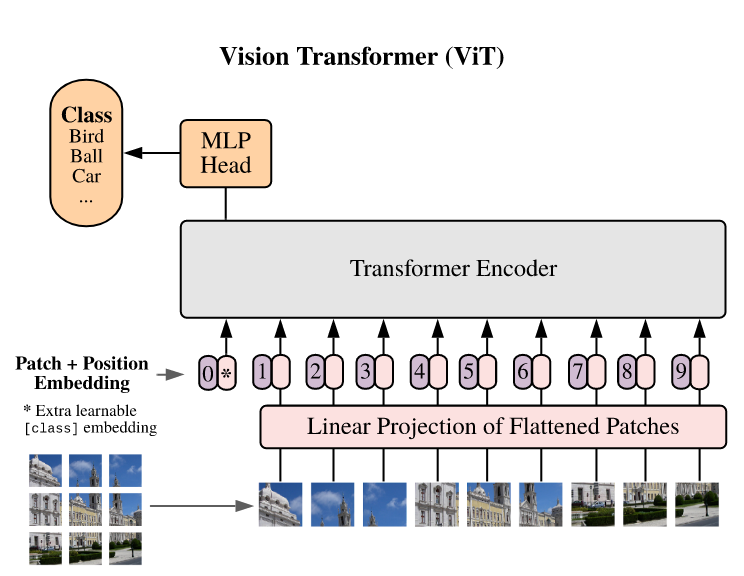
I think you're having trouble understanding the tokenization process for ViTs in general. CCT isn't that complicated (our work's main motivation is how simple changes can do a lot) and simply patch and embeds in a single action (allowing for better embedding) than working with specific patches. Compare CCT to ViT. The flattening is happening because we're creating a pixel space domain. Channels x Height x Width -> Channels x Pixels. As per the original ViT paper.. If you also look at the 3D code you'll notice Phil only changes a few lines (i.e.
Forgive us. We have research of our own to perform and busy work schedules that we also need to address at high priority. |
|
Thanks @lucidrains @stevenwalton |
Hello @lucidrains @stevenwalton
I have been trying to implement the standard ViT in 3d space and I have worked on some part of code ViT changed the Rearrange in patch embedding to as follows
Rearrange('b e (h p1) (w p2) (d p3) -> b (e p1 p2 p3) h w d',p1=patch_size,p2=patch_size,p3=patch_size)and this patch embbeddings are passed to map with cls_tokenscls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)which throws an error due to dimensionality mismatch so how can i change the shape of cls_tokens to match the dimensionality of the patch_embeddings.can you help me for getting solution to this problem
Thanks & Regards
Satwik Sunnam
The text was updated successfully, but these errors were encountered: