General Discussion for train loss, test Loss value and result accuracy #84
Comments
|
|
Thanks, @lululxvi, You have clarified my doubts. One more doubt arises for the small value of the train loss term.
so, can we say that train loss for (b) is better than (a). |
|
If the training residual points are dense, yes. You can also check the test error by using more dense test points. |
|
Thanks @lululxvi. It's sort out my doubts. |
|
dear Dr @lululxvi to the x-axis at x =0).
Also, result for this iteration has a small difference from the computed result. comment, please. |

|
I didn't get what you mean. In the plot, the test loss is not zero. |
|
sorry @lululxvi
|
|
No, the training loss is too large. See "Q: I failed to train the network or get the right solution, e.g., the training loss is large." at FAQ. |
|
Thanks @lululxvi for your Kind information, ds_xx + ds_yy - Ra* dT_x = 0 dT_y * ds_x - dT_x * ds_y -( dT_xx + dT_yy) = 0 Neumann BC: Dirichlet BC: for that, I have coded it as training graph for train and test loss is:
Numerical train loss value during epoch is:
BC for the left edge of the domain is not learning properly, Kindly, comment and give some tips to make it learn properly. |


|
The code looks OK. Do you have exact solution to compare? |
|
Yes @lululxvi Isotherm plot is: Actually the streamline plot obtained by DeepXDE simulation appears similar to the above result but the numerical values are not close to the result. I am little bit confused for the final outcomes from Deep learning. Kindly suggest something. |


|
Try:
|
|
After your suggestion for I have modified the code as:
and code is: but, unfortunately, the intermediate learning process does not seem good, especially for Neumann BC. The intermediate training loss for 20000 out of 95000 epochs is:
For a long time, I am not getting proper learning in the case of Neumann BC. Kindly, give me some tips to get rid of this learning issue. Thanks |

|
Could you try even large network, e.g., [256] * 5, and a smaller learning rate, e.g., 1e-4? |
|
Dear @lululxvi Sir, Kindly, comment something Also, after your suggestion, I have further modified my code: All the above changes remain the same but the only network and learning rate has modified as: network size:
learning rate after compilation of the code, I'll intimate you. |
|
Dear @lululxvi
Unfortunately, I am getting an error due to overflooded on size volume which snapshot is:
After reducing the network size from 5 to 4, code is running but a huge time. |


|
Unfortunately, no luck again based on your suggestion. I kept a few parameters as: Rayleigh Number:
Number of domain and boundary point as: NN Network size as:
Enforcing the exact Dirichlet BC for s and T is: learning rate: 1e-8
no of epochs = 95000 Combining all these modifications to the code, the training graph and output results are really disappointing. Streamline (S) plot after 95k epochs. Tepmr (T) plo after 95k epochs Training loss during the last few epochs which very huge. training I am eagerly waiting for your response @lululxvi sir. Kindly take a look at my code_file is : |


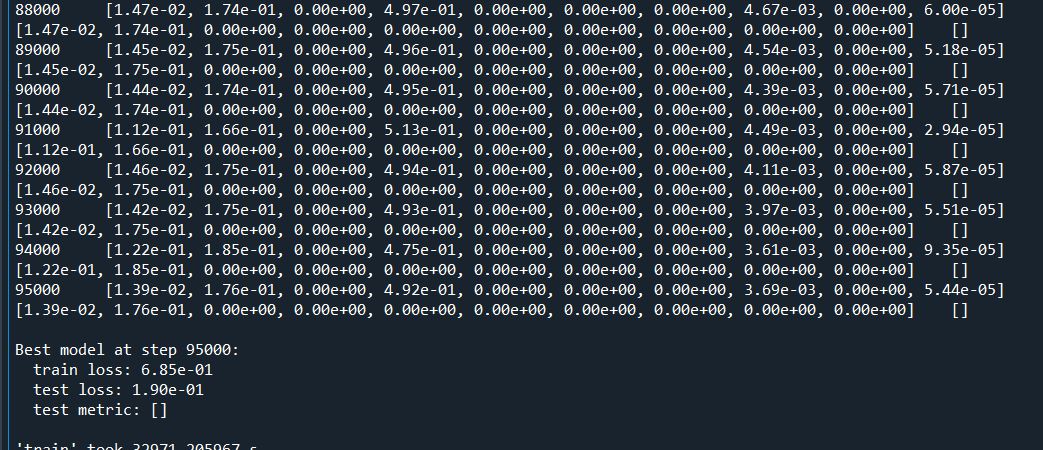
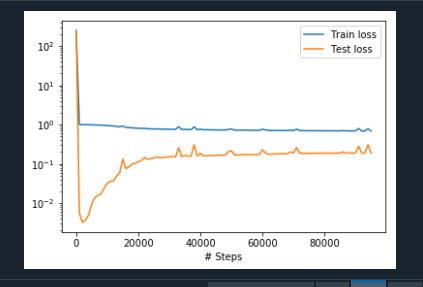
|
It is really strange why the training loss does not go down. I am not sure what is wrong here. Could you try an easier setup, e.g., smaller Rayleigh Number. |
|
Sir, Rayleigh Number is already very less ( Ra = 50), that I think very small compare to Ra = 1e4 or 1e5. I am not sure about goin beyond the Ra = 50 would effect any thing. Could you please give some alternate to deal with the coupled equation with the help of Deep Learning method. |
|
I think this problem could be solved. Is this the only problem you try to solve? What about try other similar problems in your mind first, so that we may know what is wrong here? |
|
before moving to the further problem sir. which should be, I think. |
|
I am trying to solve the similar problem, Also, the same training loss problem was occurring on simulation. Now, with the same parameters that was suggested by you, I am going to implement now, and let you know about the final result after the compilation. |
|
Dear @lululxvi Sir,
Which code script is: Unfortunately, no luck again for the training loss. It's training loss is still high and final output is not matching the other method result output.
Training values for 95k epochs.
results pattern are matching upto some extent, but their the results values are not same. Find the attached Code Script : Please comment for improving the result output value. |


|
@lululxvi Sir, |
|
Could you try larger network, exact DirichletBC, running for more iterations (e.g., one million) |
|
Dear @lululxvi Sir, Can we predict the training loss behavior after having the first 20k iteration out of one million iterations. I am asking this because of, one million iterations with your suggested combination of parameters are taking 10-11 hr to complete the training process. By getting the behavior of the first 10k iteration, I can inform you the nature of the training process. Please, comment something. |
|
No, theoretically it is almost impossible, otherwise the whole deep learning community would be happy. 10 hr seems acceptable. Neural networks are very flexible, and tuning neural networks require experience. That's why I suggest you to start from slightly simple examples. |
|
You are right @lululxvi Sir,
I have successfully solved some simple examples used DeepXDE and now, I am trying to solve some well known coupled differential equation. #107 and #84 is one among such problem. If either of the problem will have a clue for getting smaller train loss then I could solve both problem simultaneously. I'll compile the code for #84 and intimate you about the result output and training loss behaviour. Thanks |
Based on your suggestion, I have compiled the code for 100000 iterations under the mentioned parameters.
the whole iteration took almost 23hr to complete. Learning process has improved compare to the previous parameters combination.
Unfortunately, result are not close to the solution. The output result and code has attached herewith. Kindly, suggest me for the improving the training loss. (@lululxvi , @smao-astro ) |

|
Hii Dr @lululxvi Am I right about these points? kindly, help me to figure out my doubts about the above points. |
|
Yes for both questions. Also, see #39 and "Q: More details about DeepXDE source code, and want to modify DeepXDE, e.g., to use multiple GPUs and mini batch." at FAQ. |
|
Thanks for your suggestion. Also, could you clarify one more doubt,
|
|
Here are the details:
|
|
Dear Lu Sir,
say if we have two neuron at the output level, then can we access it by coding it
Thanks Sir |
|
|
Thanks Sir. If I am not wrong, can we say the normai_derivative term deal with separate data over the boundary over which that term defined to. |
|
I don't understand your question. What is |
|
I got the answer to my question. Thanks Lu Sir. |
|
@sumantkrsoni Hello, I have encountered similar problems. Have you solved them? Can you share your code conveniently? Thank you |
Hello @lululxvi ,
How can we get the desired accuracy of the output result? ( suppose for error value== 1e-8).
can we correlate Train, Test value to the accuracy of the result?
Also, how can we prevent a problem for overfitting and underfitting
The text was updated successfully, but these errors were encountered: