{kind=link}
An easy to use library to perform NLP sequence tagging tasks
Minuet is an opinionated library to perform NLP sequence tagging tasks, such as Named Entity Recognition, Part-of-Speech Tagging and Chunking, by just changing the dataset, while keeping the model untouched. Despite this, Minuet allows the user to choose which parts to use and turn off when building a new model. Think about it as a Lego library: if the goal is to fit a model quickly, you can use the default values and options, but you are also allowed to fine-tune the model hyperparameters and architecture if you wish to do so. The library was designed to be as self-contained as possible, avoiding being a black-box and allowing easy traning, disk persistence, reloading and serving. A few illustrations of these functionalities are provided on examples/ .
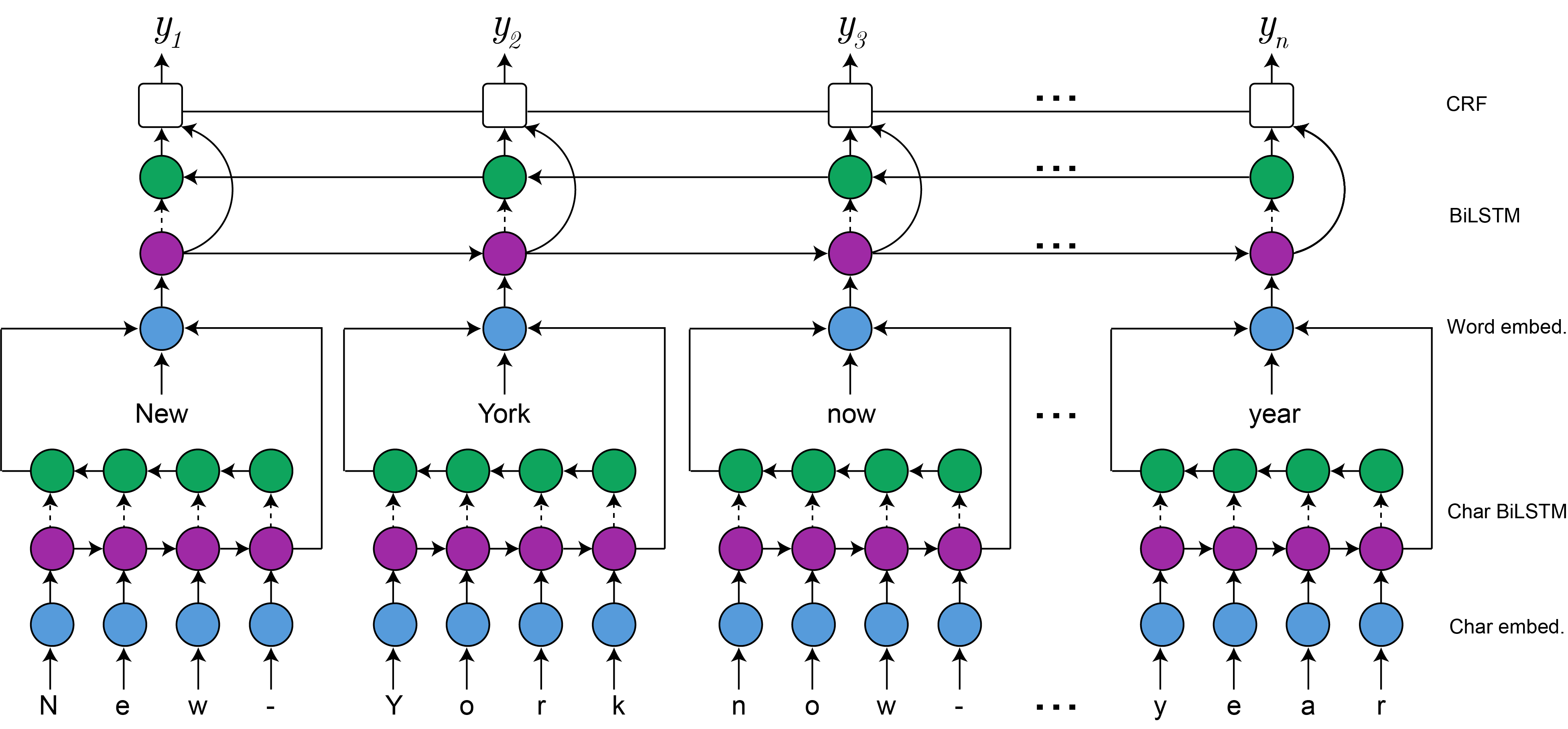
- Natural-language independent model: bring your pretrained vectors and train Minuet in your language;
- As complex as you need:
- Use bidirectional LSTMs, if you want to;
- Use CRF prediction on the output layer instead of softmax, if you want to;
- Keep the entire Vector Space Model, or just the nedded vectors, if you don't have much space;
- Use character embeddings, if you want to;
- Different preprocessing pipelines for words and characters, thus allowing you to replace messy data with tokens, but to still exploit their character-level features, if you want to;
- Portable: train a model, persist it, then restore it on a different machine, for instance, a server, for predictions.
- Easy-to-customize preprocessing pipeline;
- Supports GPU training through Keras/Tensorflow backend;
- Bundled with examples;
- Documented! 😃
To install Minuet, simply clone this repository and install it through pip with
git clone https://github.com/lzfelix/minuet.git
cd minuet && pip install .You can obtain a pretrained NER model from this link to run the example code. Just extract it on models/small_ner/. Please bear in mind that this model was trained using the default Minuet configs (unidirectional LSTM, no CRF, no character embedding, keeps only necessary word vectors), thus making it (very) weak, but also very small to download (about 18MB).
This section describes a brief usage of Minuet. The full (and more complex) code along the resulting model can be seen on examples/ner_tagging.ipynb.
-
Load the raw data, which should be in the CoNLL format: one word and label per line, tab-separated, different samples are separated by a blank line. See
data/ner/dev.txtfor a reference)from minuet import loader X_t, Y_t = loader.load_dataset('../data/ner/train.txt')
-
Define the preprocessing pipeline, which is formed by a sequence of functions applied to each word on the input sentence, as shown below:
from minuet import preprocessing as p pre_word = p.assemble( p.lower, p.replace_numbers )
You are free to either use the provided functions or to create your own, as long as they follow the signature
def fun(s: str) -> str. Notice that these functions are not suitable to perform word segmentation, which should be done as a step previous to the usage of the model. -
Encode the text labels as numbers to train the model. This step is akin to
sklearn:MAX_SENT_LEN = 10 Y_train, label_encoder = encoder.encode_labels(Y_t, MAX_SENT_LEN)
where
MAX_SENT_LENis the length of the longest sentence to be considered, smaller sentences will be properly padded usingkerasmask function, meaning that this won't impact on the cost function value, while longer sentences will be trimmed. We are planning in the future to re-release the generator training mode, which does not require padding. -
Load the pretrained word embeddings: You are free to use any model that fits your needs: word2vec, FastText, GloVe, etc, as long as they can be loaded from
gensim. We opt for this strategy in order to optimize storage requirements and loading time. GloVe can be downloaded and put on gensim format by runningembeddings/get_glove.sh.Vw = loader.get_vocabulary(X_t, pre_word) word2index, E = loader.load_embeddings(GLOVE_PATH, Vw, retain=False)
Here you can also choose to either keep the entire Vector Space Model as part of your Minuet model with
retain, or just the vectors of the words seen on the training data, thus decreasing the model size and loading time. -
Create the Minuet model, here we keep the default configs for brevity (unidirectional LSTM, softmax prediction and no character embeddings), but you are free to fiddle with these as much as you need:
from minuet import Minuet model = Minuet( word2index=word2index, pre_word=pre_word, word_embedding=E, ) model.set_checkpoint_path('../models/ner/') model.set_label_encoder(label_encoder)
-
With the supplied information, Minuet is able to process the raw training and validation data and train the model with:
in_train = model.prepare_samples(X_t, MAX_SENT_LEN) in_valid = model.prepare_samples(X_v, MAX_SENT_LEN) model.fit(in_train, Y_train, in_valid, Y_valid)
-
Finally, you are ready to go and predict on new data:
labels = model.predict(test_sentences) labels = model.decode_predictions(labels)
-
If you set the model checkpoint path and its label encoder, then it is even possible to restore Minuet on another machine (maybe a server?) to start predicting on new data. See
examples/server/pyfor an illustration.
Minuet implementation is loosely based on a paper by Lample et al. "Neural Architectures for Named Entity Recognition".
Model architecture diagram;- Improved and public tests;
- Training with generator, removing the need to pad samples;
- Benchmarks and ablation tests.