Basic Terminologies
Tree
Trees are one of the most commonly used data structures in web development. This statement holds true for both developers and users. Every web developer who has written HTML and loaded it into a web browser has created a tree, which is referred to as the Document Object Model (DOM). Every user of the Internet who has, in turn, consumed information on the Internet has received it in the form of a tree—the DOM.
A formal definition is in order.
In computer science, a tree is a widely used abstract data type (ADT)—or data structure implementing this ADT—that simulates a hierarchical tree structure, with a root value and subtrees of children with a parent node, represented as a set of linked nodes.
Each node of a tree holds its own data and pointers to other nodes.
I'll compare a tree to an organizational chart. The chart has a top-level position (root node), such as the President. Directly underneath this position are other positions, such as vice president (VP) and Chief Technology Officer (CTO) that are directly reporting to the President or are descendants (children) of the President.
To create more children (nodes) or relationships in our organizational chart, we just repeat this process—we have a node point to another node.
The top-most node (or the node with no ‘parent’ node) is called the root. The bottom-most node(s) (or nodes with no child nodes), are called leaves. Nodes with both a parent node and any child nodes are called branches as shown below:

Algorithm
An algorithm is a set of steps we apply to complete a particular task or computation.
It is basically a procedure or formula for solving a problem, based on conducting a sequence of specified actions, and which (like a map or flowchart) will lead to the sought result if followed.
Traversal
Traversal is a process or method or strategy used to visit all the nodes of a tree and may print their values too. In a
traversal, the goal is for the algorithm to visit all the nodes in the tree in some order and perform an operation on them. The most basic traversal simply enumerates the nodes so that you can see their ordering in the traversal.
There are three common ways to traverse a tree in depth-first order: in-order, pre-order and post-order.
Traversing a tree depth-first means that we’ll first visit our ‘deepest’ or ‘lowest’ nodes, or the search tree is deepened as much as possible on each child before going to the next sibling and ultimately visit our root node by backtracking

This means that in depth-first search, once we start down a path, we don’t stop until we get to the end. In other words, we traverse through one branch of a tree until we get to a leaf, and then we work our way back to the trunk of the tree.
@marvambi 👮
The order in which we visit nodes while traversing a tree is important. The order of traversal is how we classify the different traversal algorithms
We'll be specifically looking at this application for a binary search tree as:
- Read the data of the node that we’re checking or updating.
- Check the node to the left of the node (the left reference) that we’re on currently if it exist.
- Check the node to the right of the node (the left reference) that we’re on currently if it exist.
The different depth-first strategies all revolve around the order in which we do these three things.
We will be focusing on one of the strategies here, in this case, I'll dwell on pre-order strategy which is the first strategy illustrate in the image below.

- Check if the current node is empty / null.
- Display the data part of the root (or current node).
- Traverse the left subtree by recursively calling the pre-order function.
- Traverse the right subtree by recursively calling the pre-order function.
This bares itself to recursive implementation via stack. And by looking at what these nodes might look like in the context of our code, we can visualise a cross-section of a binary search tree's node below.
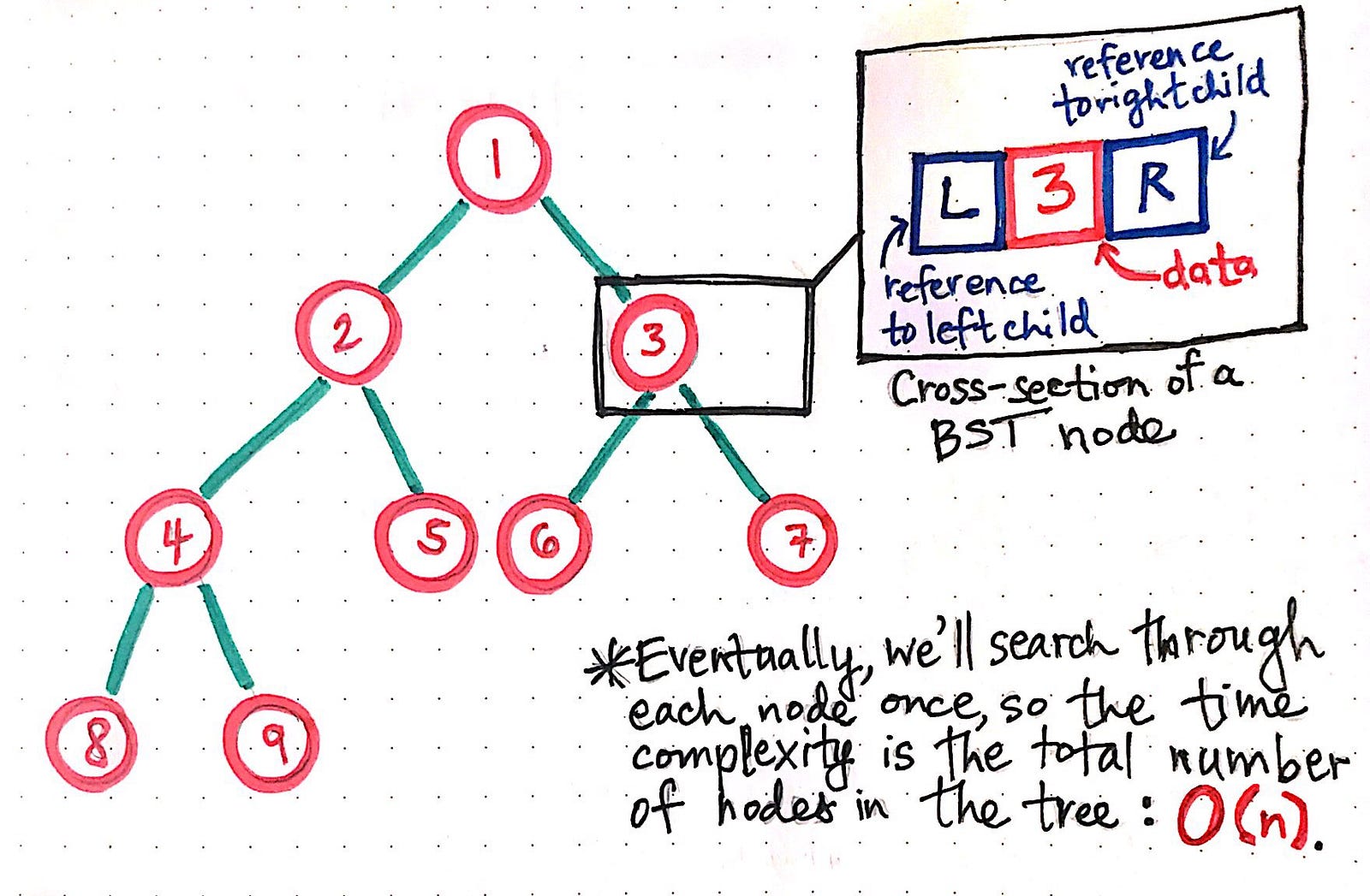
Each node has three parts — data, a left reference, and a right reference. And we can see that, we can already see one thing pretty clearly: we’re going to have to repeat the action of “reading” these three parts of a node for each node in the tree.
> Thus, the amount of time it’s going to take us to traverse through a tree using DFS is directly proportional to the number of nodes in the tree. The time complexity of using depth-first search on a binary tree is O(n), where n is the number of nodes in the tree. function preorderSearch(node) {
// Check that a node exists.
if (node === null) {
return;
}
// Print the data of the node.
console.log(node.data);
// Pass in a reference to the left child node to preorderSearch.
// Then, pass reference to the right child node to preorderSearch.
preorderSearch(node.left);
preorderSearch(node.right);
}
The image below shows the output of this pre-order algorithm applied to a 12-node binary tree:

One thing that we glimps clearly from the above is: the time complexity of depth-first search. We know that the amount of time that a DFS takes corresponds directly to how big a tree is — specifically, how many nodes it has, because that’s how many nodes we need to visit, which will directly impact how much time it will take for us to traverse the whole tree!
This is different for the space complexity as a depth-first search is usually recursively implemeted and we end up calling one function from within itself, repeatedly.
With reference to our binary tree cross-section tree, If we were implementing preorder search, we would traverse from node 1 to 2, from 2 to 4, and from node 4 to 8. Each time that we visited one of these nodes, we would be invoking the preorderSearch function from within the first function we called when we passed in the root node.
This is important because of the call stack. We know that stacks operate in with a First-In-Last-Out principle. Which means that only when the last function call finishes running and returns can we start popping functions that have currently taken up space from off of the call stack.
This is illustrated further below:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
And then each of the “open” functions in our call stack will start to return and close up, until we get back down to the first function we called to start off with. Consequently, this goes to show that the amount of space we need in terms of memory depends upon the height of our tree, or O(h). The height of the tree will tell us how much memory we’ll need in the deepest recursive function call, which will tell us the worst-case scenario for traversing a tree, depth-first.