简单爬虫框架: 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据
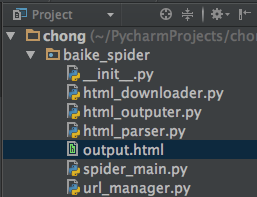
目录结构:
注:mac osx下用alt+enter添加相应方法
- (爬虫调度器)spider_main.py
- (url管理器)url_manager.py
- (下载器)html_downloader.py
- (解析器)html_parser.py
- (数据输出)html_outputer.py
运行程序spider_main.py可进行爬取页面,最终文件输出为output.html,里面包含词条和词条解释,爬取完毕。
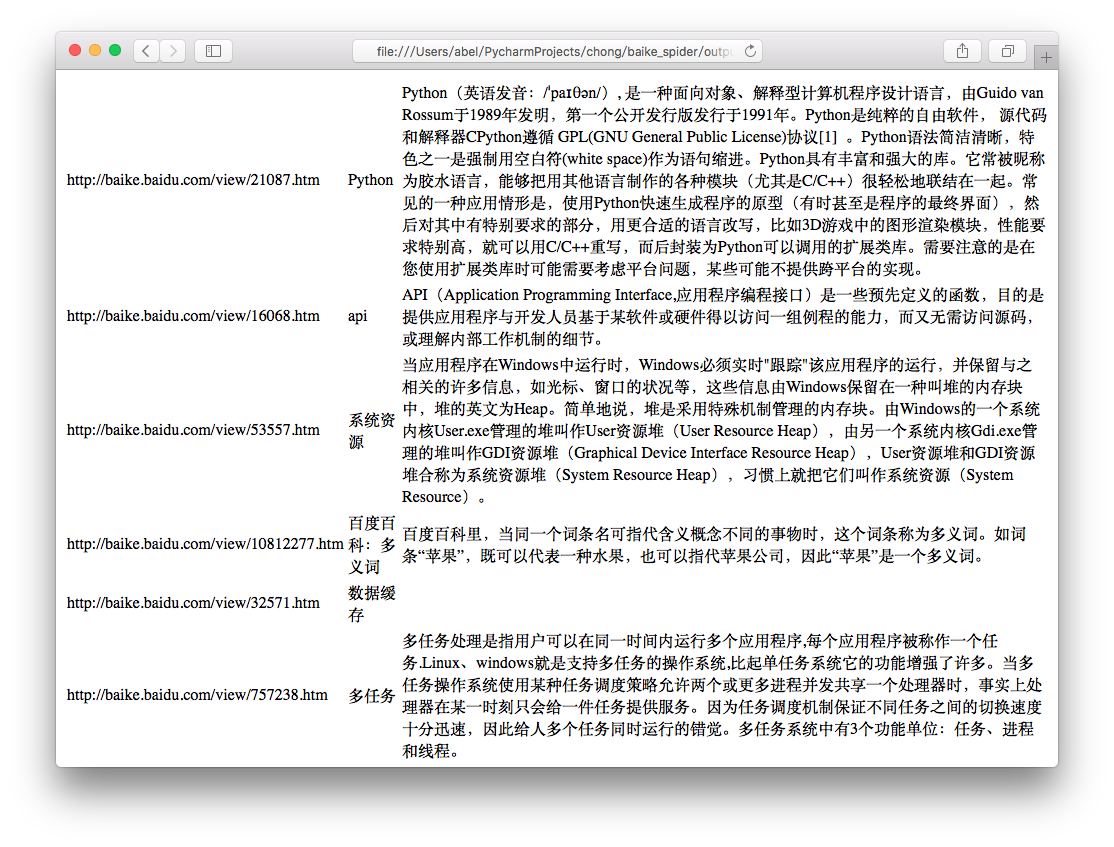
output.html: