A trend starts from "Chain of Thought Prompting Elicits Reasoning in Large Language Models".
-
🚩 Chain of Thought Prompting Elicits Reasoning in Large Language Models. [pdf] 2022.1
-
Self-Consistency Improves Chain of Thought Reasoning in Language Models. [pdf] 2022.3
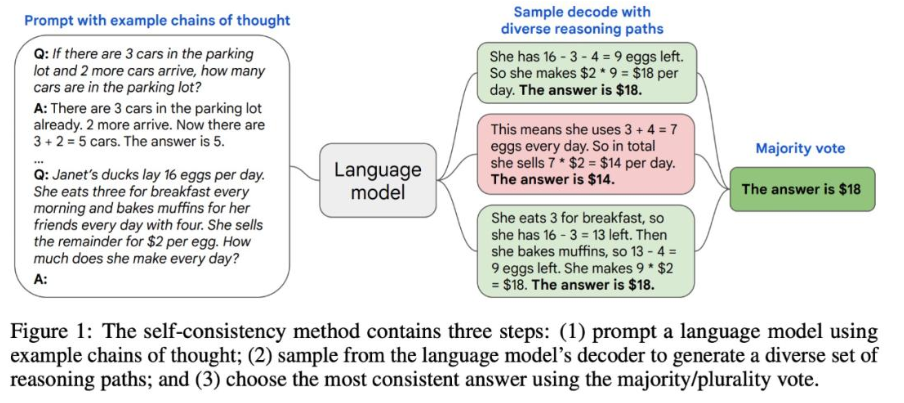
简单的来说,LLM在面对一个推理问题时,可能采用多种推理路径,这些推理路径可以被分为两个集合——正确的路径和不正确的,而对于正确路径的集合,他们的最终答案都是一样的,也就是说这个答案是自洽的(self-consistency)。
不同的推理路径如何获得?采样。首先使用带有例子的prompt输入进LLM中,再从结果中进行采样,最终获得最自洽的答案。
本质来说,这一研究模拟的是人类不同的思维方式。把带有不同例子的prompt输入进LLM的过程,就好比把学霸的解题思路告诉学渣,当学渣想套用这个思路的时候,学渣可能没法一次性做对,就需要多次尝试生成自己的解题思路,从这些思路中多次采样,学渣会获得多个解题方法以及对应的答案,选择一个最自洽的作为最终答案。
知乎回答:SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS - 知乎 (zhihu.com)
-
STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning. [pdf] 2022.3
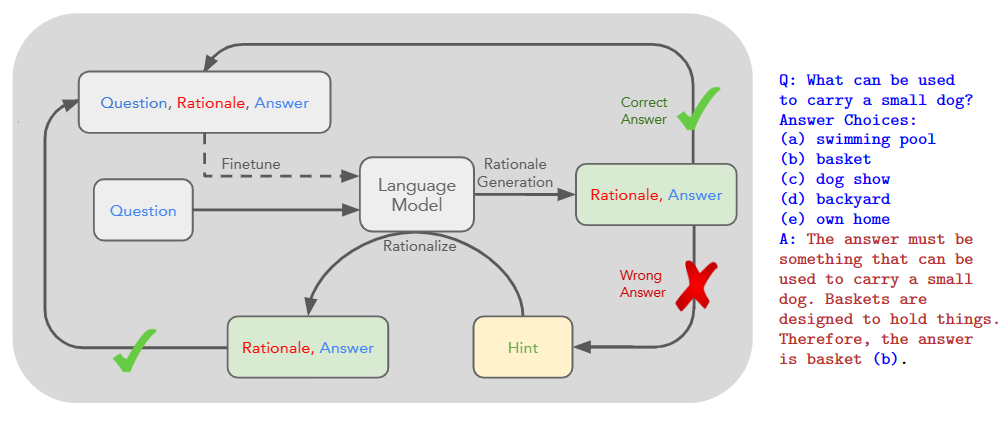
提出了一种用于迭代性微调LLM的方法,方法是使用一种类似数据增强的手段生成一个数据集,再使用该数据集微调模型:对于一个问题,把它输入LLM之后,1)如果答案正确,则将其加入到数据集中,2)如果答案不正确,则把正确答案作为提示告诉他,再让他以此为提示生成一个答案,再把该答案加入数据集中,之后使用该数据集微调模型,并且还能够不断重复这一过程达到迭代优化的效果。这一过程(技术)叫做STaR,伪代码如下:

-
PaLM: Scaling Language Modeling with Pathways. [pdf] 2022.4
-
Can language models learn from explanations in context?. [pdf] 2022.4
使用带解释的输入去检验解释能否提高大语言模型的few-shot learning能力
-
Inferring Implicit Relations with Language Models. [pdf] 2022.4
评估了LLM推断主问题中的隐含子问题的能力。
-
The Unreliability of Explanations in Few-Shot In-Context Learning. [pdf] 2022.5
虽然使用解释性提示可以帮助LLM生成更好的推理结果,但是LLM自己生成的解释未必是可靠能用的,而且大多数不可靠的解释都会导致错误的预测结果(unreliable explanation 和 incorrect prediction 之间存在某种连接),因此这篇文章使用可以近似解释的可靠性的特征,来判断LLM的预测的解释性是否可靠,进而判断LLM的预测是否正确。最终提高了LLM模型在上下文学习中的表现。
-
🚩 Large Language Models are Zero-Shot Reasoners. [pdf] 2022.5
著名的Let‘s think step by step
-
🚩Least-to-Most Prompting Enables Complex Reasoning in Large Language Models.[pdf] 2022.5
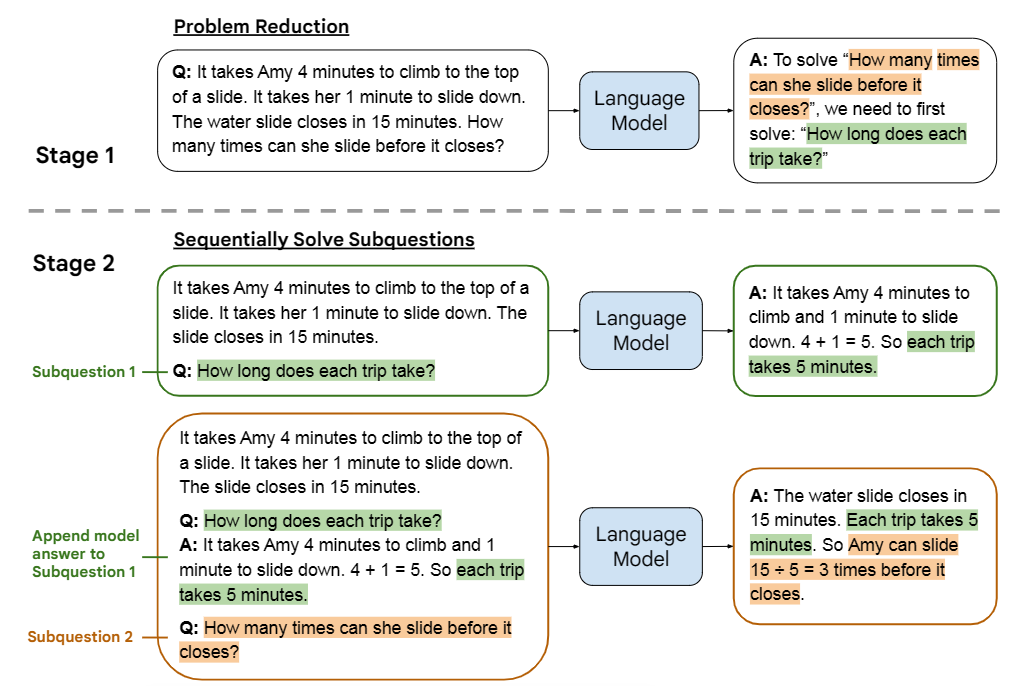
这篇文章的思路来自于教育心理学的理论:教学生学习新技能时,老师们一般会使用循序渐进的提示序列。对LLM也是同理,我们可以先教他拆解问题,再一个一个地解决拆解后的子问题(阶段一:Problem reduction;阶段二:Sequentially solve subquestions)。
For example:假设要解决的问题为target-question,人为构造一道例题B,例题拆解后的子问题序列{$b_1,b_2,b_3...$}。
第一阶段Prompt:
Q:{B} A:To answer the question "{B}". We need to know:"{b1}","{b2}","{b3}"... Q:{target-question}第一阶段LLM输出:
A: To answer the question "{target-question}". We need to know: "{q1}","{q2}","{q3}"...第二阶段Prompt:
prompt1:
target-question Q:{q1}LLM's answer:answer1
prompt2:
target-question Q:{q1} A:{answer1} Q:{q2}LLM's answer:answer2
prompt3:
target-question Q:{q1} A:{answer1} Q:{q2} A:{answer2} Q:{q3}……
Last prompt:
target-question Q:{q1} A:{answer1} Q:{q2} A:{answer2} Q:{q3} A:{answer3} ... Q:{target-question}LLM's output is the final answer we want.
这篇工作在最后的CONCLUSION AND DISCUSSION部分提出了几点思考,个人感觉很有道理,摘抄在这里:
- 不是所有的问题都能通过最小到最大的提示来解决。有些问题可能无法简化,或者至少不容易简化。例如,一个可以用变量和方程解决的数学应用题可能没有那么明显,可以在一个算术操作步骤内简化为子问题。在这种情况下,可能的解决方法是首先对语言模型进行微调,使其了解变量和方程。如何有效地结合激励和微调应该是一个迷人的探索方向。
- 最小到最多提示的另一个限制来自于其基于自然语言的解决方案构造。自然语言具有表现力和通用性,但往往不如计算机语言精确。例如,一个学习过的计算机程序可能能够解决任意长度的符号操作任务,准确率为100%。因此,我们可以在提示中结合自然语言和计算机语言,使它们更强大。这就像写一个数学证明,既需要自然语言文本,也需要基于抽象符号的方程。在构造用于求解SCAN的提示符中,我们实际上同时使用了自然语言和Python符号。
- 最后,提示可能不是让大型语言模型进行推理的最佳方式。我们可以把提示看作是一种单向的交流:教一种语言模型新的技能,而不考虑它的反应。将提示扩展到完全的双向对话应该是很自然的,这将使我们能够为语言模型提供即时反馈,从而使它们能够更好或更快地学习。从最小到最多提示可以被认为是通过双向对话教授语言模型的一步。
-
Selection-Inference: Exploiting Large Language Models for Interpretable Logical Reasoning. [pdf] 2022.5
主要是为了解决LLM在多步骤逻辑推理问题上表现不佳的问题,作者提出了一种选择-推理交互进行的CoT框架,利用预先训练的LLM作为通用处理模块,并在选择和推理之间交替,以生成一系列可解释的、随意的推理步骤,从而得出最终答案。
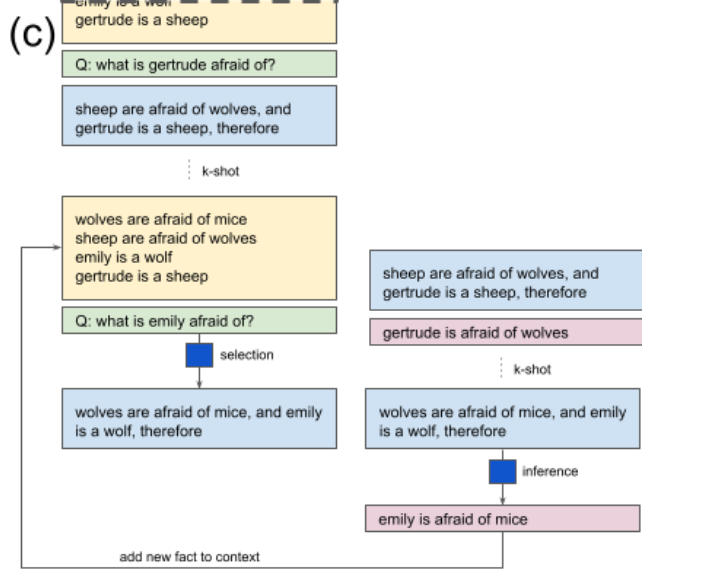
具体来说,selection模块负责从few-shot prompt中选择出和question相关的信息,inference模块负责为选择出的信息推理出新的fact,假如这个fact不是最终问题需要的final-answer,就把新的fact加入到context中,重复之前的步骤,直到inference模块生成了可以直接回答最终问题的答案。
-
On the Advance of Making Language Models Better Reasoners. [pdf] 2022.6
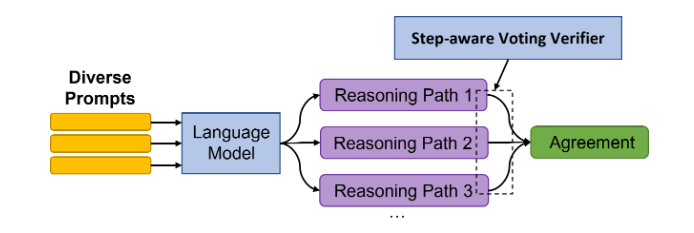
这篇可以配合第2篇一起看,第2篇主要是引导语言模型在产生最终答案之前生成一系列推理步骤,并使用self-consistency机制获得较好的结果。在这种思路的基础上,这篇研究沿用了这种“条条大路通罗马”的思路,并且更侧重多元性(多元性的prompt -> 多元性的推理步骤 -> 多元性的答案)
除了多元性,这个工作还有两个关键创新:
- 生成推理路径时,普通的语言模型无法修正那些由前馈步骤生成的错误答案,因此在整合所有路径的答案时,他们设计了一个投票验证器,来为每个推理路径的最终结果打分。
- 另外,对于一个生成了正确答案的推理路径,我们总是假设其路径上的所有步骤都是正向的。但是对那些生成了错误答案的路径,其路径上的所有步骤未必都是错的,比如前两步很正确,但由于第三步生成了错误答案,导致了最终的错误。因此,他们设计了一种机制,为每个步骤分配细粒度标签,并提出了一个步长感知验证器,并将正确值的打分分配给每个步骤。
多元性prompt如何实现的:
为每个问题提供M1个不同的提示,然后对于每个prompt采样M2个推理路径。因此,每个问题取了M = M1 × M2条不同的推理路径。如何生成M1个不同的提示?如果有一个范例集E,那么每次我都从E中采样K个范例组成一个prompt,采样M1次,最终就构成了M1个不同的prompt。
Voting verifier如何实现:
目标函数:f(xi,zi,yi),其中x_i表示第i个问题,z_i表示LLM生成的推理路径,y_i表示该路径的答案。f(·)就是verifier。为了训练这个verifier,我们可以使用范例集E。对于E中的每个(\bar{x},\bar{z},\bar{y}),让LLM生成一系列推理路径和答案(z1,y1),(z2,y2)...(zm,ym),对于那些yi = \bar{y}的数据,就把<(\bar{x},zi,yi),1>加入训练集D,否则把<(\bar{x},zi,yi),0>加入训练集D。之后使用二元交叉熵损失函数训练verifier: $$ L_0=\sum^{|D|}{i=1}BCE(label_i,f(input_i)) $$ verifier训练好之后,就可以使用下面这个公式获得最优路径和最优解: $$ \hat{y}=argmax{y}\sum^M_{i=1}1_{y_i=y}f(x_i,z_i,y_i) $$ 步进策略如何实现:
对于一个错误的答案,由于其路径上的步骤未必都错误,因此这篇工作实现了一个步长感知器
——Step-aware voting verifier
为了实现这个感知器,首先要将损失函数扩展成如下形式: $$ L = L_0+\alpha L_1\ L_1 = \sum^{|D|}{i=1}\sum^{|S_i|}{j=1}BCE(label_{i,j},f(input_i,j)) $$ α是超参数,$S_{i,1},S_{i,2}...S_{i,|S_i|}$是$z_i$路径上的各步骤,$label_{i,j}$代表$S_{i,j}$是否正确,$f(input_i,j)$表示$S_{i,j}$正确的可能性。
至于如何获得$Label_{i,j}$,可以使用一种交叉验证的方法,简单点说就是从别的例子中找support,比如$S_{i,1}...S_{i,j}$可能是“大锤80,所以小锤40”,假设我们不知道这个推理路径是不是正确的,但是我们知道有另外一个完整且正确的推理路径是“大锤80,所以小锤40,所以一共120”,由于后者包含了前者,所以$S_{i,j}=1$
原文中更严谨的描述:
A critical issue is how to get the step-level labels (i.e.,
$label_{i,j}$ ) for negative training data with wrong answers. We propose to address this issue through a "cross-validation" method. Figure 3 demonstrates an example of this idea. Concretely:$label_{i,j}$ = 1 if and only if ∃1 ≤ k ≤ |$\hat{D}$ |(k$\not =$ i)and c ≥ j, s.t.$label_k$ = 1 and$S_{k,1}, ..., S_{k,c}$ "supports"$S_{i,1}, ..., S_{i,c}$ . In different tasks, "supports" can be defined differently: for arithmetic tasks, it means the set of intermediate results of$S_{k,1}, ..., S_{k,c}$ is the same as that of$S_{i,1}, ..., S_{i,c}$ ; for other tasks, it means: ∀1 ≤ r ≤ c,$S_{k,r}$ and$S_{i,r}$ are semantically equivalent 5. -
Emergent Abilities of Large Language Models. [pdf] 2022.6
讨论了大语言模型涌现的新能力,所谓量变引发质变,语言模型的scale up不只是提高了一两个点的指标, 而是发生了质变,突变式地拥有了小语言模型所不具有的新能力,这才是scale up的意义所在。
论文关注的涌现能力是模型的prompting(in-context learning)能力,最终获得了结论:prompting相关的能力是随着模型规模的增大而涌现的。
一篇总结性的文章吧,提出了一些量化方法和指标。
-
Minerva: Solving Quantitative Reasoning Problems with Language Models. [blog] 2022.6
通过大量收集相关的训练数据并做大规模预训练,训练出了可以逐步推理解决数学和科学问题的的AI——Minerva。
性能提升来自3个方面:合理的数据+大规模训练+合适的inference技术。
这个....不太好复现,遂作罢。
-
JiuZhang: A Chinese Pre-trained Language Model for Mathematical Problem Understanding. [pdf] 2022.6
九章:一个使用中文语料库训练的数学题解预训练模型。
-
A Dataset and Benchmark for Automatically Answering and Generating Machine Learning Final Exams [pdf] 2022.6
-
Rationale-Augmented Ensembles in Language Models. [pdf] 2022.7
证明了那些带理由的few-shot prompt(输入、理由→输出),受制于可能损害性能的次优原理。因此,提出了一种统一的理由增强集成框架,通过聚合由语言模型生成的多个基本原理,将输出空间的推理路径采样确定为稳健提高性能的关键组件。
-
Language Model Cascades. [pdf] 2022.7
-
Text and Patterns: For Effective Chain of Thought, It Takes Two to Tango. [pdf] 2022.9
这篇文章把CoT中的thought分成了三个组成部分——symbol,pattern和text。
- symbol指的是thought中的数值、人名、日期等关键的信息序列。
- pattern指的是符号和操作符的组合,或者是加强任务理解的提示符结构。
- text就是剩余的字符串
在实验部分,研究者把数据集中正确的thought,强制的改编成了违反常理的thought,并作为prompt中的示例输入进LLM中,观察其结果变化。并且在这一过程中,还使用了控制变量的思想,比如我要探究symbols对于CoT的作用,那我就在改编时只改symbols,比如用未知数替代常数,用不存在的日期替代示例中的日期等等。
最终,实验发现:
- prompt中的symbol的实际上并不影响模型的性能。
- patterns可能是最决定prompt性能的关键
- 最重要的是,文本和模式形成了一种共生关系,在COT的成功中起着至关重要的作用。文本有助于生成有用的模式(例如,通过提取常识性知识),而模式有助于加强任务理解,使语言模型能够生成有助于解决任务的文本。总的来说,研究认为COT成功背后的主要原因之一是文本和模式之间的相互作用——COT帮助语言模型模仿提示并为任务生成正确的标记。
这篇文章更有价值的地方我觉得在于:从symbol、text、pattern三个要素拆解了prompt这个很抽象很主观的东西,并且提供了很多会降低CoT性能的例子,之后做研究的时候可以先调研一下这篇文章,看看什么样的prompt是需要避免的。
-
Compositional Semantic Parsing with Large Language Models. [pdf] 2022.9

这篇得配合着第9篇Least-to-most prompting一起看,回看Least-to-most这篇文章,其prompt的第一个stage是通过几个示例教会LLM把问题拆解出来,之后再去一步步的解决拆解后的问题。但是拆解问题其实是很难通过几个例子就教会的,尤其对于复杂问题,我们要为LLM设计一个拆解问题的流程,这就是Compositional Semantic Parsing with Large Language Models这篇文章要解决的问题。作者提出了以下三个solution:
-
对于待解决的问题,首先通过LM语法解析进行分解,将其构造成一颗语法树。具体的构造方法分为五步:
- Noun phrase identification
- Subclause identification
- Verb and other phrase identification
- Part-of-speech tagging and phrase labeling
- Verb normalization
ps:语法树的生成也是使用CoT生成的,无需编写额外程序,因为我们相信大语言模型在预训练最先学习到的就是语法解析的技能。
-
作者人为的从训练集中精心挑选了一些问题&问题的拆解思路,同时也为这些问题构造了语法树,这些样例树就构成了一个候选者池。所以当LLM需要解决问题A的时候,我们可以先动态的从候选者池中匹配那些和A语法树结构很相似的样例树,以及样例树对应的问题&问题的拆解思路。用这个问题和问题的拆解思路作为prompt,可以更有针对性的教会模型如何拆解问题
-
使用和least-to-most类似的Sequentially solve subquestions阶段解决问题
-
-
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning. [pdf] 2022.9
文章构建了一种半结构化的数学应用题数据集,同时提出了一种自动选取 Chain-of-Thought 示例的方法。
一方面,本文在纯文本数学应用题求解的基础上进行扩展,提出了半结构化的数学应用题数据集 TabMWP。该数据集的每个样本包含一段表格上下文和问题,其中表格上下文可能是图像、半结构化文本或者表格。
另一方面,Chain-of-Thought 的示例通常是人工选取或随机选取,可能会导致 PLM 的性能不稳定。为了解决这个问题,本文提出通过策略梯度来从训练集中选取示例的方法,用于选择适合当前问题的示例。
-
Language Models are Multilingual Chain-of-Thought Reasoners. [pdf] 2022.10
评估了大型语言模型在多语言环境中的推理能力。通过将GSM8K数据集(Cobbe等人,2021年)中的250个小学数学问题手动翻译成10种不同类型的语言,引入多语言小学数学(MGSM)基准。作者发现,通过思维链提示解决MGSM问题的能力随着模型规模的增加而出现,而且模型具有惊人的强大的多语言推理能力,甚至在孟加拉语和斯瓦希里语等代表不足的语言中也是如此。最后,作者表明,语言模型的多语言推理能力延伸到其他任务,如常识推理和上下文语义判断。
-
Automatic Chain of Thought Prompting in Large Language Models. [pdf] 2022.10
沐神的文章,非常大道至简的一个工作:这个工作是在manual-CoT的基础上改进的,大致意思就是往prompt中插入示例时,我不插入由人工生成的示例,而是用语言模型自动生成的模板示例,然后让LLM去think step by step。最终效果也是优于人工示例的,也是非常amazing。
-
Binding Language Models in Symbolic Languages. [pdf] 2022.10
一种无需训练的神经符号框架,将任务输入映射到程序。实现了LM和编程语言之间的连接:
- 将LM的统一API接口绑定至编程语言中,扩展了语法的覆盖范围并解决不同的问题
- 采用LM作为程序解析器和API在执行期间调用的底层模型
- 只需要少量上下文内示例注释
-
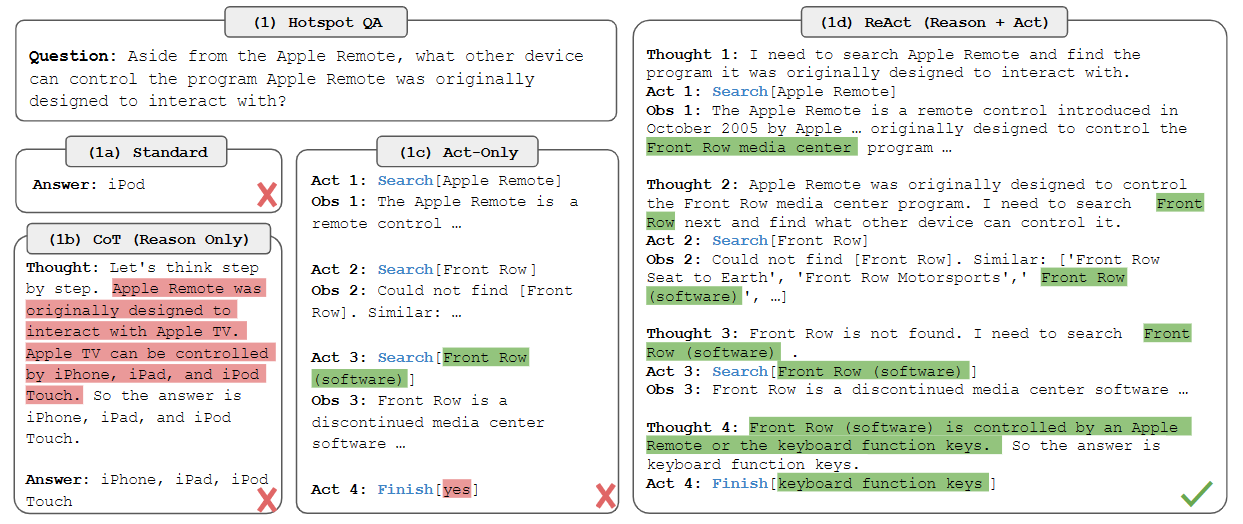
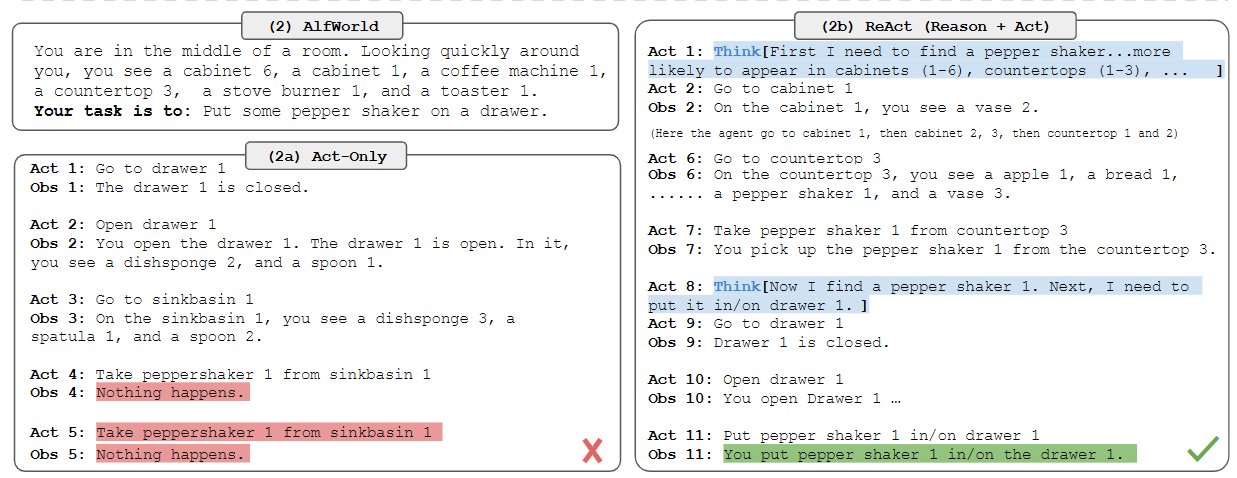
ReAct: Synergizing Reasoning and Acting in Language Models. [pdf] 2022.10
这项工作:1)引入了ReAct,一种新的基于提示的范式,用于在一般任务求解的语言模型中协同(跟踪)推理和行为;2)在不同的基准上进行了大量的实验,以展示ReAct在few-shot learning中的优势,而不是先前单独执行推理或动作生成的方法;3)设计了一些消融实验,以理解行为在推理任务中的重要性,以及推理在交互式任务中的重要性;4)分析了ReAct的劣势
ReAct提示llm以交错的方式生成与任务相关的口头推理跟踪和操作,这允许模型执行动态推理,以创建、维护和调整高级行动计划(行动的理由),同时还与外部环境(例如维基百科)交互,将额外的信息纳入推理(行动到理由)。
-
Ask Me Anything: A simple strategy for prompting language models. [pdf], [code] 2022.10
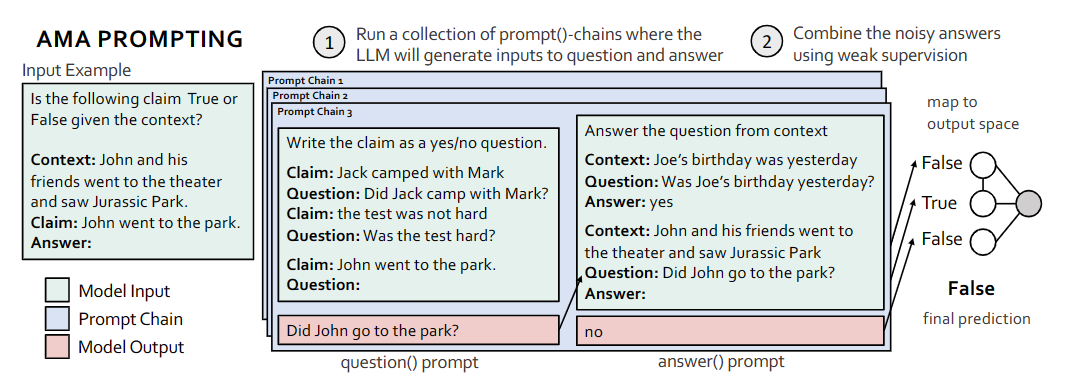
这篇工作的motivation是作者发现对于question-answer(QA) prompts 来说,开放式的prompt(比如:Who went to the park?)相较于限制式的prompt来说(比如:John went to the park. Output True or False)效果更好。并且构造一个很完善的(这里的完善可以理解成包含了多角度、细节丰富的上下文)prompt是很耗时耗力的,因此作者提出了一种聚合多个有效但不完善的提示的预测方法,以提高在广泛的模型和任务中的提示性能。
具体的实现方法就如上图所示,对于每个prompt chain,都包含两个部分,首先是用多个claim-question构成的question prompt,旨在引导模型输出一个开放式问题。其次是一个多个context-question-answer构成的 answer prompt,旨在引导模型回答上一阶段生成的开放式问题。这样的prompt chain一共有多个,最后连接一个投票器,从而获得最终的结果。
-
Language Models of Code are Few-Shot Commonsense Learners. [pdf], [code] 2022.10
-
Large Language Models Can Self-Improve. [pdf] 2022.10
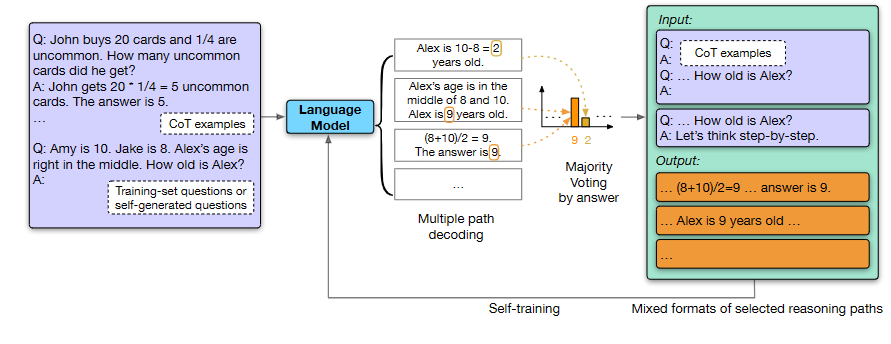
这项工作探究了LLM的自我迭代性能,证明了LLM也能够仅使用未标记的数据集进行自我改进:先使用预先训练过的LLM,使用思维链提示和自一致性为未标记的问题生成“高置信”的理性增强答案,并使用这些自生成的解决方案作为目标输出对LLM进行fine-tuning。
具体的实现方法也是涉及到了很多之前的经典文章:
-
首先把CoT格式的prompt(上图紫色框)输入LLM中,获得多个推理路径,然后使用第2篇文章中的self-confidence机制选择最优的推理路径。
-
第二步是数据增强,即使用上一步LLM自生成的最优推理路径(答案)构造一个用于fine-tuning的数据。同时为了防止过拟合,我们希望用于fine-tuning的数据中不止包含CoT格式的输入输出,还要包含那些朴素直白的回答,具体构造方法如下图所示。

-
使用增强后的数据重新构造prompt和question,再输入到LLM中微调,达到模型自我迭代升级的效果。生成question的方法
-
-
Large Language Models are few(1)-shot Table Reasoners. Wenhu Chen [pdf] 2022.10
探究了LLM模型在表格信息上的few-shot learning能力。
-
PAL: Program-aided Language Models. [pdf] 2022.11
把CoT写成了python代码的形式

-
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks. [pdf] 2022.11
提出了 Program of Thoughts (PoT),它使用语言模型(主要是Codex)来生成文本和编程语言语句,并最终得到答案
-
(综述) Reasoning with Language Model Prompting: A Survey. [pdf] 2022.12
-
(综述) Towards Reasoning in Large Language Models: A Survey. [pdf] 2022.12
-
Large Language Models are reasoners with Self-Verification. [pdf] [code] 2022.12
和第11篇类似,也是先通过生成多个候选路径,之后使用一个验证器选择分数最高的结果。不过这篇工作的研究重点在于使用LLM本身去当验证器,而不使用其他的特征算法。作者也是成功证明了LLM可以对自己的结论进行可解释的自我验证,并实现竞争推理性能。
具体实现过程如下图所示:
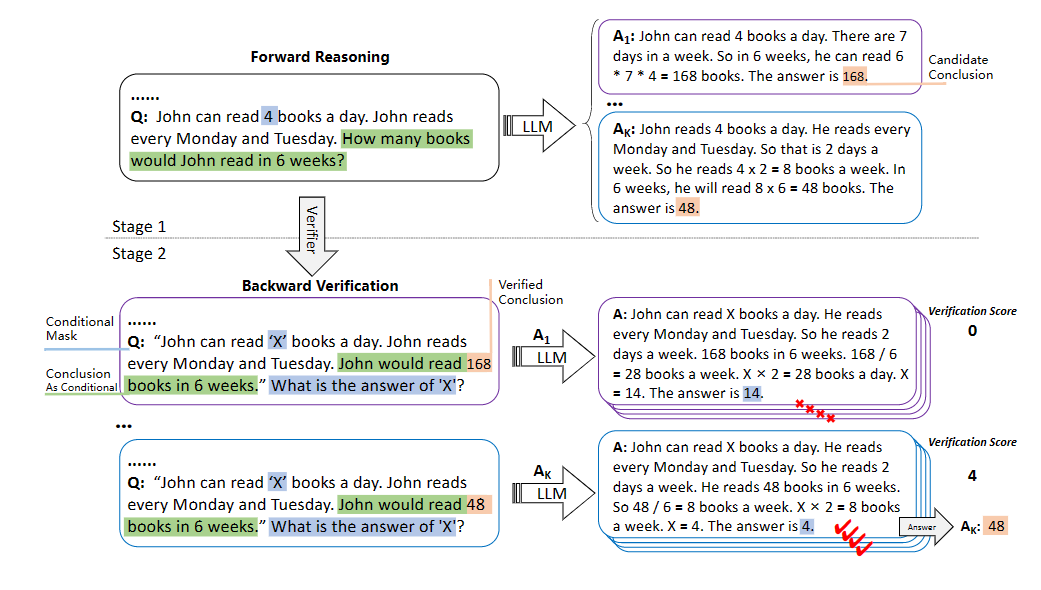
第一阶段和之前的方法没什么不同,主要是第二阶段使用LLM本身做验证器去为候选路径生成评分这里,如何定义“评分”任务是最关键的。作者采用的思路是,使用LLM生成的答案回推给定的条件,如果回推的结果一致,则说明LLM生成的答案是可信的(高分的)。
因此就需要对第一阶段LLM生成的答案进行变形。举例来说,第一阶段LLM对于问题“How many books would John read in 6 weeks?”生成的完整回答是:“John reads 4 books a day. So.....The answer is 48.”。那么在第二阶段,我们需要先把问题q和回答y进行一个组合,“让回答成为条件的一部分”。我们会向LLM输入以下命令:“Please change the questions and answers into complete declarative sentences [q] The answer is [y]”,不难想象,LLM的输出应该是“John would read 48 books in 6 week”类似的回答,我们把这个回答替代第一阶段结果中的“The answer is 48”。就得到了一段陈述性文本。
之后我们在把原始条件中的某个值隐去(X)$\rightarrow$最后追加一个“What is the answer of X”$\rightarrow$输入进LLM中$\rightarrow$获得答案$\rightarrow$把答案与原条件值比对,获得分数。
-
Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters. [pdf] [code] 2022.12
似乎即便在prompt中加入不真实的推理路径,LLM生成的结果仍能保证较高的正确率,因此文章探究了有效的推理到底有多重要。结论是:1)推理的有效性只占表演的一小部分;2)与输入查询的相关性以及推理步骤中的顺序才是CoT提示有效性的关键
-
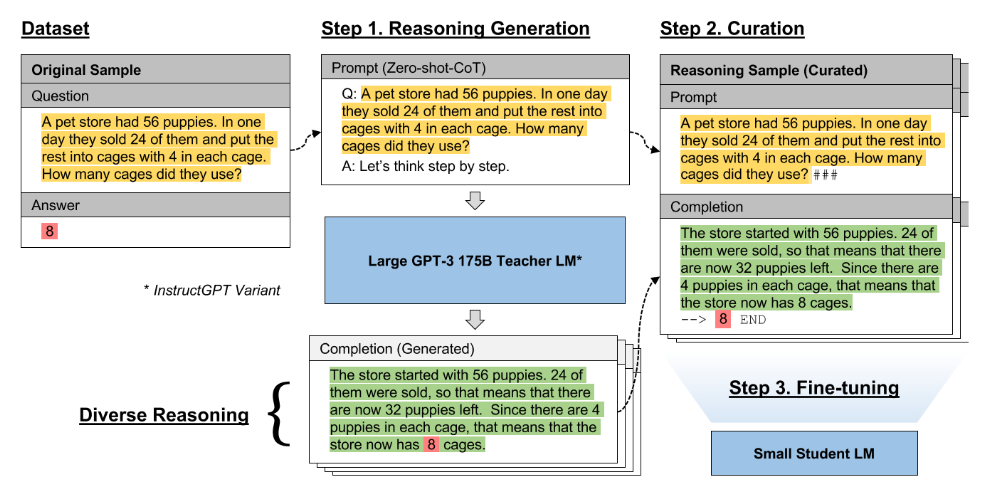
Large Language Models Are Reasoning Teachers. [pdf] 2022.12
用CoT和LLM生成的结果去fine-tuning小型的语言模型,研究结果表明该方法显著提高了小模型在一系列不同任务上的表现,并且具有较高的样本效率,在许多情况下甚至可以达到或超过教师的表现。
-
Large Language Models are Versatile Decomposers: Decompose Evidence and Questions for Table-based Reasoning [pdf] 2023.02
以前的基于表的推理解决方案通常会在大量证据(表)上遭受显著的性能下降。此外,大多数现有的方法难以推理复杂的问题,因为所需的信息分散在不同的地方。为了缓解上述挑战,我们利用大型语言模型(LLMs)作为有效的基于表的推理的分解器,它(1)将巨大的证据(一个巨大的表)分解为子证据(一个小的表),以减轻无用信息对表推理的干扰;以及(2)将复杂问题分解为更简单的子问题进行文本推理。具体来说,我们首先使用llm来分解当前问题涉及的证据(表格),保留相关的证据,并从庞大的表格中排除其余不相关的证据。此外,我们提出了一种“解析-执行-填充”策略,通过在每一步中解耦逻辑和数值计算来缓解思维链的幻觉困境。
-
Multimodal Chain-of-Thought Reasoning in Language Models [pdf] 2023.02
一项关于多模态思维链的工作,作者在《Universal Multimodal Representation for Language Understanding》的基础上,通过融合多模态的特征去fine-tune LLM(不是prompt)。并且这项工作还有一点比较亮眼:Multimodal-CoT这个模型只用了10亿个参数,就比之前最先进的LLM (GPT-3.5)高出16个百分点(75.17%→91.68%的精度),甚至超过了ScienceQA基准测试中的人类表现。

在实验部分,作者先尝试了仅使用text模态的数据去微调一个$UnifiedQA_{BASE}$模型。这个任务被建模为一个文本生成问题,其中模型将文本信息作为输入,并生成由基本原理和答案组成的输出序列。结果发现单模态下CoT并不能提升模型性能。通过错误归因,发现64%的推理不能得到正确结果,是由于视觉特征缺失。比如上图中,由于缺失了Vision维度的特征,模型会得出一个磁铁的S端离另一个磁铁的S端更近的情况。但添加了视觉特征就能修正回正确结果。
因此,现在要做的就是:1)把视觉特征和language特征融合$\rightarrow$2)输入到decoder生成新的文本$\rightarrow$3)输入到模型中获得CoT推理和答案;
第一步中,研究使用Transformer获得language特征,使用DETR获得视觉特征,然后使用投影矩阵将二者维度统一并拼接。
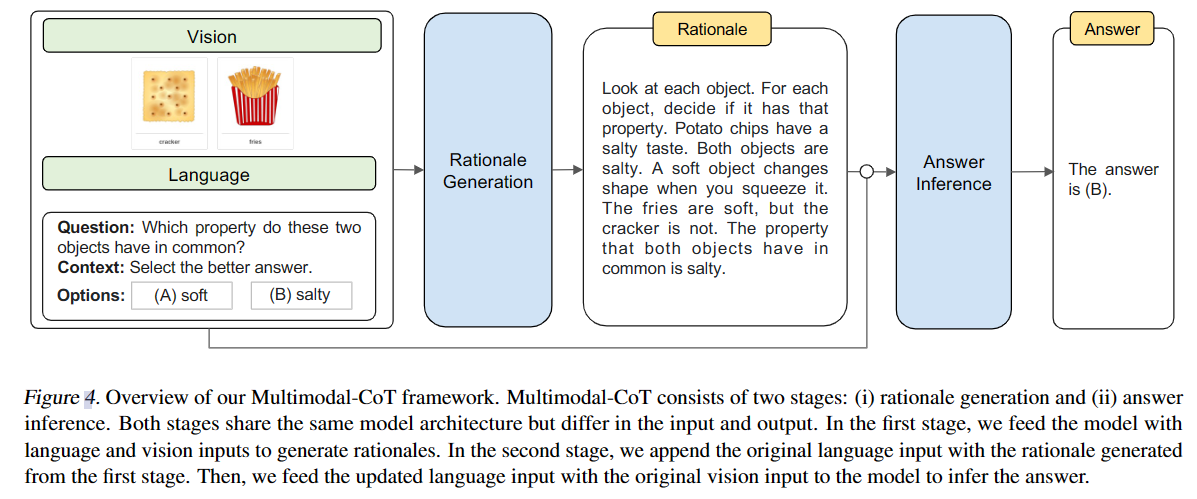
第三步的模型使用了上图所示的pipeline,这是一个两阶段的框架,之所以设计成两阶段的,是因为这并不是一个大规模语言模型,其参数量为1 billion,但是据之前的研究,LM参数越少,其胡诌的可能性也越大,这一现象被称为hallucination(幻觉),所以为了在小模型上克服hallucination,作者把模型设计成了“推理”和“定论”两阶段分离的结构。论文说,这是因为他们在做text单模态推理时发现,如果在生成答案之前生成推理,会造成性能的下降,这可能是因为tokens长度的限制导致了模型过早生成答案,因此采用两阶段分离的设计也许能够摆脱这种情况的干扰。
下图是Multimodal-CoT的完整伪代码。

-
Large Language Models Can Be Easily Distracted by Irrelevant Context [pdf] 2023.02
在之前的CoT研究中,研究者提供给LLM的prompt中,question的所有信息都与问题解决方案相关,就像考试中的问题一样。这与现实世界的情况不同,在现实世界中,问题通常伴随着几条与上下文相关的信息,这些信息可能与我们想要解决的问题相关,也可能不相关。在解决这些问题时,我们必须确定哪些信息是真正必要的。
所以作者主要研究了大型语言模型在各种提示技术中的distractibility(分散性),提出了一个数据集GSM-IC,支持在不相关的上下文中执行算术推理时对大型语言模型的分散性进行全面研究。在这个数据集上,作者研究了各种提示技术,并证明它们都对问题中的不相关信息敏感。在所研究的技术中,自一致性(Wang et al., 2022c)导致了对不相关上下文的鲁棒性的全面大幅提高,并且在提示中呈现不相关上下文的示例问题也始终提高了性能。类似地,我们发现只需添加一条忽略不相关信息的指令,就能在基准测试中带来显著的性能提升。
-
Active Prompting with Chain-of-Thought for Large Language Models [pdf] 2023.02
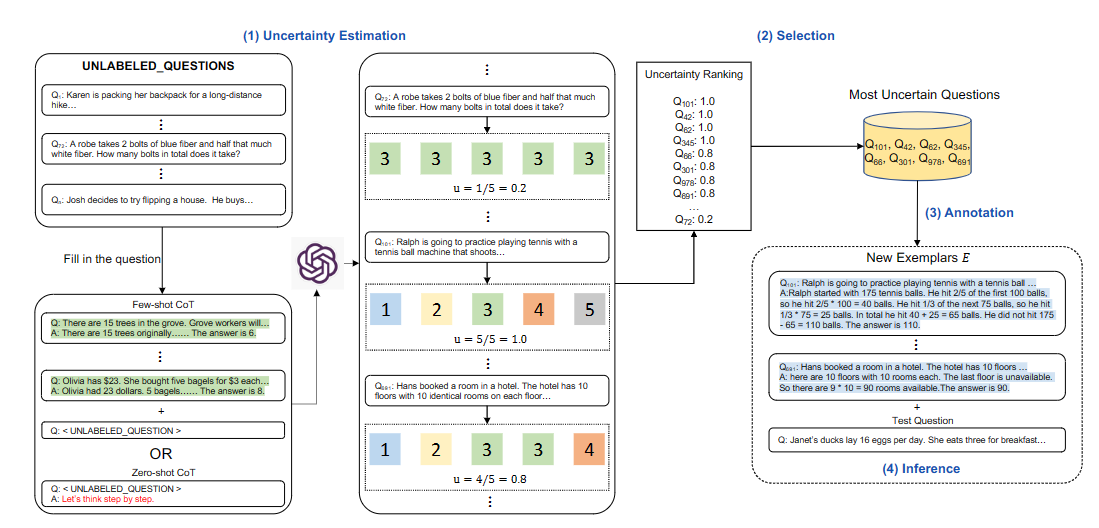
原始的思维链工作中,我们往prompt中添加的例子要么是从训练集中随机选择的,要么是人工手动编写的,但是由于推理任务的性质在难度、范围、领域等方面存在显著差异,我们不知道什么样的问题最值得注释。同样不清楚的是,一组特定的范例是否能最好地引出所需的信息。不过,好消息是,为不同的任务注释8个示例是很简单的,只用花费很少的金钱和人力。据此,我们确定了一个关键问题,即如何确定哪些问题是最重要和最有助于注释的。
具体来说,任务的定义如下:给定一个下游数据集D,我们首先使用few-shot CoT为D中的每个unlabeled-question构造prompt,对于每个prompt都让模型回答k次。然后根据每个问题的k个答案计算该模型的不确定性u。对于u,我们选择u最大的最不确定的n个问题,并且人工的注释所选的问题,以生成新的范例E。最后,用新的注释示例推断该任务上的每个问题。
至于不确定值u如何计算,论文提出了4种计算方法,此处不抄录公式。