- 민병국
- 벡터화: TF*IDF, Word2Vec, ELECTRA
- 추가 (못했음): FastText, Glove
- 예측모델:
- 회귀: LogisticRegression, LightGBM
- DNN: 1D CNN, LSTM/BiLSTM, ELECTRA
- 벡터화: TF*IDF, Word2Vec, ELECTRA
- 정선우
- 전처리: BERT
- 모델: BERT
쇼핑몰 리뷰 평점 분포 (3점은 분류가 안되기 때문에 문제 자체에서 제공 안함)

리뷰 평점1과 평점5의 Token IDF 분포 (TfidfVectorizer 로부터 추출)

노이즈 제거와 특징이 되는 단어들을 선별하는 것부터가 전처리의 시작
- 강승용
- 전처리, 시각화
- 김창명
- 모델: XGBoost, LightGBM
- 리뷰 텍스트를 전처리, 벡터화(임베딩)를 빠르게 끝내고
- (2일 소모) 가능한 모든 예측 모델들을 모두 돌려 본 뒤
- (3일 소모) 최적의 모델을 선정하여 개선시킨 모델을 만들자
- 앙상블 시키던지
- 문제점을 개선하거나 아이디어를 적용
- 7/18~19 프로젝트 선정을 위한 조사 (데이터, 베이스라인)
- 7/20 프로젝트 기획서 작성 및 제출
- 7/21~22 참고 모델 모두 돌려본 후 공유
- 7/25~27 나만의 모델 돌려본 후 공유 => 최적 모델 선정, 앙상블
- 7/28 문서화
- 7/29 발표
- 7/18 프로젝트 선정을 위한 조사... OK
- 이상과 현실을 오가며, 이랬다 저랬다 갈등
- 공공데이터 포털, 제주 데이터허브/빅데이터 등에는 통계 자료만 있고
- AI 데이터허브는 신청 수락까지 시간이 걸려 제외
- 7/19 Google Maps API로 제주 관광지 리뷰 수집 테스트... Not bad
- 시간도 충분하니 모든 모델을 돌려보고, 후반에 실데이터도 돌려보겠다는 욕심을 냄
- 다른 동료들의 과제 결정을 기다리며, 웹서핑으로 시간을 보냄
- 7/20 프로젝트 선정: DACON 쇼핑몰 분석 챌린지... OK
- 7/21 Okt 전처리에 하루 다 보냄. 이후 LightBGM 한번 돌려봄... Not bad
- Okt.pos 의 태그타입을 추가하거나, n-gram 생성, 통계적 triming 시도
- 결국 베이스라인 작업대로 가는게 낫다고 결론 내림
- 7/22 한국어 임베딩 모델을 찾고 돌리는데 하루 다 보냄... BAD
- 어제 못다한 LightBGM 모델에 RandomizedSearchCV 최적화 적용
- 한국어 Word2Vec 사전훈련 모델들이 작동하는지 체크하고 LR 모델에 적용해 봄
- LR 모델 기준으로 TFIDF 기법의 baseline 보다 잘 나오지 않아 초초해졌음
- 7/23~24 주말 추가 작업
- 이번 주까지는 더 섬세하게 전처리 작업을 해야겠다는 생각으로 시각화하며 살펴봄 (EDA)
- Okt 이전에 특수문자, 웹주소, 이메일, 전화번호 등도 지우고, 자모음이나 한글자도 지우고
- TFIDF n-gram 조합을 적용해 n-gram(1,2) 이 최적임을 찾아냄
- DACON에 v1_LR_Okt 제출 ==> 채점결과 0.6477 (27위)
- Okt 전처리, TFIDF 벡터화만 하고 LR 회귀모델 그대로 사용
- mecab 를 써보면 어떨까 해서 같은 작업을 반복함
- LogisticRegression 모델을 기준으로 비교해 봤으나 Okt 가 낫다고 판단
- 이번 주까지는 더 섬세하게 전처리 작업을 해야겠다는 생각으로 시각화하며 살펴봄 (EDA)
- 7/25 전처리와 Word2Vec 사전추가를 적용하고, 코드 정리, LSTM 일부 작성... Not bad
- DACON에 v2_LR_Okt 제출 ==> 채점결과 0.6504 (갱신)
- DACON에 v3_LR_Okt_stem 제출 ==> 채점결과 0.6457 (유지)
- 코랩 노트가 지저분해지면서 작업 능률이 떨어져 정리 작업함
- LSTM 모델 결과가 LR 보다 현저하게 낮아 불안감이 생김 (내가 뭘 잘못했나?)
- 7/26 LSTM, BiLSTM, 1D CNN 돌려보고 처참한 정확도에 짜증이 남... BAD
- LSTM 최적화를 하면 달라질까 싶어 keras_tuner를 돌려봤으나 BestModel 에서 val_acc=0.5773 나옴
- DACON에 v4_LSTM_Okt_wv 제출 ==> 채점결과 0.5659 (유지)
- LSTM, BiLSTM, 1D CNN 모두 정확도 0.5 중반을 넘어가지 못함 (학습 안됨)
- 7/27 다른 말뭉치를 찾아 Transformer 모델로 KcELECTRA 적용... OK
- 낯설은 Torch+Transformers 조합이였지만, 어떻게든 LR을 넘는 모델을 찾고 싶어 시도
- DACON에 v6.1_KcELECTRA 제출 (전처리 없이) ==> 채점결과 0.6366 (유지)
- DACON에 v6.2_KcELECTRA_clean 제출 (불용어 제거) == nt color='red'>채점결과 0.6591 (갱신)
- 7/28 문서 작업을 해야 하지만 KcELECTRA 모델을 추가 시도함... Not bad
- 학습
epochs=5가 너무 적었던 점을 감안해,epochs=15/10/5를 추가로 시도 - DACON에 v6.3, v6.4, v6.5를 제출했지만 채점결과 0.634, 0.6309, 0.6397 (유지)
- 이해도 없이 KcELECTRA 모델을 따라했지만, v6.2의 결과도 재현하지 못했다 😭
- 학습
- 7/29 발표 준비와 함께 이번 AIM 과정에서 얻은 것들을 되돌아 본다... OK
작년에 딥러닝 기술을 도입할 욕심을 냈었으나 난이도와 여건상 포기를 했다. 이후로도 책만 사놓고 띄엄띄엄 읽기만 하고, 심리적인 진입장벽은 커져만 갔다. 그래도 나에게는 '웹 풀스택 개발자'이라는 만능 스킬셋이 있으니 AI는 특수한 일부의 직업이라 여기고 공부를 미루어 두었다.
그러다 뜻하지 않게 퇴사를 하고, 내가 원하는 업종의 채용공고를 훓어 보는데 세상은 내 생각과 많이 달라져 있었다. 커머스부터 제조, 모빌리티, 포털, 배송 등 업종을 불문하고 AI관련 구인공고가 대다수였다. 세상은 프론트/백엔드 개발자와 더불어 AI엔지니어가 구인공고에 나란히 올라오도록 바뀌어 있었다. 이 뿐만 아니라 통칭 백엔드 개발자라 불리던 포지션은 DevOps 엔지니어, AI 엔지니어, Data Infra 엔지니어, VR/AR 엔지니어 등 다채롭게 변해있었다.
세상이 변한건 알았고, 이제라도 멀리 내다보며 다음 경력을 잡기로 결심했다. 그러던 참에 제주ICT에서 진행하는 딥러닝 교육 소식을 들었고, 구직 기간을 투자하며 공부 해보자는 선택은 지금와서 보아도 잘한 선택이라 자찬한다.
코드스테이츠의 스케줄은 기본적인 이론 습득과 더불어 튜토리얼이 적절하게 배분되어 있었고, 금요일 챌리지를 통해 한주간 공부의 성과를 평가할 수 있었다. 온라인 수업이라 하루 분량을 빨리 습득한 날은 추가 공부도 가능해서 리뷰를 통해 궁금한 점을 물어볼 수 있는 시간이 큰 도움이 되었다. (코드스테이츠 한정민 강사님, 김가연 강사님에게 감사 인사를 드립니다)
프로젝트는 또한번 이상과 현실을 혼동하는 나에게 깨달음을 주었는데, 한번에 두걸음은 못걷는다는 점이다. 처음 생각은, 프로그래밍 기초도 있고 인터넷에 자료도 많으니 2주라는 시간이면 모든 문제를 풀어보자는 계획이었다. 이론과 현실이 다르듯이 구어체와 노이즈로 범벅된 실제 데이터는 공부했던 어느 기술에도 딱 들어맞지 않았다. 어떻게든 모델을 돌려보고 추측과 다르면 그제야 문제와 데이터를 살피는 어리석은 짓을 짧은 기간에도 몇번을 저질렀다. 월등할거라 여겼던 RNN/CNN 이 LogisticRegression 모델보다 결과가 좋지 않을 때에는 무엇을 더 해보아야 할지 모르겠다는 막막함도 느꼈다. 개인이 가진 시간과 체력의 한계를 절감했다.
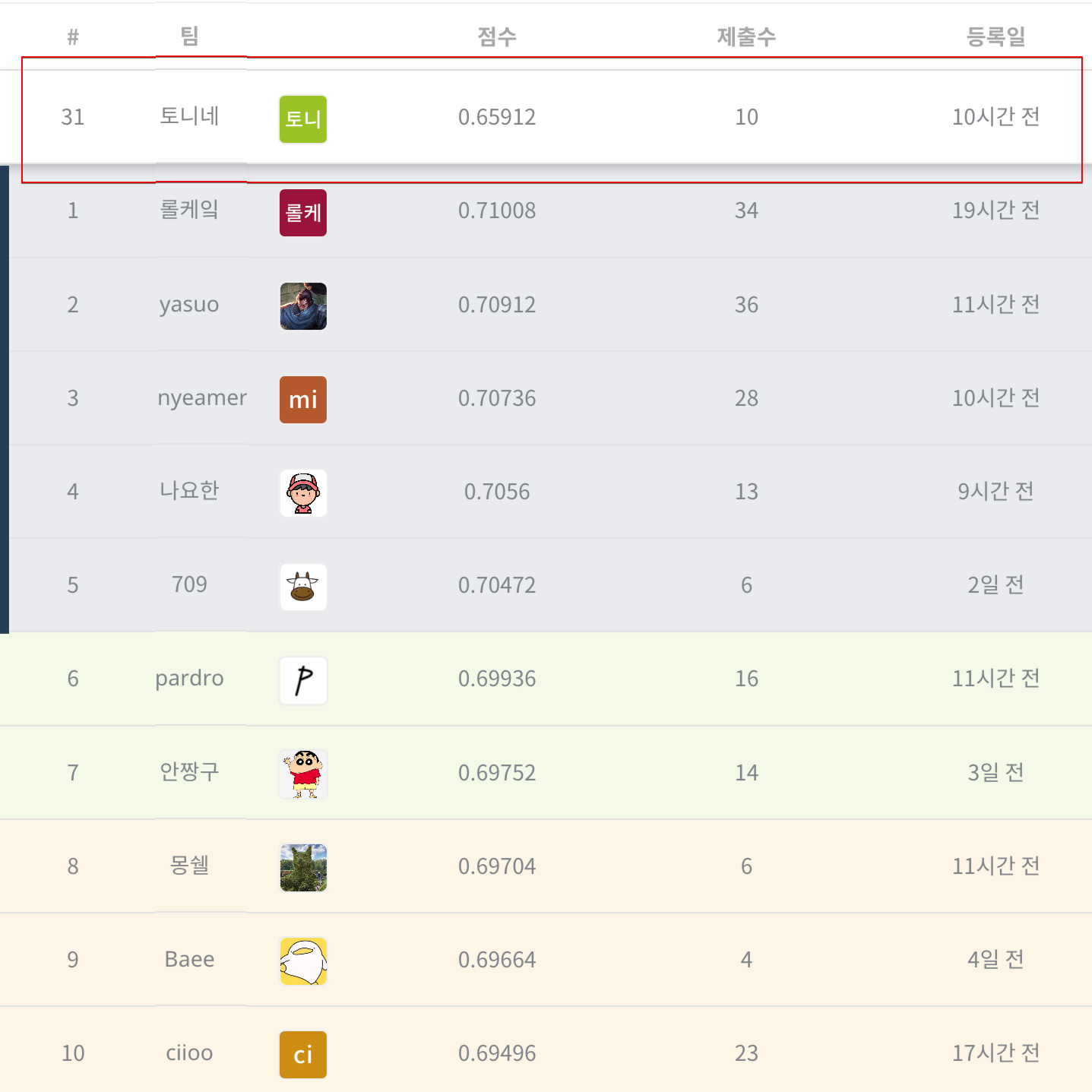
데이콘 경진대회에서는 제출 자료에 대한 정확도 평가와 순위를 제공한다. 이번 프로젝트의 성과는 KcELECTRA 모델을 사용해 얻은 정확도 0.6591 (31위)로 축약된다. 목표보다 부족한 성과이지만 전체 과정을 경험했고, 실데이터를 상대로 성과를 얻었다는 것, 궁하면 뭐든(?) 가져다 쓸 수 있다는 경험도 얻었다. 정리하자면 이제는 진입장벽을 느끼지 않고 혼자서도 공부를 이어갈만 하겠다는 마음가짐이 큰 성과라 생각한다.
- 1차 목표: 제시된 베이스라인2(정확도 0.641)보다 더 높은 정확도를 얻는 것... 성공!!
- 베이스라인2: Okt + TFIDF + LogisticRegression
- 제출 v2: 전처리 + Okt + TFIDF + LogisticRegression
- 제출 v6.2: 전처리 + KcELECTRA 임베딩 + KcELECTRA 모델
- 2차 목표: 모든 모델을 다루어 보자는 것... (실패)
- LSTM/BiLSTM, 1D CNN, Transformer... '절반 성공'
- 3차 목표: 최고의 모델 또는 나만의 모델은 오리무중... (실패)
- 최소 LogisticRegression 보다 나은 모델을 찾는 것으로 급선회... '절반 성공'
문제를 해결하기 위해 찾아낸 팁과 코드들은 잘 정리해 둘 계획이다. 또 다른 문제를 받으면 더 빨리, 더 잘 풀수 있도록 말이다. 미래는 알 수 없지만, 나는 딥러닝에 한걸음을 디뎠다. (다른 동료분들도 좋은 경험이 되었기를 바랍니다)

| 제출일 | 버전 | 정확도 | 사용한 기법 |
|---|---|---|---|
| 2022-07-20 | baseline_v1 | 0.6160 |
공백분리 + Count(TF) + LR 모델 |
| 2022-07-20 | baseline_v2 | 0.6410 |
Okt + TFIDF + LR 모델 |
| 2022-07-23 | submission_v1 | 0.6478 | 전처리 + Okt + TFIDF + LR 모델 |
| 2022-07-24 (27위) | submission_v2 | 0.6504 | v1 기법 + 노이즈 제거 추가 |
| 2022-07-25 (29위) | submission_v3 | 0.6457 | v2 기법 + Okt 스테밍 추가 |
| 2022-07-25 | v4 | 0.5659 | 전처리 + Okt + W2V + RNN 모델(LSTM) |
| 2022-07-26 (32위) | v5 | 0.6276 | KoBERT 임베딩 + KoBERT 분류 |
| 2022-07-27 (34위) | v6.1 | 0.6366 | KcELECTRA 임베딩 + KcELECTRA 분류 |
| 2022-07-28 (29위) | submission_v6.2 | 0.6591 | 전처리 + KcELECTRA 임베딩 + KcELECTRA 분류 |
| 2022-07-29 | submission_v5.2 | 0.6634 | hanspell 전처리 + KcELECTRA 임베딩 & 분류 |
| 2022-07-29 (29위) | submission_v6.6 | 0.6685 | hanspell 전처리 + KcELECTRA 임베딩 & 분류 |
| 2022-08-02 (37위) | submission_v7.1 | 0.6489 | hanspell 전처리 + TF translate |
- 1위는 정확도 0.7124 (제출 40회)
- 2 ~ 6위는 정확도 0.70xx (제출 20 ~ 30회)
학습의 효과가 그리 크지 않다.
어떤 모델도 대동소이하고, 그나마 나은 모양이 이정도이다.


- epochs=5, max_len=64, hanspell 전처리 데이터 ==> 제출 acc 0.6685
| Step | Training Loss | Validation Loss | Acc | F1 | Precision | Recall |
|---|---|---|---|---|---|---|
| 200 | 0.874800 | 0.755506 | 0.675670 | 0.635766 | 0.608009 | 0.675670 |
| 400 | 0.714600 | 0.741090 | 0.696879 | 0.659495 | 0.651146 | 0.696879 |
| 600 | 0.674700 | 0.730055 | 0.698679 | 0.650947 | 0.660954 | 0.698679 |
| 800 | 0.587200 | 0.785325 | 0.684874 | 0.670020 | 0.661441 | 0.684874 |
| 1000 | 0.561900 | 0.824220 | 0.679872 | 0.667984 | 0.661331 | 0.679872 |
| 1200 | 0.484300 | 0.845129 | 0.681673 | 0.669266 | 0.662164 | 0.681673 |
| 1400 | 0.418500 | 0.915961 | 0.669468 | 0.662132 | 0.656407 | 0.669468 |
- 데이터 EDA
- 원본 데이터
- train.csv : 25000건
- reviews: 구어체 문장
- target: 정수형 1~5 (평점3 데이터는 제거됨)
- test.csv : 25000건
- reviews: 구어체 문장 - target: 없음 (제출용)
- train.csv : 25000건
- 리뷰 평점 r=1 문서그룹과 r=5 문서그룹간 비교
- IDF 분포 비교
- TFIDF 분포 비교
- 원본 데이터
- 전처리
- 노이즈 제거
- 한글 자모음 찾아보기 ==> 4584
- 영어 찾아보기 ==> 537
- 숫자 찾아보기 ==> 2425
- 특수문자 찾아보기 ==> 13360
- 웹주소 찾아보기 ==> 2
- 이메일 찾아보기 ==> 0
- 전화번호 찾아보기 ==> 4
- 한글자 리뷰 제거 ==> train(12), test(8)
- chr_size 또는 pos_csize 컬럼 생성
- 네이버 띄어쓰기, 맞춤법 (py-hanspell)
- 로컬에서 실행해야 더 빠르다
- 로컬에서 실행해야 더 빠르다
- 노이즈 제거
- 형태소 분석
- 임베딩
- word2vec
- FastText
- Glove
- universal sentence encoder - cmlm: 100개 이상 언어에 사용 가능
- 회귀 모델
- DNN 모델
- LSTM/BiLSTM
- 1D CNN
- label 전처리/후처리: RNN과 동일
- label 전처리/후처리: RNN과 동일
- Transformer 모델 (Hugging Face)
- 프로젝트의 목적이
정확도를 올리기 위해서보다어떤 문제를 풀기 위해서라고 접근하는게 좋음- 문제: 사용자가 작성한 리뷰의 표현과 평점이 일치하지 않는 문제 있다.
리뷰만으로 추정하는 평점을 활용하고 싶다는 목적을 구현하고자 한다.
- 문제: 사용자가 작성한 리뷰의 표현과 평점이 일치하지 않는 문제 있다.
- 정확도보다는 베이스라인 모델과 비교해야 이해가 빠르다
- 개선점 비교 가능
- 가장 정확도가 높았다는 hanspell 의 효과는 어느 정도인지 측정 가능한가?
- 많은 도구를 다루어 봤지만, (최적화 할 수 있는) 잘 쓸 수 있는 도구는 어떤 것인가?
- label 별 정확도도 살펴봤으면 좋겠다
- 전체 데이터에 대한 정확도만 비교해서 단순하게 결론낸게 아닌가
- 안좋은 label 그룹이 있다면, 개선하는 방향으로 해보면 어떨지?
- 우선 크게 두 그룹으로 나누고, 각 그룹 내에서 다시 분류를 하는 전략은 어땠을지
- 평점 1,2 그룹(dislike)과 평점 4,5 그룹(like)에 대해 이진 분류
- 각 그룹별로 특징적인 키워드를 먼저 선별하여 feature 로 적용했으면 좋을듯
- IDF 시각화 참조
1위 코드와 비교해 보면, 띄어쓰기 전처리와 electra 모델을 사용한 점이 같다.
그 외에 중요한 훈련 전략의 설계와 모델의 앙상블 등에서 큰 차이가 발생했다.
실제 문제들은 하나 이상의 규칙성을 포함하기 때문에 best-practice 로 매우 유용하겠다.
-
라이브러리
- py-torch, transformer( funnel + electra )
- py-torch, transformer( funnel + electra )
-
전처리
- 특수기호, URL 패턴 제거
- 한글
[가-힣]과 이모지emoji.UNICODE_EMOJI는 남기고
- 한글
- soynlp.normalizer.repeat_normalize: 반복되는 문자 정제
- 띄어쓰기 PyKoSpacing
- 특수기호, URL 패턴 제거
-
토크나이징 + 데이터셋
- 실제값 전처리:
df['target'].map({1:0, 2:1, 4:2, 5:3}) - CustomDataset(Dataset)
- 실제값 전처리:
-
학습
- 파라미터
- NUM_CLASSES = 4 (클래스는 4개뿐, 평점3은 제외)
- MAX_LEN = 50
- BATCH_SIZE = 128
- EPOCHS = 10
- LEARNING_RATE = 2e-5
- LABEL_SMOOTHING = 0.05
- SEED = 2022 (랜덤 시드는 22 사용)
- 사전훈련 모델 ==> 2가지 예측모델을 만들어 앙상블
- 콜백
- EarlyStopping
- 여러 요소를 따져서 조기종료를 정의하려면 Custom 클래스를 만들어야 한다
self.best_score갱신시save_checkpoint실행
- EarlyStopping
- 전략
- optimizer: AdamW
- 교차검증: StratifiedKFold(N_FOLD=5)
- 손실함수:
nn.CrossEntropyLoss(label_smoothing=LABEL_SMOOTHING)- 라벨 스무딩을 이용하여 모델의 일반화 성능을 향상시킴 (평점이 리뷰와 안맞는 케이스 완화)
- 참고: Label smoothing 이란?
- 파라미터
-
평가
- 모델 2개 생성
- eletra_model = eletra 토크나이저 + skFold + CrossEntropyLoss(label_smoothing)
- funnel_model = funnel 토크나이저 + skFold + CrossEntropyLoss(label_smoothing)
- 모델 앙상블
- 예측값 = eletra 예측값 + funnel 예측값
- 두 모델의 예측값 중 최대값 선택:
torch.max(torch.tensor(preds), dim=1)
- 모델 2개 생성
-
예측(테스트) 결과 생성
- 예측값 후처리:
submission['target'].map({0:1, 1:2, 2:4, 3:5})
- 예측값 후처리:
참고
- text in red
+ text in green
! text in orange
# text in gray
@@ text in purple (and bold)@@