Abstract. Web hosting companies strive to provide customised customer services and want to know the commercial intent of a website. Whether a website is run by an individual person, a company, a non-profit organisation, or a public institution constitutes a great challenge in website classification as website content might be sparse. In our paper, we present a novel approach for determining the commercial intent of websites by using both supervised and unsupervised machine learning algorithms. Based on a large real-world data set, we evaluate our model with respect to its effectiveness and efficiency and observe the best performance with a multilayer perceptron.
Keywords. document classification, web, text mining, machine learning
In this repository, we provide
- the source code for all our implemented approaches to classify websites according to the degree of commercial intent, and
- the data set consisting of domains whose websites were used for website classification.
The code comprises three parts:
- Startup
- Unsupervised learning: Clustering
- Supervised learning: Models for Classification
When using R-Studio, this script will set up your working directory to the root path of the folder. It will also install all required packages. Some packages will require user interaction in the terminal.
We provide a list of domainnames and a class-label. Using a simple crawler like Rcrawler the html content of these pages can be downloaded. For our work we crawled up to 30 pages within the website. Afterwards the plain text has to be parsed from the html, removing all html-tags. The result should be a table with two columns: The domainname (as the key) and the column (named "volltext") with the plain text of all the crawled pages of the website concatenated (both string). Of course, the class-label can also be kept.
domain|volltext|category
-------------------------
web.de| pagetext| K
With this data you can proceed to the unsupervised learning.
The usupervised learning starts with loading the data you created the way described above. At the beginning, the texts are transformed into document-term-matrices. Don't wonder about test and training, they are the same. Function was implemented with supervised learning in mind.
You find code and evaluation of the clusting using k-means and DIANA. there is also a visualization of them using t-sne which gives an overview, how good they worked.
The supervised learning contains many models and parameter sets. therefore training and evaluation are moved into functions. A wrapper function reads in an excel-file, the execution-list. It contains the name of the model and the parameters to set for training & evaluation. You will have to reduce it to the for you relevant models and combinations. Otherwise computation time will be long and errors are to be expected due to different datasets / splits.
It is important to get the shape of the input data correct. We included the script we used for creation of different shaped training / validateion / test -Slpits. Unfortunately they are not generic, so you will have to adapt them to your data. In our experiments we used the random sample as test-data, but here we will just make validationdata = testdata. You can change this if required and make other splits. As the qualityset will be hard to reproduce we took it from the script. Note: We included the originals in the functions-folder, but recomend using th ones in the scripts-folder. This can be changed in the config_SL.R Our scripts:
function_load_and_split.R: master$loadAndSplit(): Will take a path to an rds-file with your data (as described above) as input. You can easily change it to read from the environment or save your collected data as datatable in an rds-file.function_prepare_dtm.R: master$prepDTMs(): Takes the output of master$loadAndSplit() as input and creates the trainingdata for all different experiments.
After loading the training data, you decide, which models you want to execute / train & test. The results are saved to disk for later analysis. They contain the evaluation, confusion-matrices etc.
In this section we provide a confusion matrix of our models mentioned in table 6.
Model: MP1^T_D (Multilayer-Perceptron 1):
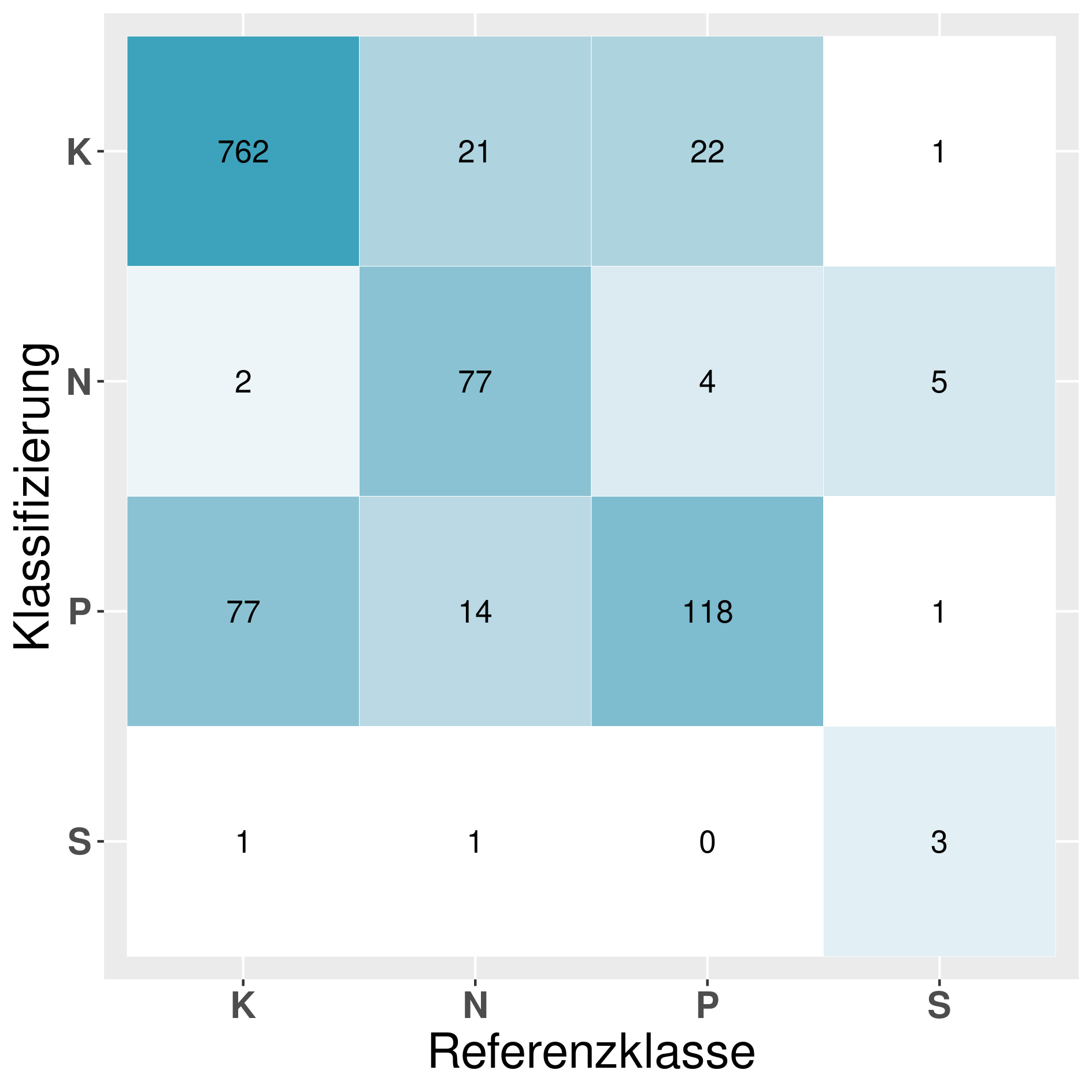
Model: SVR^T_D (Support-Vector-Machine 1vsRest):
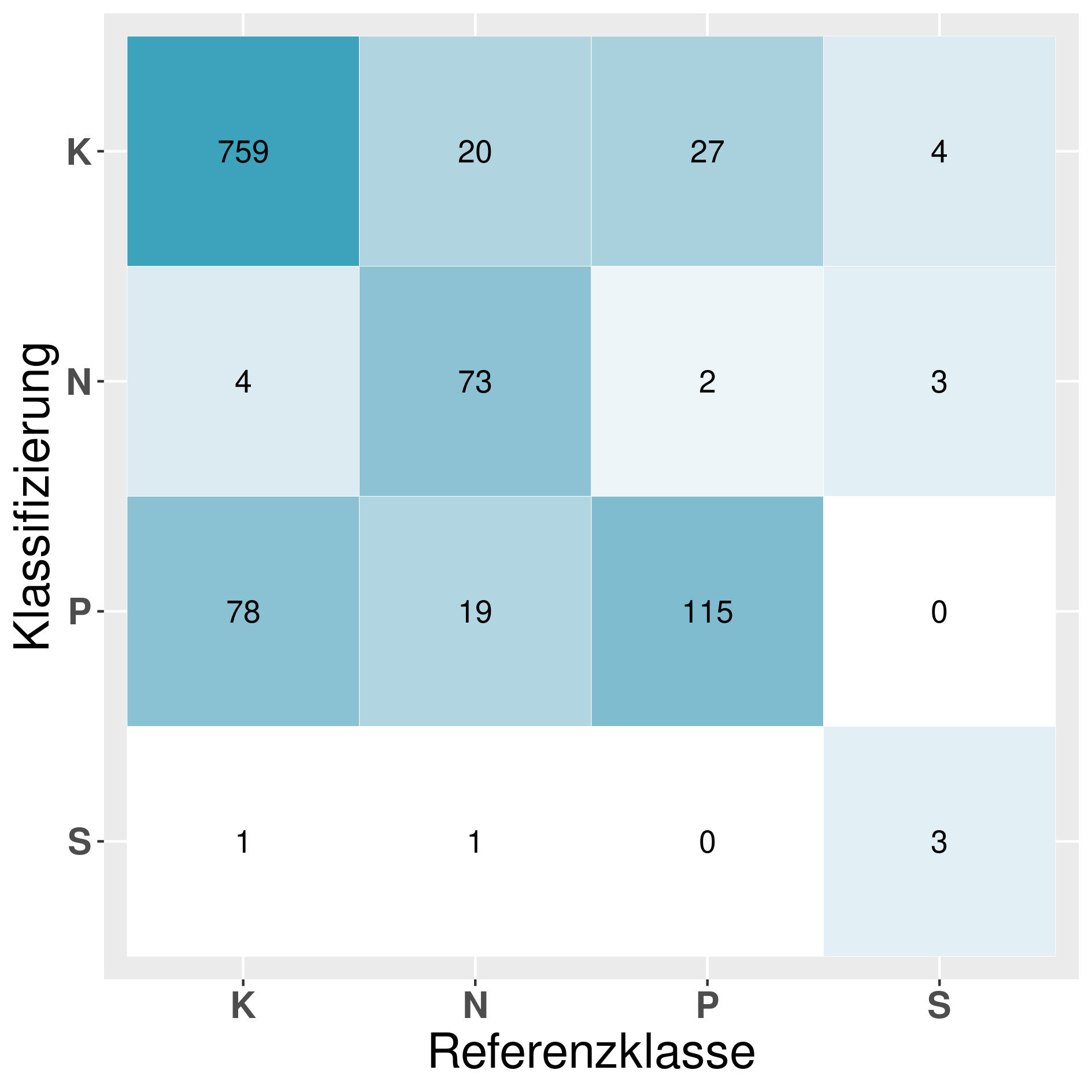
Model: SVO^T_D (Support-Vector-Machine 1vs1):
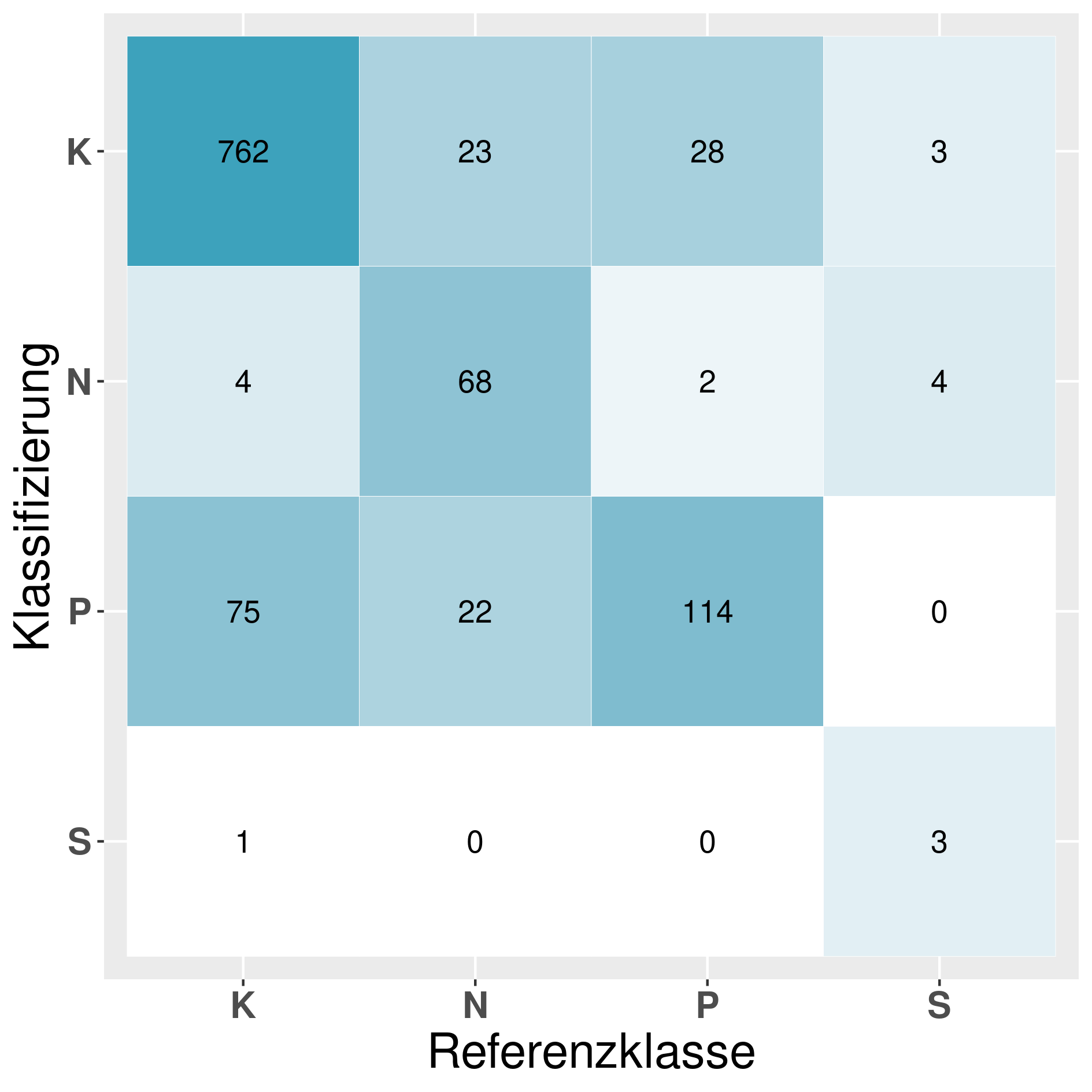
Model: RF^R_Q (Random forest):
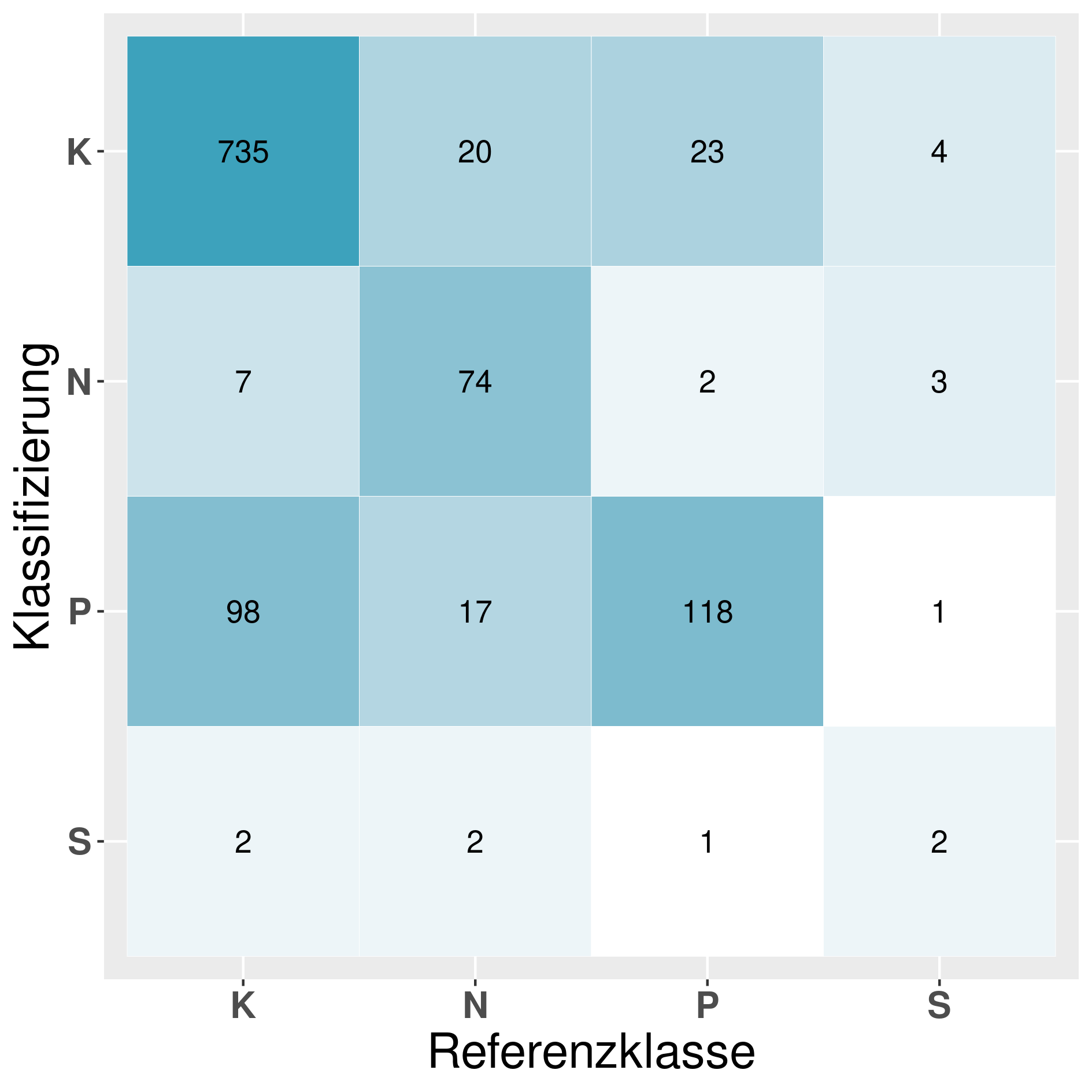
Model: GB^R_Q (Gradient boosting):
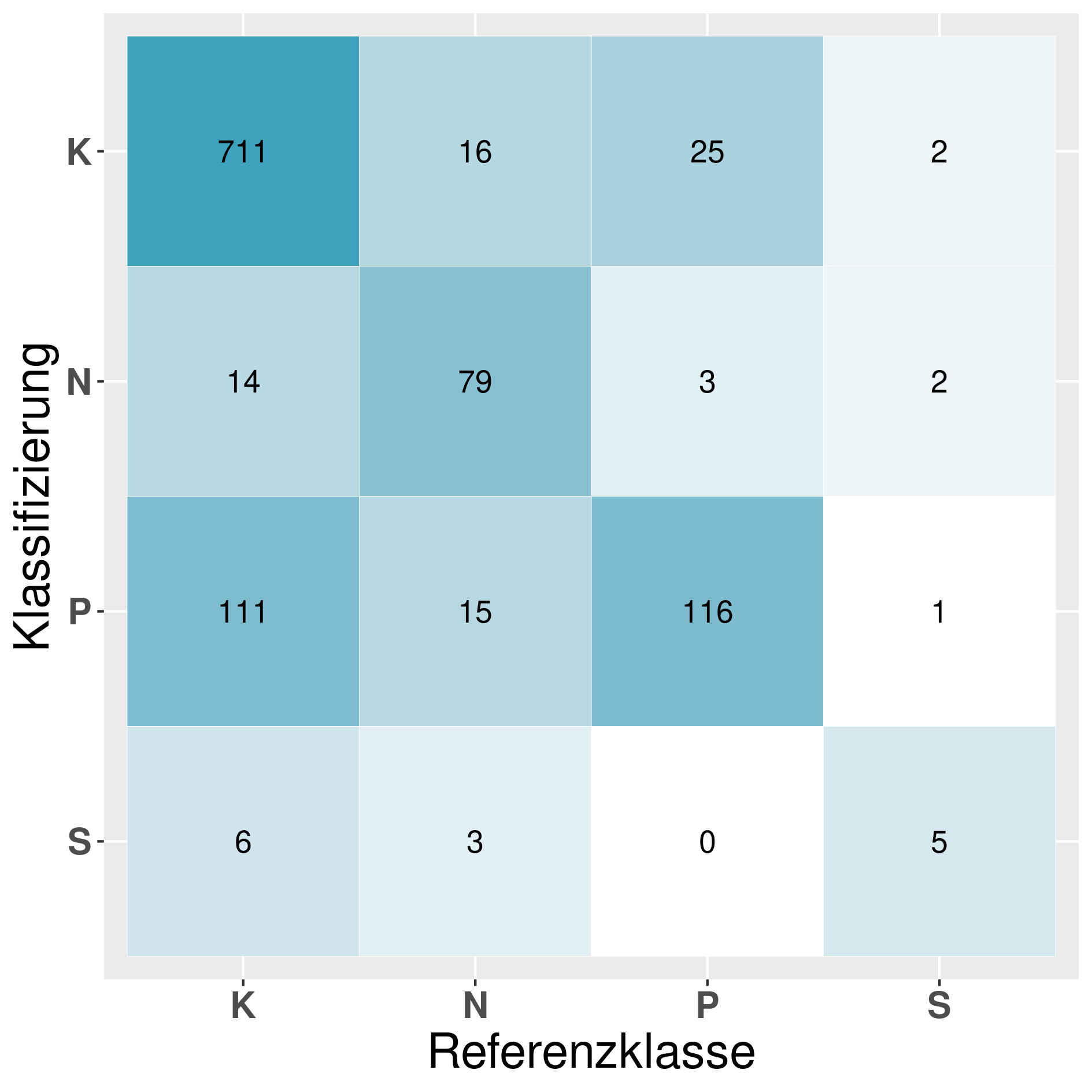
Model: CN1^25k_D (Convolutional neural network 1):
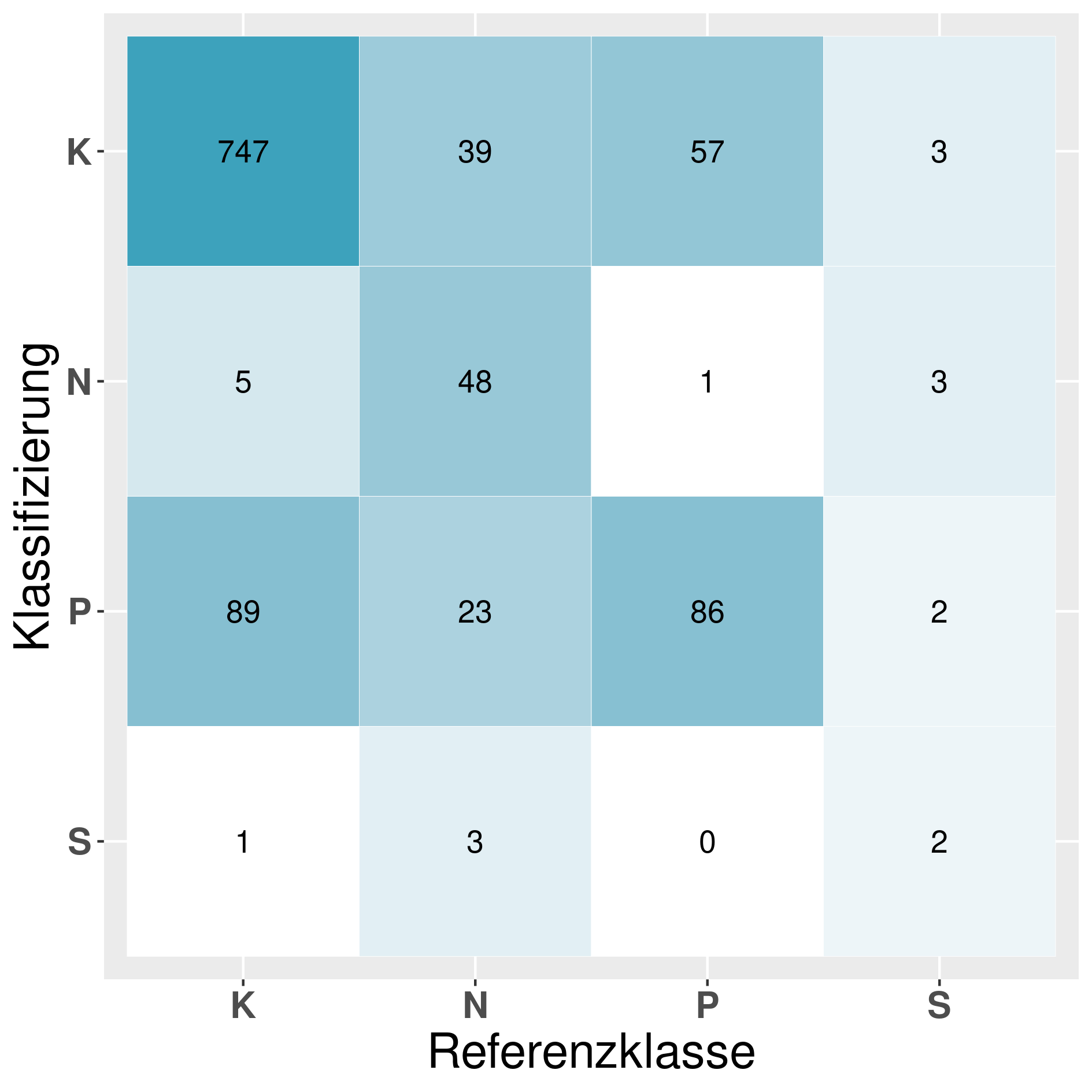
Model: NB^R_B (Naive Bayes):
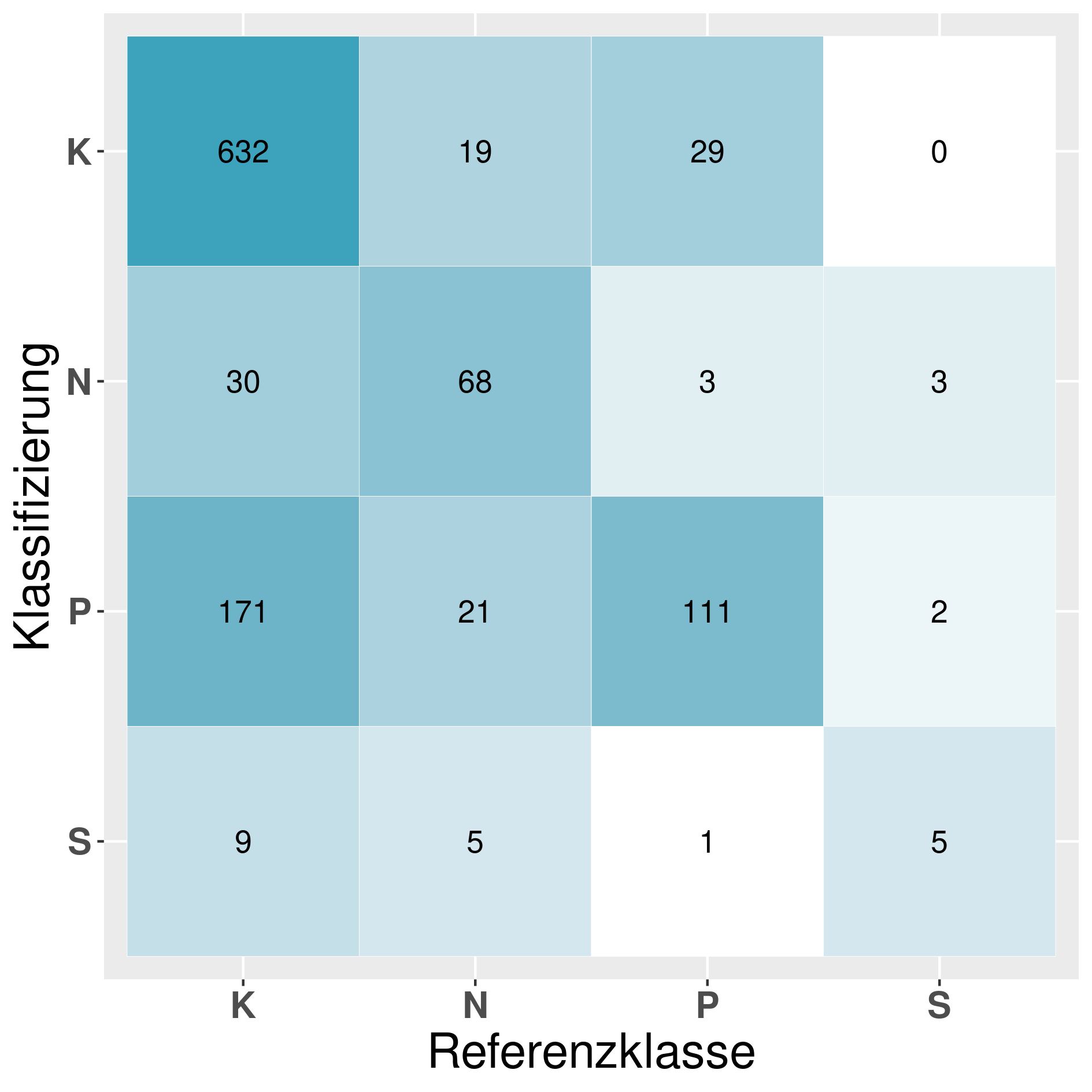
In case of questions or comments, feel free to reach out to us: michael.faerber@kit.edu
Further information about our approaches to website classification is given in our publication. Please use this publication for citing our approaches and data set. The DBLP-entry is available here.