My reimplemention of training #81
Comments
|
and the build_model(): you can find all related Net in |
|
and the Z_xr_Discriminator: |
|
and you need append some code in
|
|
here is my training loss, both loss of d and g are obviously decreased, which means the training works |
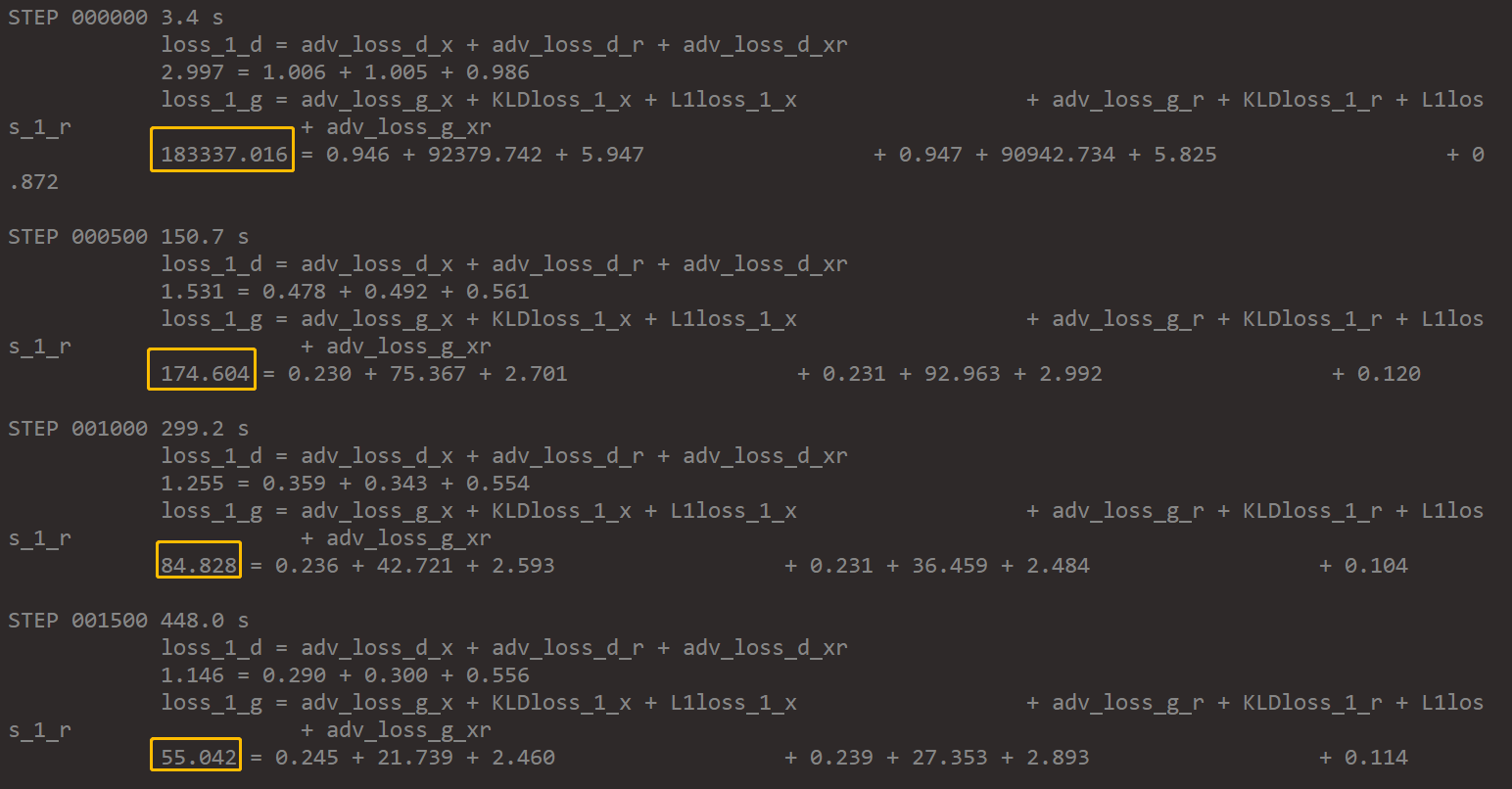
|
append the training code of mapping(transfer z_x to z_y) net |
|
What is your latent space dimension for the VAE_1 and the VAE_2? We have tried z_dim = 256, 512, ..., 4096
|

|
Self.mean_layer(z_x) layer involves (1) flattening followed by a fully connected layer or (2) just a fully connected layer? |
I have tried fc layers to 64x32x32 latent space but the vae is not trained successfully and then tried 1x32x32, but again it failed. I need find a third party vae github project of face restruction to check where i am wrong when implement reparam trick |
Can I get your source code repo of the training re-implementaion code? |
|
@jmandivarapu1 I would like to share, but I failed to train any meaningful result, so the training code may mislead you |
|
Wym and I don’t know how to use GitHub
…On Mon, Dec 28, 2020 at 10:21 PM poortuning ***@***.***> wrote:
@jmandivarapu1 <https://github.com/jmandivarapu1> I would like to share,
but I failed to train any meaningful result, so the training code may
mislead you
—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
<#81 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/ARZD4SBC3CIEZ4RKTEVULBLSXFDKBANCNFSM4UU6JW4Q>
.
|
|
Thanks for your nice code!!
|
|
Training code is just added. Welcome to go through the training details. |
follow the jouranl edition of the paper, I wrote a pytorch Pseudocode training code
where the lsgan_d and lsgan_g is defined as following:
The text was updated successfully, but these errors were encountered: