Is the predicted wav realy better than fastspeech1? #53
Comments
|
@Liujingxiu23 how is the quality and size of your dataset? If the quality is even worse than FastSpeech 1, maybe you should check the correctness of the pitch values given by the DIO algorithm (or any other algorithm you used). |
|
@ming024 thank you for your reply. I trained multi-speaker model using 7 speakers, totally abput 4w sentences. I will compare the synthsiezed wav again carefully and check the f0 feature extracted. |
|
@ming024 Thank you for your help!
There is again another quesiton I meet。 |
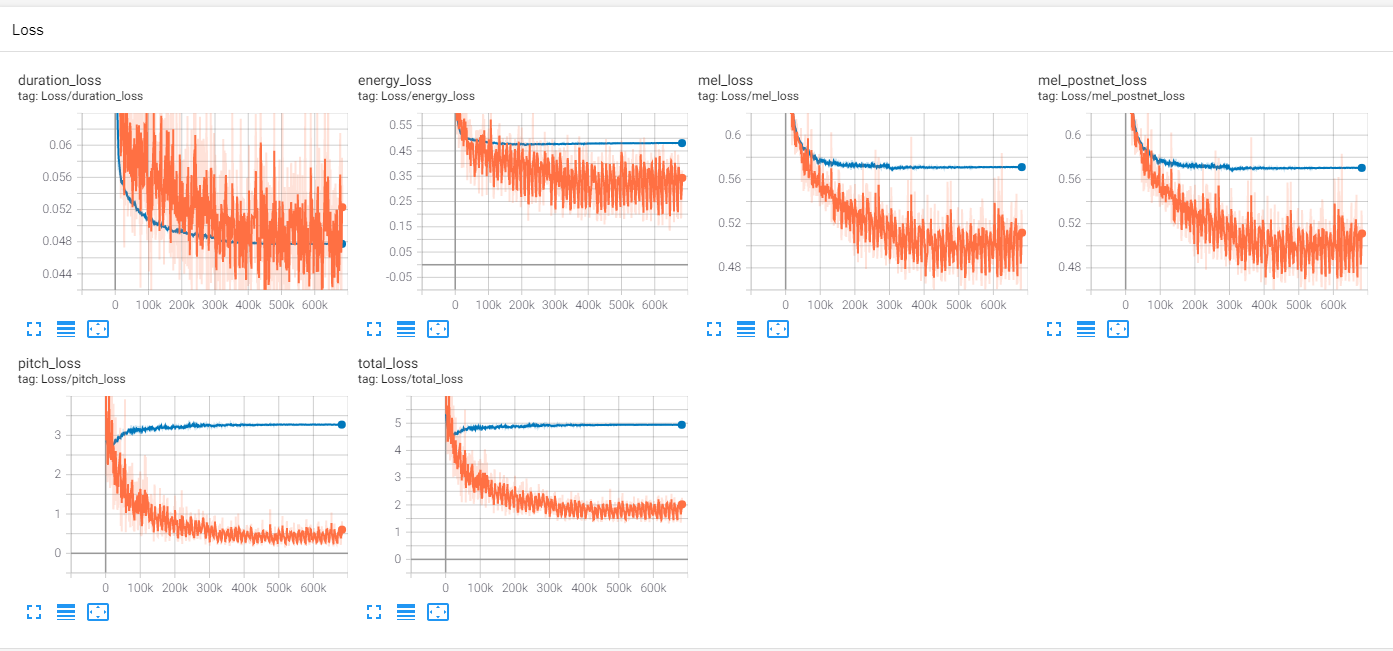
|
@Liujingxiu23 People believe that Tacotron is better, at least according to the SOTA TTS papers. I think it is because the autoregressive models can fit better to the datasets. However, they are more difficult to train (and probably takes more computation resources) so maybe that's the reason why you find the results are not good on your datasets. For the language transfer experiments, one possible solution is to use pretrained speaker embedding instead of the embedding table. You can check my paper here. |
|
@ming024 Thank you for your reply, I will try "use pretrained speaker embedding instead of the embedding table". |
|
@Liujingxiu23, how are you using speaker embeddings for multi-speaker training of fast-speech with hidden encoder vectors? |
|
I did not change the code, my way of using speakers info is just the same as the code in the github. |
|
closed #53 |
I tried to train on my own dataset, but the result is not as good as I expected, and even worse than fastspeech1. I use default setting , phone-level, with hifigan as vocoder
How about your results?
The text was updated successfully, but these errors were encountered: