Create a Recurrent Neural Network (RNN) with PyTorch to identify when an article might be fake news.
Live Demo: https://fakenews-rnn.herokuapp.com/
Fake news or junk news is a type of propaganda that transmits misinformation via traditional print, broadcast news media or online social media. Fake news was not a popular term three years ago, but it is now seen as one of the greatest threats to democracy, free debate and the Western order. It was named 2017's word of the year, raising tensions between nations, and may lead to regulation of social media.
There are many discussions and forums that give us some tips to identify fake news, but the process is long, tedious and time-consuming. As a result, many algorithms have been created to automatically identify unreliable articles and websites. There are many competitions dedicated to identifying fake news using some sort of algorithm such as the Fake News InClass Prediction Competition on Kaggle - an online community of data scientists and machine learners.
This project applies a recurrent neural network (RNN) together with long short term memory (LSTM) to identify fake news. A recurrent neural network is an artificial neural network architecture where connections between nodes form a directed graph along a sequence. RNNs can use their internal state (memory) to process sequences of inputs, and therefore, exhibit temporal dynamic behavior for a time sequence. This makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition. LSTMs are an improvement of the RNNs, and are quite useful when our neural network needs to switch between remembering recent things, and things from a long time ago.
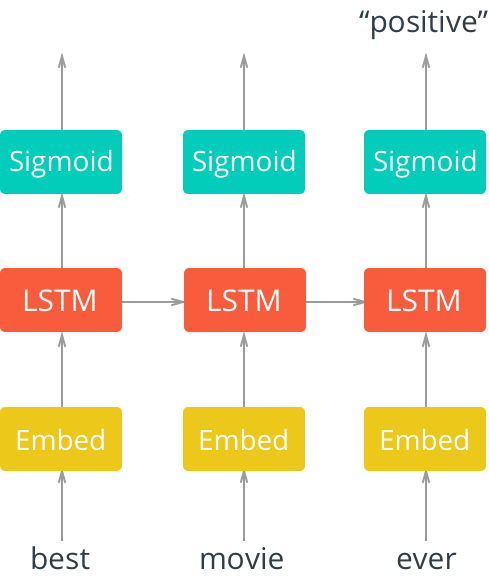
Image Credit: Intro to Deep Learning with PyTorch by Udacity.
The layers are as follows:
- An embedding layer that converts our word tokens (integers) into embeddings of a specific size.
- An LSTM layer defined by a hidden_state size and number of layers
- A fully-connected output layer that maps the LSTM layer outputs to a desired output_size
- A sigmoid activation layer which turns all outputs into a value 0-1; return only the last sigmoid output as the output of this network.
The data to train the neural network were obtained from the Fake News Competition on Kaggle. The dataset which contains 20,800 articles with 267,449 unique words is split into training (80%), validation (20%) and test (20%) sets. As there are approximately 267,449 words in our vocabulary, a word embedding layer is used as a lookup table. In the embedding layer, words are represented by dense vectors where each vector represents the projection of the word into a continuous vector space. The position of a word within the vector space is learned from the text and is based on other surrounding words. The position of a word in the learned vector space is referred to as its embedding.
To train the model, clone this project and open the Jupyter Notebook FakeNews_RNN.ipynb
git clone https://github.com/minhkhang1795/FakeNews_RNN.git
The data can be obtained from the Fake News Competition on Kaggle, which can be downloaded here. Next, extract the downloaded file to the FakeNews_RNN folder to obtain two files:
-
train.csv: A full training dataset with the following attributes:
- id: unique id for a news article
- title: the title of a news article
- author: author of the news article
- text: the text of the article; could be incomplete
- label: a label that marks the article as potentially unreliable
- 1: unreliable
- 0: reliable
-
test.csv: A testing training dataset with all the same attributes at train.csv without the label.
The test set is for Kaggle submission. Therefore, we need to create our own test set by splitting the training data into training (80%), validation (20%) and test (20%) sets, which is instructed in the Jupyter Notebook.
Some hyperparameters of the model we could change:
embedding_dim = 200
hidden_dim = 256
n_layers = 3These hyperparameters together define our model (read more about the RNN Architecture in the section above).
This is a side project for PyTorch Scholarship Challenge from Facebook, which uses the Sentiment_RNN template from the program.