最近話題の LSTM (Long-Short Term Memory) を使って実験的に作った形態素解析エンジンです.Chainer の練習用に書いてみました.
分かち書きだけでなく,形態素解析も実装しているのですが,まだデータが整理できていないので,ドキュメントは準備中です.
Python3 + Chainer 1.6 以上で動作します.
git clone https://github.com/mitaki28/rnn-morpheme-analyzer.git
cd rnn-morpheme-analyzer
python3 -m venv morpheme-venv
source morpheme-venv/bin/activate
pip install -r requirements.txt訓練およびテストデータには,単語を半角スペースで区切り,各行に1文ずつ並べたテキストファイルを入力として受け取ります.
例:
これ は テスト です
今日 は いい 天気 です
python morpheme/segmentation.py train path/to/train.txt path/to/output/directorypython morpheme/segmentation.py test path/to/test.txt path/to/output/directory epoch学習したモデルを使って実際に分割するには,以下のコマンドを使います.
python morpheme/segmentation.py run path/to/test.txt path/to/output/directory epoch準備中
出現する文字を事前に辞書化せずに,byte 単位で処理しています.これによって,UTF-8で表現された任意の文章を扱うことができます.基本的に.1000文程度学習すれば,文字コードの途中で分割するようなことは,まず起こりませんが,一部,未学習の記号については文字コードの途中で分割してしまうようです.
chainer_examples や Bi-directional LSTM Recurrent Neural Network for Chinese Word Segmentation では,一般的な Bi-directional RNN が使われています.
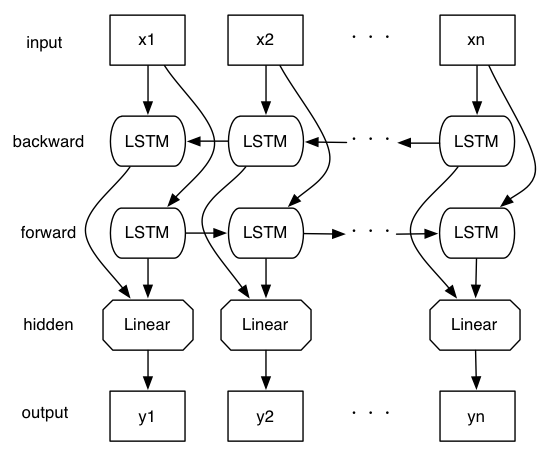
これを以下のように,少しだけ変えてみました.
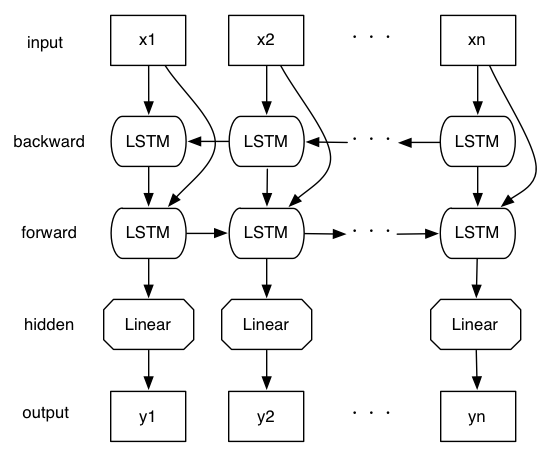
出力前の隠れ層で 2つの RNN の出力をマージするのではなく,backward RNN の出力を直接 forward RNN にマージしています. DAG の最長パスが2倍に伸びるので,処理は遅くなるかわりに,すべての位置について,次にどのような文字列が現れるかを先読みした上で分割を行うため,精度が向上するものと思われます.
現状,ちゃんと計測したのは,単語分割の F値 だけです.
ChainerとRNNと機械翻訳 に載っているデータセットを使って,単語分割オンリーで学習させてみました.
データには train50000.ja ,テストには test1000.ja を使っています.
このデータセットは,比較的クセのない日本語なので,50000文学習すれば 99% の精度で分割できます.
1000
precision: 0.950255326642
recall: 0.954879235601
F-measure: 0.952561669329
5000
precision: 0.967938665273
recall: 0.982924887198
F-measure: 0.975374214855
10000
precision: 0.983007345783
recall: 0.982659470937
F-measure: 0.982833377077
20000
precision: 0.984348896509
recall: 0.990445014598
F-measure: 0.987387545804
30000
precision: 0.988500663423
recall: 0.988675572857
F-measure: 0.988588109903
40000
precision: 0.987851043226
recall: 0.992745288861
F-measure: 0.990292118466
50000
precision: 0.99072028281
recall: 0.991772095904
F-measure: 0.991245909837
一方で,chainer_examples 版は以下のような精度になります.
1000
precision: 0.799856585133
recall: 0.974376395225
F-measure: 0.878533298329
5000
precision: 0.863014899211
recall: 0.955741046297
F-measure: 0.907014231106
10000
precision: 0.896908159532
recall: 0.951664563719
F-measure: 0.923475394396
20000
precision: 0.91850117096
recall: 0.951664563719
F-measure: 0.93478882639
30000
precision: 0.926962585996
recall: 0.954673396098
F-measure: 0.940613942813
40000
precision: 0.931468002647
recall: 0.95642046006
F-measure: 0.943779331482
50000
precision: 0.93455645924
recall: 0.959138115112
F-measure: 0.946687742492
morpheme/def 以下の形容詞・活用型・活用形定義ファイルはmecab-naist-jdic から抽出したものであり,morpheme/def/COPYING のライセンスに基づきます.
このプログラム本体は MIT ライセンスです.
- 形態素解析のドキュメント作成
- まともなコーパスを入手する
- 入力のミニバッチ処理
- コードの整理