Optimize getting relative page URLs #2272
Conversation
This is a custom implementation that's ~5 times faster. That's important because calls to `normalize_url` on a site with ~300 pages currently take up ~20% of the total run time due to the sheer number of them. The number of calls is at least the number of pages squared. The old implementation relied on `posixpath.relpath`, which (among other unnecessary parts) first expands every path with `abspath` for whatever reason, so actually it becomes even slower if you happen to be building under a deeply nested path.
|
So this change removes calls to the standard lib and replaces them with your own custom implementation. I realize that there may be some standard lib code that we don't need, but the assumption is that the standard lib code is well tested and accurate. Your custom code is an unknown. I suspect the existing tests don't cover nearly enough to be sure this doesn't break various edge cases (admittedly I didn't check). We will always go with accuracy over performance. If you want this accepted, then you will need to demonstrate that this is very well tested. By the way, you have been providing a lot of performance patches lately. I don't object to that. In fact, I appreciate that someone is looking at the issue, as I don't have any time to dedicate to the issue. In fact, reviewing all these patches which don't improve the project in any perceivable way (from my perspective) just adds more burden on me. Therefore, from my perspective you need to demonstrate that you aren't breaking anything. Your comments always mention how much of a performance improvement this makes. But I don't care much about that. The largest site I have is less than 20 pages. I have the perception that my sites build instantly on my very old machine. Personally I see no need for performance improvements. What I care about is ease of maintenance and accuracy. If you would like me to continue to spend time reviewing your performance improvements, please focus on those two factors first. Any performance improvements will always be second to those in my reviews. As an example, if the proposed change in this PR were to result in a future bug report, my "fix" would simply be to revert to the previous implementation. I'm not interesting in spending the time to work through the custom code to fix various edge cases. That is more of a maintenance burden than I want to take on. Therefore, before I am willing to accept it, I need to be sure that those bug reports aren't likely to happen in the future. |
Well, generally, it's tested for file system paths relative to the current directory, not something virtual...
So this function certainly supports less functionality than the old one, for example collapsing It's slightly unclear how to declare exhaustiveness, but the main idea is proving that inputs to it can only be some particular subset of strings, and then perhaps fuzz it within those constraints.
Well, don't worry much about that. I intended to have stopped already but this one is just such a big realization (also realization that stdlib usage isn't exempt from scrutiny).
I can promise a 24-hour response time with a fix :D |
|
If you would like this merged, then you will need to either point to an existing set of tests (I haven't taken the time to check), or. if they don't exist, provide a comprehensive set of tests. My guess is that you will only find a limited set of tests and need to provide more so that we have a comprehensive set of tests. |
|
I have done fuzzing as mentioned. It asserts that the output of the old function is the same as of the new function. It found mostly differences that I already knew about (and I did ensure that it found them for real), so I explicitly ruled out those inputs (see The fuzzer is told to generate a concatenation of any combination of any number of "any unicode string", "slash", "dot" # Requires: `pip install pytest hypothesis atheris`
import posixpath
def get_relative_url_1(url, other):
if other != '.':
# Remove filename from other url if it has one.
parts = posixpath.split(other)
other = parts[0] if '.' in parts[1] else other
relurl = posixpath.relpath(url, other)
return relurl + '/' if url.endswith('/') else relurl
def get_relative_url_2(url, other):
other_parts = other.split('/')
# Remove filename from other url if it has one.
if other_parts and '.' in other_parts[-1]:
other_parts.pop()
other_parts = [p for p in other_parts if p not in ('.', '')]
dest_parts = [p for p in url.split('/') if p not in ('.', '')]
common = 0
for a, b in zip(other_parts, dest_parts):
if a != b:
break
common += 1
rel_parts = ['..'] * (len(other_parts) - common) + dest_parts[common:]
relurl = '/'.join(rel_parts) or '.'
return relurl + '/' if url.endswith('/') else relurl
from hypothesis import strategies as st, given, assume, settings, example
@st.composite
def path(draw):
elements = st.one_of(st.text(), st.just('/'), st.just('.'))
path = ''.join(draw(st.lists(elements)))
assume(path != '') # The original function has `raise ValueError("no path specified")`
assume('/../' not in f'/{path}/') # The new function doesn't support normalizing paths
# print(repr(path)) # Uncomment to see produced examples.
return path
@settings(max_examples=100000)
@given(path(), path())
def test_equal(url, other):
assume(url.startswith('/') == other.startswith('/')) # The original function sees one path as relative to the current directory!
assert get_relative_url_1(url, other) == get_relative_url_2(url, other)
# Run with 'hypotesis' fuzzer: `pytest fuzz_get_relative_url.py -s`
# Run with 'atheris' fuzzer: `python fuzz_get_relative_url.py`
if __name__ == "__main__":
import sys, atheris
atheris.Setup(sys.argv, test_equal.hypothesis.fuzz_one_input)
atheris.Fuzz()I found that the function produced differences only for these classes of inputs that I didn't already know about: @example('foo', 'bar./') # The trailing slash should disqualify it from being a file.
@example('foo', 'foo/bar./.') # The trailing dot should disqualify it from being a file.I fixed this and will also add unittests. After that I continued to run on each of those 2 fuzzers for well over an hour and for well over 100000 examples, and it didn't find anything more. Now what remains is to prove that resolving |
|
And my exhaustive analysis of usages. Sadly the results aren't so clear cut. Summary - the only things that could've regressed:
I really think nobody would've done such things, and also this old behavior was probably not even the preferred behavior among these two. It's also quite easy to look through a bunch of themes with Otherwise, if we want to preserve this, in each of those cases, first wrapping those into a I'm willing to go through the motions, whatever the choice. Just hope you're not too tired of this. And I'll mention again that the old implementation has latent bugs, e.g. if leading slashes are involved (thankfully this very audit proves that such inputs can't happen) and if Full analysis (read only the parts in bold 😋)Listing all origins of the inputs:
Indirect origins mentioned above:
|
|
And, of course, there's the option of just implementing normalization as well, with almost no performance penalty compared to the previous state. Pushed the commits here for posterity, though you may not like the code size. |
|
I still want to see a comprehensive set of unittests included with this patch. And I don't care if some potential inputs will not currently be generated by MkDocs. We can't guarantee that will be the case in the future. If you want to do a custom function, then you ned to provide a complete set of unittests which demonstrate that any potential (past, present or future) input will return the correct normalized result. Until I see that, I'm not spending any more time on this. |
|
Please don't always respond with the immediate assumption that I will not do something. First was just making sure that this wouldn't be discarded.
So, is the code acceptable? If so, great, I will definitely add unittests. |
|
Added unittest. Btw, the existing tests are actually quite comprehensive. They just didn't try to find super abnormal cases, I suppose. But now that's covered. mkdocs/mkdocs/tests/structure/file_tests.py Lines 407 to 591 in ff0b726 |
|
And latest profile
|
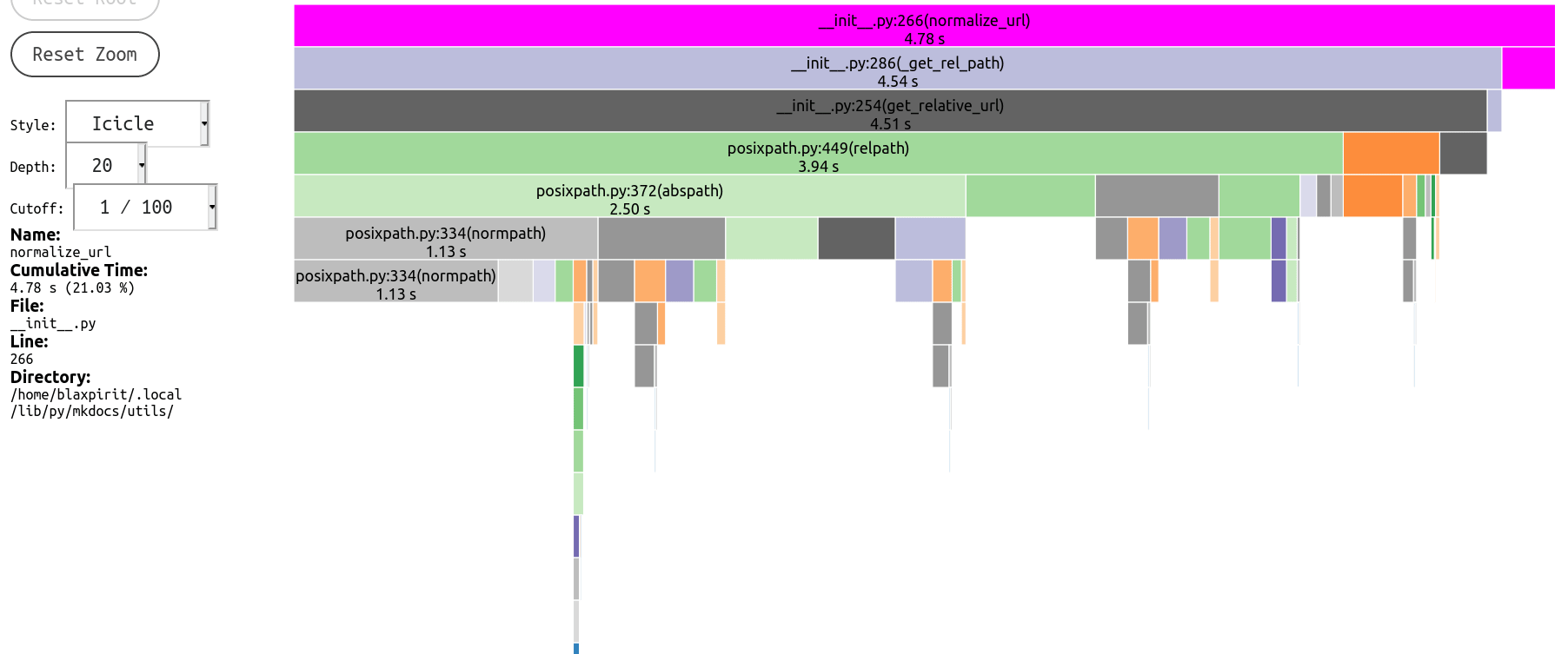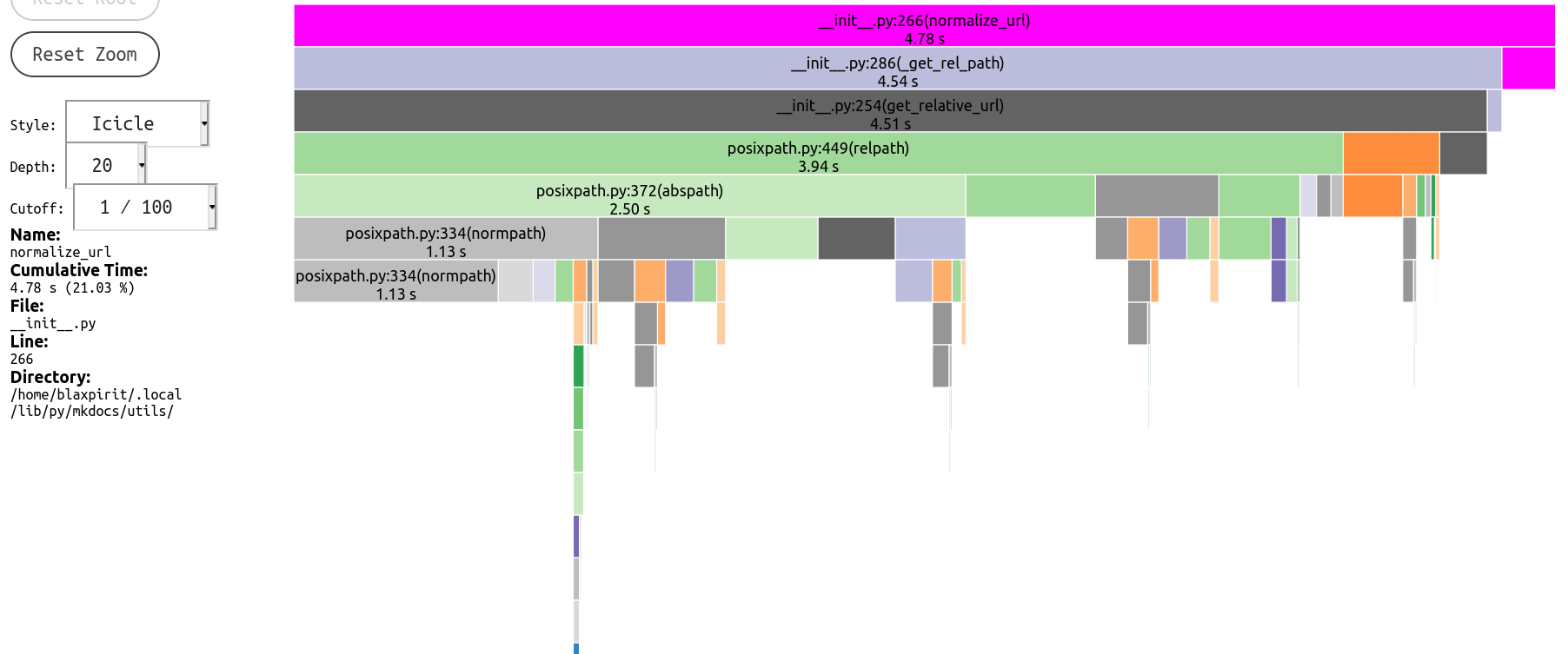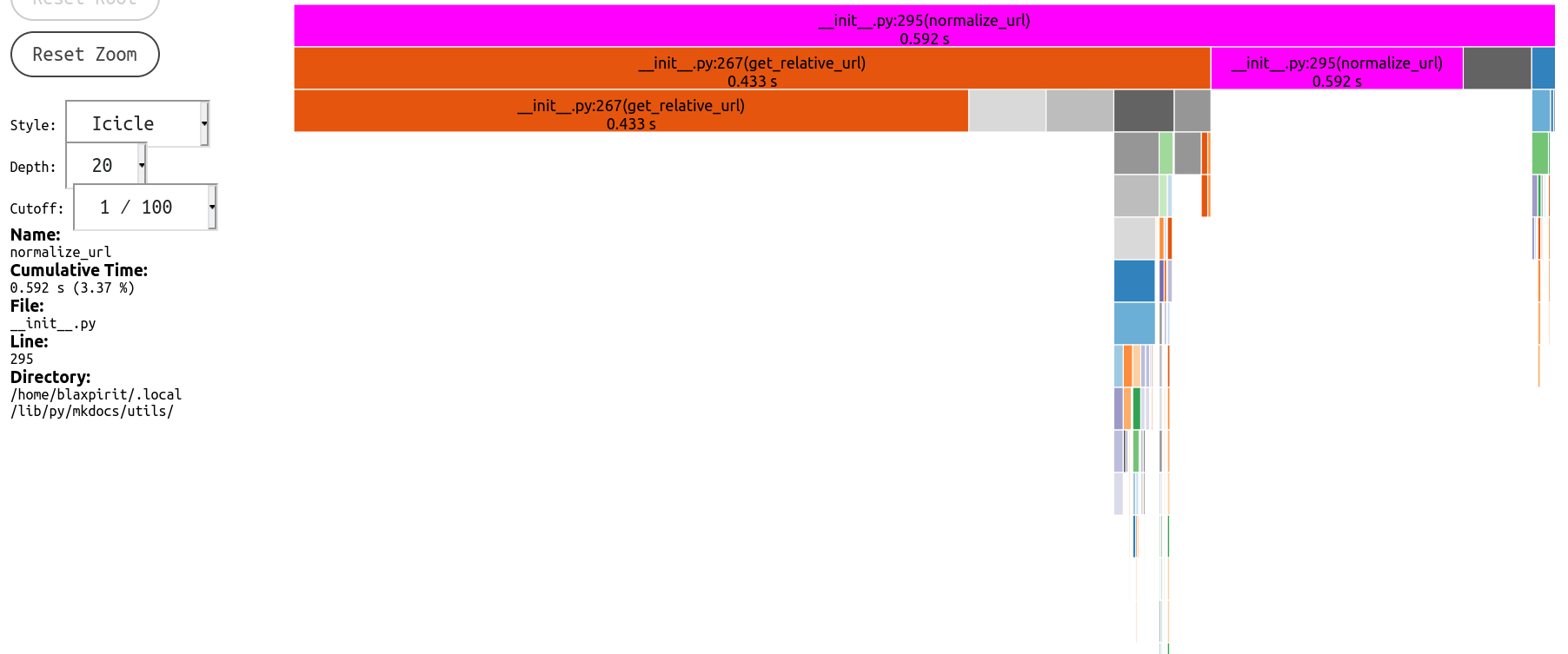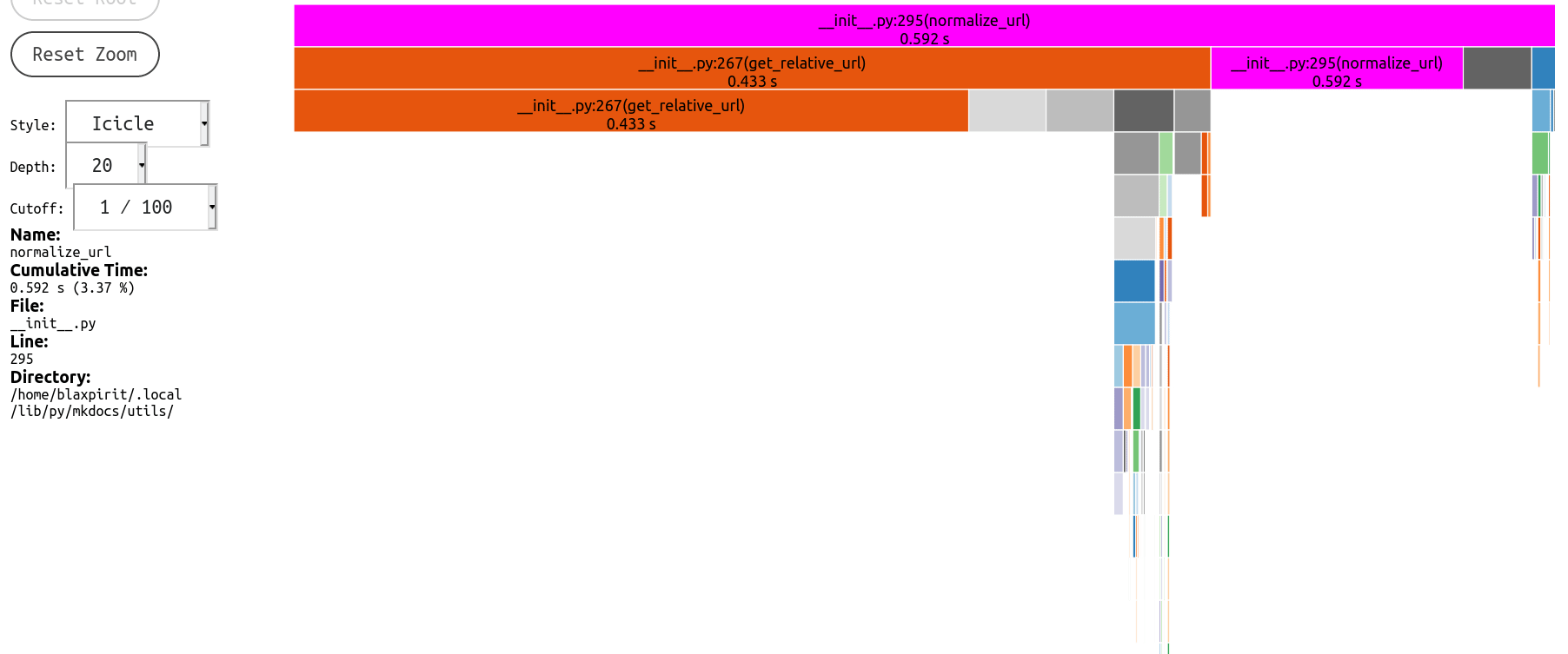
|
BTW, in my view I have done what was requested so far. (so this is just a ping, I guess) |
|
Please let me know your overall opinion on this direction. In case this just needs to wait before review, that's OK. |
|
I have given it a cursory look and it seems okay in principle, but I want to be extra sure your custom replacement for the standard lib function is comely reliable and that is going to take time. Time I havn't been motivated to spend on it. |
|
I have done soooo much fuzzing, and they just give 100% the same result, other than known differences that are being excluded. Just no way to be more sure. You can run it yourself and evaluate its thoroughness. Even intentionally introduce a bug and see how quickly it finds it. The differences are just the fact that the old function can spew paths that depend on the current working directory (revealing parts of it). I presume that's not a wanted behavior. In any case, I have also proven manually that these cases are never hit, but we will be safer with the new func. |
|
I'm closing this in favor of #2296. This adds our own implementation which is more of a maintenance burden. |
|
What do you mean "in favor of"... #2296 was a stepping stone to get all the breaking changes out of the way. This pull request now 100% exactly matches the implementation at master. This change, now compared to master, still cuts off 9% of build times for a site with 142 pages. And more if there are more. $ for i in {1..3}; do mkdocs build 2>&1 | grep built; done
INFO - Documentation built in 3.13 seconds
INFO - Documentation built in 3.09 seconds
INFO - Documentation built in 3.05 seconds $ for i in {1..3}; do mkdocs build 2>&1 | grep built; done
INFO - Documentation built in 2.88 seconds
INFO - Documentation built in 2.83 seconds
INFO - Documentation built in 2.81 seconds You had mentioned before
Well, there you go, the link above. That's a very real site with every page written by a human. At the very least I would've wanted to merge master to preserve this PR in a better shape. But certainly I didn't predict this to be closed instantly. Now the best view of this diff we have is not this pull request but rather https://github.com/oprypin/mkdocs/compare/relpath#diff
|
Which means it adds more maintenance burden for no gain.
Meh. Not a priority. The amount of gain is not worth the extra burden. |
|
Can you hand off the burden to me? How do you calculate whether it's worth saving thousands of people a second at a time? |
|
This issue really bothers me. I am developing a plugin that produces a lot of documentation pages based on source code. My users immediately see that the build is slow. I know exactly how to improve it and have done all the work (even way more work than should be necessary) but I am still powerless to fix it. I can tell the users "well, you can use this fork of MkDocs to speed up the build by 10%, because the maintainer of MkDocs doesn't accept my improvement". Um, well it is actually what I say, but they don't take me up on that. But hey, maybe you don't care about that usecase -- maybe I'm holding it wrong. But I have also shown you a very real site that just has 142 pages, each of them hand-written, regardless of plugins. I don't know where your impression of what performance gains are "worth it" is coming from, but I think a guaranteed 9% improvement would generally be considered really good, especially from a code delta of merely 30 lines added, 15 deleted. I have also provided all kinds of other arguments. E.g. that the code has no reason to change so it's not exactly a maintenance burden. Also that I would gladly respond to any issues with this code myself. Also you can easily revert it any time. I don't know how I deserve this -- you really just shrug away everything I say. My words, even perfectly backed up by facts, are instantly overridden just by your opinion, feeling, even. |
|
@waylan This is still a very important improvement. I'm not going to just forget this. It comes up in my mind quite often actually. You still haven't provided any solid arguments against this, and I'm appalled that you think it's OK to let your mere opinion stand above arguments. And to reiterate on the claim that you think you have: any "maintenance burden" from this is instantly fixable by reverting this. |
This is a custom implementation that's ~5 times faster. That's important because calls to
normalize_urlon a site with ~300 pages currently take up ~20% of the total run time due to the sheer number of them. The number of calls is at least the number of pages squared.The old implementation relied on
posixpath.relpath, which (among other unnecessary parts) first expands every path withabspathfor whatever reason, so actually it becomes even slower if you happen to be building under a deeply nested path.Profile before/after
In context