Replace TransitiveClosure with an ObjectQueue trait #607
Conversation
Now ProcessEdgesBase::nodes implement ObjectQueue instead of ProcessEdgesWork itself. Renamed parameters. - trace -> queue - T -> Q
Updated some comments. Made `enqueue` always inlined. Removed the unused `tracelocal.rs`.
|
I think the code is ready, but I am waiting for the benchmark result. |
|
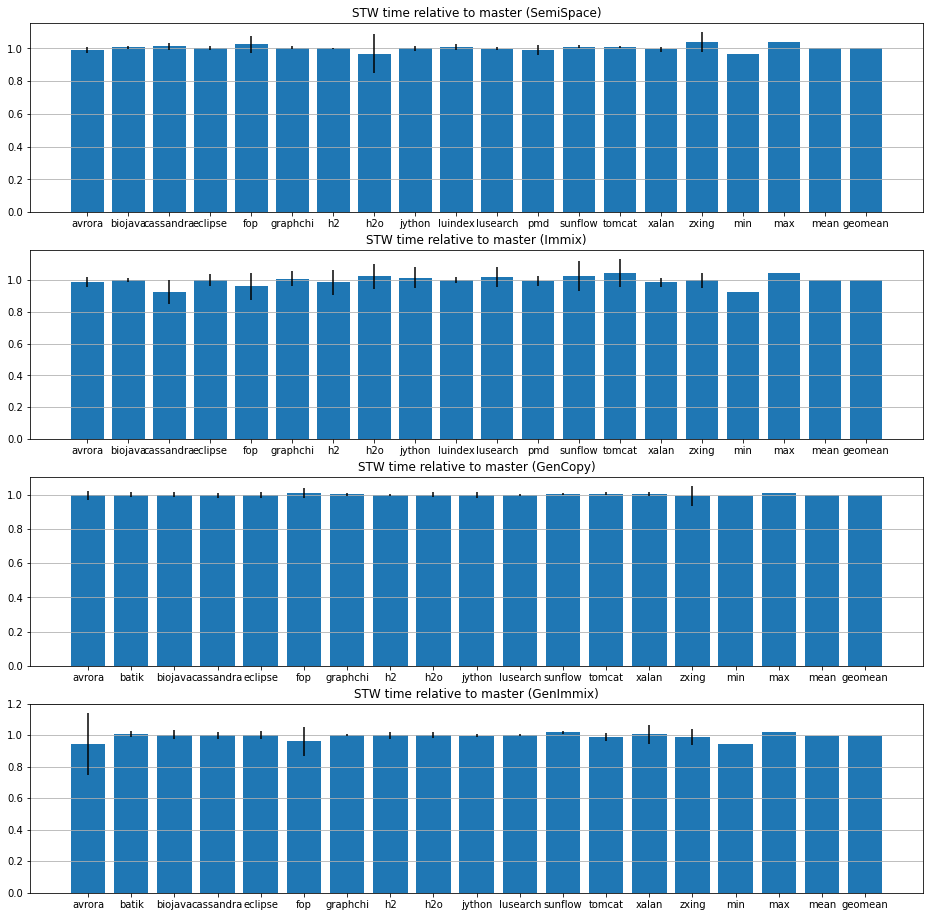
I ran Dacapo Chopin on bobcat.moma (Alder Lake), comparing the master and this branch. 20 iterations, 3 invocations each, 4.8x min heap size. Statistics show that the effect on STW time is negligible. (Outliers (zscore >= 3) are removed.) Geomean of relative STW time across different benchmarks:
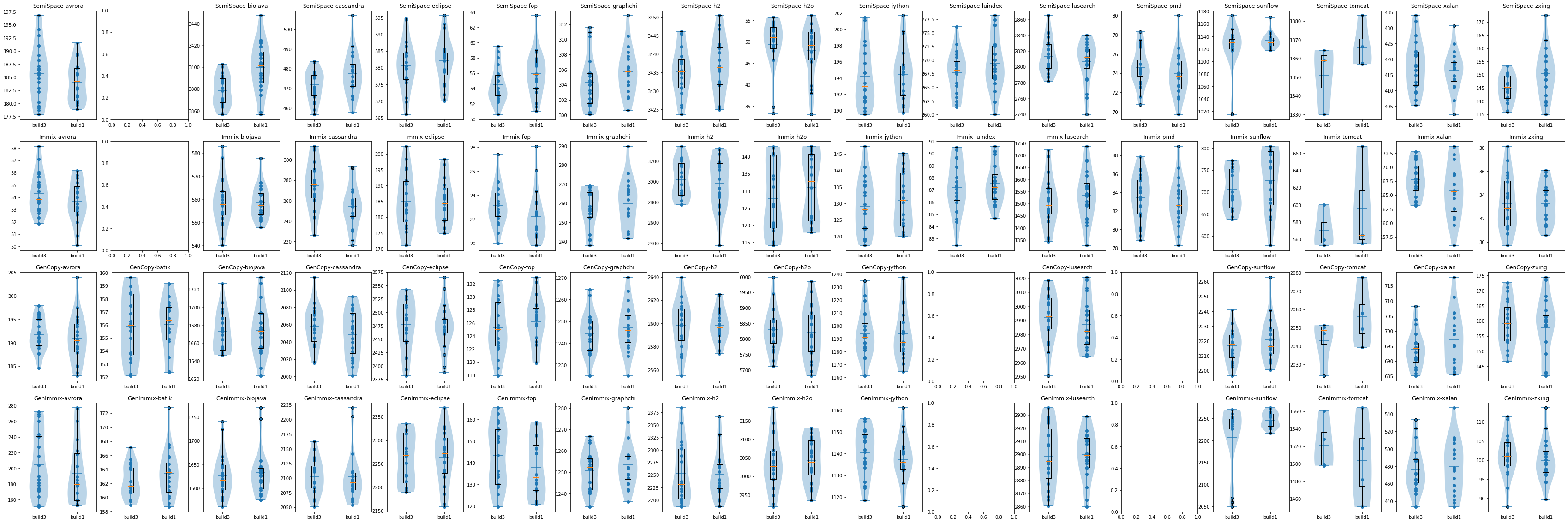
FYI: Here are the scattered points for all executions (with outliers removed), together with box plots and violin plots, just in case you don't trust the means and standard deviations. Note that the plots for some plan-benchmark combinations are missing. For some combinations (such as SemiSpace-batik), GC did not happen during the execution; For some combinations, (such as luindex and pmd with generational collectors) it crashed. (Running lusearch and pmd with generational collectors will result in crashes for both master and the branch. We should investigate later.)
|
Yes, I found this earlier when I was doing a performance evaluation of MMTk and brought it up in a meeting. I recall @wenyuzhao mentioning that it might be related to the barriers. I believe he will be updating the barrier code due to his LXR PR, so it might be resolved with it. EDIT: I believe I made an issue for it here: mmtk/mmtk-openjdk#156 |
Those lines of code were added by mistake.
There was a problem hiding this comment.
LGTM. Just two minor questions regarding #[inline].
One thing that may be helpful is configuring codegen-units in the bindings and setting it to a low value (like 1) may improve codegen quality. So functions in mmtk-core are more likely to be inlined.
| @@ -178,42 +178,42 @@ impl<VM: VMBinding> Gen<VM> { | |||
| } | |||
|
|
|||
| /// Trace objects for spaces in generational and common plans for a full heap GC. | |||
| pub fn trace_object_full_heap<T: TransitiveClosure>( | |||
| pub fn trace_object_full_heap<Q: ObjectQueue>( | |||
There was a problem hiding this comment.
Shall we mark this as #[inline(always)]? Also the trace_object_nursery function below as well
There was a problem hiding this comment.
I tried. However, if I mark this as #[inline(always)], the Rust compiler will decide not to inline another call inside this function. Then I marked another function as #[inline(always)], and then the Rust compiler will again decide not to inline yet another function. And this went on and on. So I decided to fix the inlining problem later, not in this PR, because the performance of generational GC doesn't seem to be affected by this PR.
| @@ -601,33 +601,33 @@ impl<VM: VMBinding> BasePlan<VM> { | |||
| pages | |||
| } | |||
|
|
|||
| pub fn trace_object<T: TransitiveClosure>( | |||
| pub fn trace_object<Q: ObjectQueue>( | |||
There was a problem hiding this comment.
Not sure if it is helpful to mark this as #[cold] or #[inline(never)]. This may reduce the inlined code size of the hot trace_object calls.
There was a problem hiding this comment.
Yes. It may reduce the inline code size. But I am not sure if we should mark it as #[cold] or #[inline(never)].
- The VM space (if exists) may not be cold.
- If
in_spaceis cheap and simple, inlining it should help skipping objects that are not in those spaces.
As we discussed in #559,
TransitiveClosureshould be split into two traits, one for object scanning, and the other for enqueuing objects. This PR is the latter: it replacesTransitiveClosurewith an object-enqueuing traitObjectQueue, and removeTransitiveClosurecompletely.With this change, the
trace_objectmethod now takes an&mut impl ObjectQueueparameter. ForProcessEdgesWork, it should pass&mut self.base().nodesinstead ofselftotrace_object.There is an alternative solution which uses the return value to indicates which object to enqueue. I think this PR is a more direct approach, because "enqueuing" is part of the semantics of
trace_object, and it is better to just expose a queue totrace_objectso it can queue, instead of letting the caller enqueue objects. Consequently, unlike the alternative solution, this PR cannot address the issue of "only updating edges when the object is actually moved" (#574). It shall be addressed in a separate PR.Closes: #559