- Introduction
- Objectives
- Dataset
- Data Wrangling & Exploratory Data Analysis EDA
- Feature Engineering
- Modeling with TensorFlow
- Future work
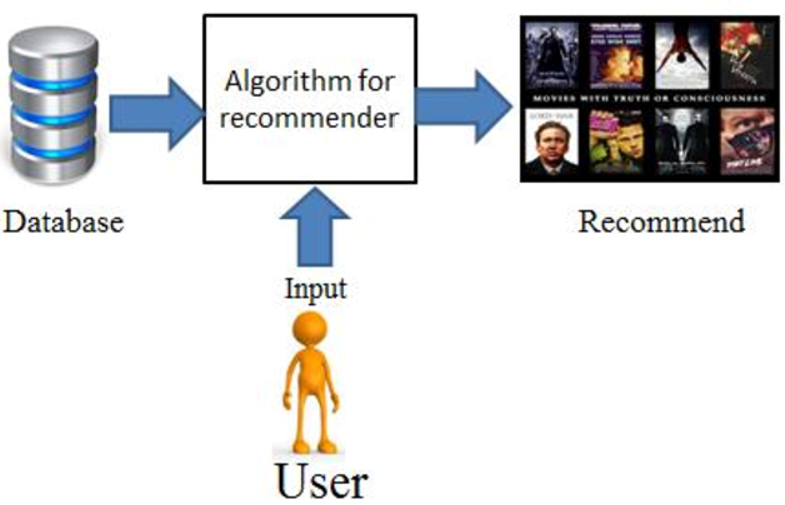
Recommendation platforms (Youtube, Netflix, Disney Plus...etc) are becoming part of our lives from e commerce suggesting customers goods that could be of interest. Simply put, recommender systems are algorithms designed to suggest relevant items to users (can be movies to watch, articles to read, products to buy or literally anything else depending on the type of industry). Recommendation systems are paramount in some industries for they can produce significant income boost when efficient but also they can be a way to stand out to competitors. The gist aim is for those systems tp produce relevant suggestions for the collection of objects/products that may be of interest to users/customers. General well-known examples of leaders in this realm include suggestions from Amazon books or Netflix. The architecture of such recommendation engines depends on the domain and basic characteristics of the available data.
To help customers find those movies, Google created a movie recommendation system called TensorFlow Recommender (TFRS). Its goal is to predict if a user might enjoy a movie based on how much they liked or disliked other movies. Those predictions are then used to make personal videos recommendations based on each user’s unique preferences.
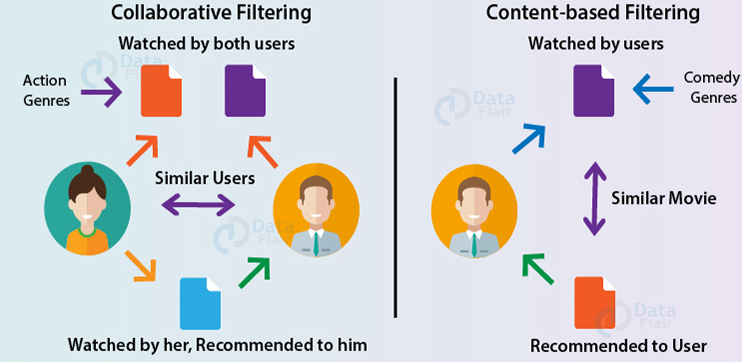
There 3 types of recommendation engines:
- Collaborative filtering.
- Content based Filtering.
- Hybrid (Combination of Collaborative and Content based Filtering).
This project aims to:
- Design a recommendation engine,
- Differentiate between implicit and explicit feedback and,
- Build a movie recommendation system with TensorFlow and TFRS.
Criteria Of Success
Generating a Movie Recommendation Engine with:
- The highest possible retrieval accuracy (i.e. Predicting Movies) and,
- With the lowest Loss/RMSE (Ranking Movies)
Constraints
TFRS can be classified as a relatively new package (several bugs have been reported depending on the version used). Based on my initial research and asking questions on official TFRS forums, I have decided not to use the latest version (2.7.0) but use an older version (2.5.0) instead that appears more stable for the type of work here
100k Movielens from TensorFlow is our main dataset for this project. Also, we used both datasets from Movielens website: movies metadata & credits.
MovieLens possesses a set of movie ratings from the MovieLens website, a movie recommendation service. This dataset was collected and maintained by GroupLens , a research group at the University of Minnesota. There are 5 versions included: "25m", "latest-small", "100k", "1m", "20m". In all of the datasets, the movies data and ratings data are joined on "movieId". The 25m dataset, latest-small dataset, and 20m dataset contain only movie data and rating data. The 1m dataset and 100k dataset contain demographic data in addition to movie and rating data.
movie_lens/100k can be treated in two ways:
- It can be interpreted as expressing which movies the users watched (and rated), and which they did not. This is a form of implicit feedback, where users' watches tell us which things they prefer to see and which they'd rather not see.
- It can also be seen as expressing how much the users liked the movies they did watch. This is a form of explicit feedback: given that a user watched a movie, we can tell roughly how much they liked by looking at the rating they have given.
-
Config description: This dataset contains 100,000 anonymous ratings of approximately 1,682 movies made by 943 MovieLens users who joined MovieLens. Ratings are in whole-star increments. This dataset contains demographic data of users in addition to data on movies and ratings.
-
This dataset is the second largest dataset that includes demographic data from movie_lens.
-
"user_gender": gender of the user who made the rating; a true value corresponds to male.
-
"bucketized_user_age": bucketized age values of the user who made the rating, the values and the corresponding ranges are:
- 1: "Under 18"
- 18: "18-24"
- 25: "25-34"
- 35: "35-44"
- 45: "45-49"
- 50: "50-55"
- 56: "56+"
-
"movie_genres": The Genres of the movies are classified into 21 different classes as below:
- 0: Action
- 1: Adventure
- 2: Animation
- 3: Children
- 4: Comedy
- 5: Crime
- 6: Documentary
- 7: Drama
- 8: Fantasy
- 9: Film-Noir
- 10: Horror
- 11: IMAX
- 12: Musical
- 13: Mystery
- 14: Romance
- 15: Sci-Fi
- 16: Thriller
- 17: Unknown
- 18: War
- 19: Western
- 20: no genres listed
-
"user_occupation_label": the occupation of the user who made the rating represented by an integer-encoded label; labels are preprocessed to be consistent across different versions
-
"user_occupation_text": the occupation of the user who made the rating in the original string; different versions can have different set of raw text labels
-
"user_zip_code": the zip code of the user who made the rating.
-
Download size: 4.70 MiB
-
Dataset size: 32.41 MiB
-
Auto-cached (documentation): No
-
Features:
FeaturesDict({
'bucketized_user_age': tf.float32,
'movie_genres': Sequence(ClassLabel(shape=(), dtype=tf.int64, num_classes=21)),
'movie_id': tf.string,
'movie_title': tf.string,
'raw_user_age': tf.float32,
'timestamp': tf.int64,
'user_gender': tf.bool,
'user_id': tf.string,
'user_occupation_label': ClassLabel(shape=(), dtype=tf.int64, num_classes=22),
'user_occupation_text': tf.string,
'user_rating': tf.float32,
'user_zip_code': tf.string,
})
Example:
| bucketized_user_age | movie_genres | movie_id | movie_title | raw_user_age | timestamp | user_gender | user_id | user_occupation_label | user_occupation_text | user_rating | user_zip_code |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 45.0 | 7 (Drama) | b'357' | b"One Flew Over the Cuckoo's Nest (1975)" | 46.0 | 879024327 | True | b'138' | 4 (doctor/health care) | b'doctor' | 4.0 | b'53211' |
* Config description: This dataset contains data of approximately 1,682 movies rated in the 100k dataset.
* Download size: 4.70 MiB
* Dataset size: 150.35 KiB
* Auto-cached ([documentation](https://www.tensorflow.org/datasets/performances#auto-caching)): Yes
* Features:
FeaturesDict({
'movie_genres': Sequence(ClassLabel(shape=(), dtype=tf.int64, num_classes=21)),
'movie_id': tf.string,
'movie_title': tf.string,
})
More information on TFRS
- TensorFlow Recommenders (TFRS) is a library for building recommender system models.
- It helps with the full workflow of building a recommender system: data preparation, model formulation, training, evaluation, and deployment.
- It's built on Keras and aims to have a gentle learning curve while still giving you the flexibility to build complex models.
TFRS makes it possible to:
- Build and evaluate flexible recommendation retrieval models.
- Freely incorporate item, user, and context information into recommendation models.
- Train multi-task models that jointly optimize multiple recommendation objectives.
TFRS is open source and available on Github.
To learn more, see the tutorial on how to build a movie recommender system, or check the API docs for the API reference.
On the one hand, the The Data wrangling step focuses on collecting or converting the data, organizing it, and making sure it's well defined. For our project we will be using the movie_lens/100k dataset from TensorFlow because it's a unique dataset with plenty of Metadata that's needed for this project. We'll focus in particular on:
- Cleaning NANs (If any), duplicate values (If any), wrong values and removing insignificant columns.
- Removing any special characters.
- Renaming some Column labels.
- Correcting some datatypes.
On the other hand, the Exploratory Data Analysis EDA Step will focus on:
- Getting familiar with the features in our dataset.
- Understanding the core characteristics of our cleaned dataset.
- Exploring the data relationships of all the features and understanding how the features compare to the response variable.
- Further analyzing interesting plots to deepen our understanding of the data.
Objective: to improve our cleaned Dataframe which was orginally from the Tensorflow Dataset: movie_lens/100k-ratings:
-
Fixing "movie_genres": formatting to a list.
-
Checking the "user_occupation_label": making sure that the classificiations match the documentation.
-
Adding 5 more features to the original Dataset: 'cast', 'director', 'cast_size', 'crew_size', 'imdb_id', 'release_date' and movie_lens_movie_id, from:
-
Removing all special characters or letter accents from certain columns.
-
Converting the Pandas dataframe to tensforflow datasets.
For this final notebook, we will be dealing with:
-
The Feature importance using Deep and Cross Network (DCN-v2)
-
Training multiple TensorFlow Recommenders.
-
Applying hyperparameters tuning where applicable to ensure every algorithm will result in the best prediction possible.
-
Finally, evaluating these Models.
Deep and cross network (DCN) came out of Google Research, and is designed to learn explicit and bounded-degree cross features effectively
- Large and sparse feature space is extremely hard to train.
- Oftentimes, we needed to do a lot of manual feature engineering, including designing cross features, which is very challenging and less effective.
- Whilst possible to use additional neural networks under such circumstances, it's not the most efficient approach. DCN is specifically designed to tackle all of the above challenges.
Feature Cross
Let's say we're building a recommender system to sell a blender to customers. Then our customers' past purchase history, such as purchased apples and purchased recipes books, or geographic features are single features. If one has purchased both apples and recipes books, then this customer will be more likely to click on the recommended blender. The combination of purchased apples and the purchased recipes books is referred to as feature cross, which provides additional interaction information beyond the individual features.
Cross Network
In real world recommendation systems, we often have large and sparse feature space. So, identifying effective feature processes in this setting would often require manual feature engineering or exhaustive search, which is highly inefficient. To tackle this issue, Google Research team has proposed DCN. It starts with an input layer, typically an embedded layer, followed by a cross network containing multiple cross layers that models explicitly feature interactions, and then combines with a deep network that models implicit feature interactions. The deep network is just a traditional multilayer construction. But the core of DCN is really the cross network. It explicitly applies feature crossing at each layer. And the highest polynomial degree increases with layer depth.
Deep & Cross Network
There are a couple of ways to combine the cross network and the deep network:
- Stack the deep network on top of the cross network.
- Place deep & cross networks in parallel.
Model Structure
We first train a DCN model with a stacked structure, that is, the inputs are fed to a cross network followed by a deep network.
Real-world recommender systems are often composed of two stages:
-
The retrieval stage (Selects recommendation candidates): is responsible for selecting an initial set of hundreds of candidates from all possible candidates.
- The main objective of this model is to efficiently weed out all candidates that the user is not interested in. Because the retrieval model may be dealing with millions of candidates, it has to be computationally efficient.
-
The ranking stage (Selects the best candidates and rank them): takes the outputs of the retrieval model and fine-tunes them to select the best possible handful of recommendations.
- Its task is to narrow down the set of items the user may be interested in to a shortlist of likely candidates.
Retrieval models are often composed of two sub-models:
The retrieval model embeds user ID's and movie ID's of rated movies into embedded layers of the same dimension:
-
A query model computing the query representation (normally a fixed-dimensionality embedding vector) using query features.
-
A candidate model computing the candidate representation (an equally-sized vector) using the candidate features.
-
As shown below, the two models are multiplied to create a query-candidate affinity scores for each rating during training. If the affinity score for the rating is higher than other candidates, then we can consider the model to be reasonable.
Embedded layer Magic
As discussed above, we might think of the embedded layers as just a way of encoding a way of forcing the categorical data into some sort of a standard format that can be easily fed into a neural network and usually that's how it's used but embedded layers are more than that!
The way they're working under the hood is every unique id is being mapped to a vector of n dimensions, but it's going to be like a vector of 32 floating point values and we can think of this as a position in a 32-dimensional space that represents the similarity between one user id and another or between one movie id and another so by using embeddied layers in this way we're getting around that whole problem of data sparsity and sparse vectors and at the same time, we're getting a measure of similarity so it's a very simple way of getting recommendation candidates.
The outputs of the two models are then multiplied together to give a query-candidate affinity score, with higher scores expressing a better match between the candidate and the query.
In this Model, we built and trained such a two-tower model using the Movielens dataset (100k Dataset):
- Getting our data and splitting it into a training and test set.
- Implementing a retrieval model.
- Fitting and evaluating it.
The Ranking
The ranking stage takes the outputs of the retrieval model and fine-tunes them to select the best possible handful of recommendations.
- Its task is to narrow down the set of items the user may be interested in to a shortlist of likely candidates.
TensorFlow Recommenders (TFRS) - Summary of all model's metrics:
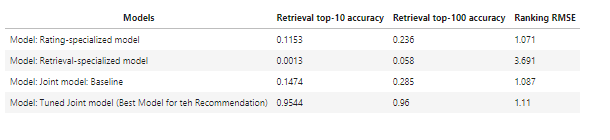
- Further optimizing existing Tensorflow Recommenders Classes to accommodate extra features.
- Additional fine-tuning needed to enhance retrieval prediction and reduce RMSE Ranking from the Joint Baseline Model (Multi-Task)
- Building an application