Hierarchical relational network for group activity recognition and retrieval. Mostafa S. Ibrahim, Greg Mori. European Conference on Computer Vision 2018
- Abstract
- Model
- Extra Experiments - CAD
- Graph Convolutional Network
- Code Scope and Requirements
- Data Format
- Installation
- License and Citation
- Poster and Powerpoint
Modeling structured relationships between people in a scene is an important step toward visual understanding. We present a Hierarchical Relational Network that computes relational representations of people, given graph structures describing potential interactions. Each relational layer is fed individual person representations and a potential relationship graph. Relational representations of each person are created based on their connections in this particular graph. We demonstrate the efficacy of this model by applying it in both supervised and unsupervised learning paradigms. First, given a video sequence of people doing a collective activity, the relational scene representation is utilized for multi-person activity recognition. Second, we propose a Relational Autoencoder model for unsupervised learning of features for action and scene retrieval. Finally, a Denoising Autoencoder variant is presented to infer missing people in the scene from their context. Empirical results demonstrate that this approach learns relational feature representations that can effectively discriminate person and group activity classes.
We put a lot of effort to make the model pictures speak about themselves, even without reading their text. You can get the whole paper idea from them.
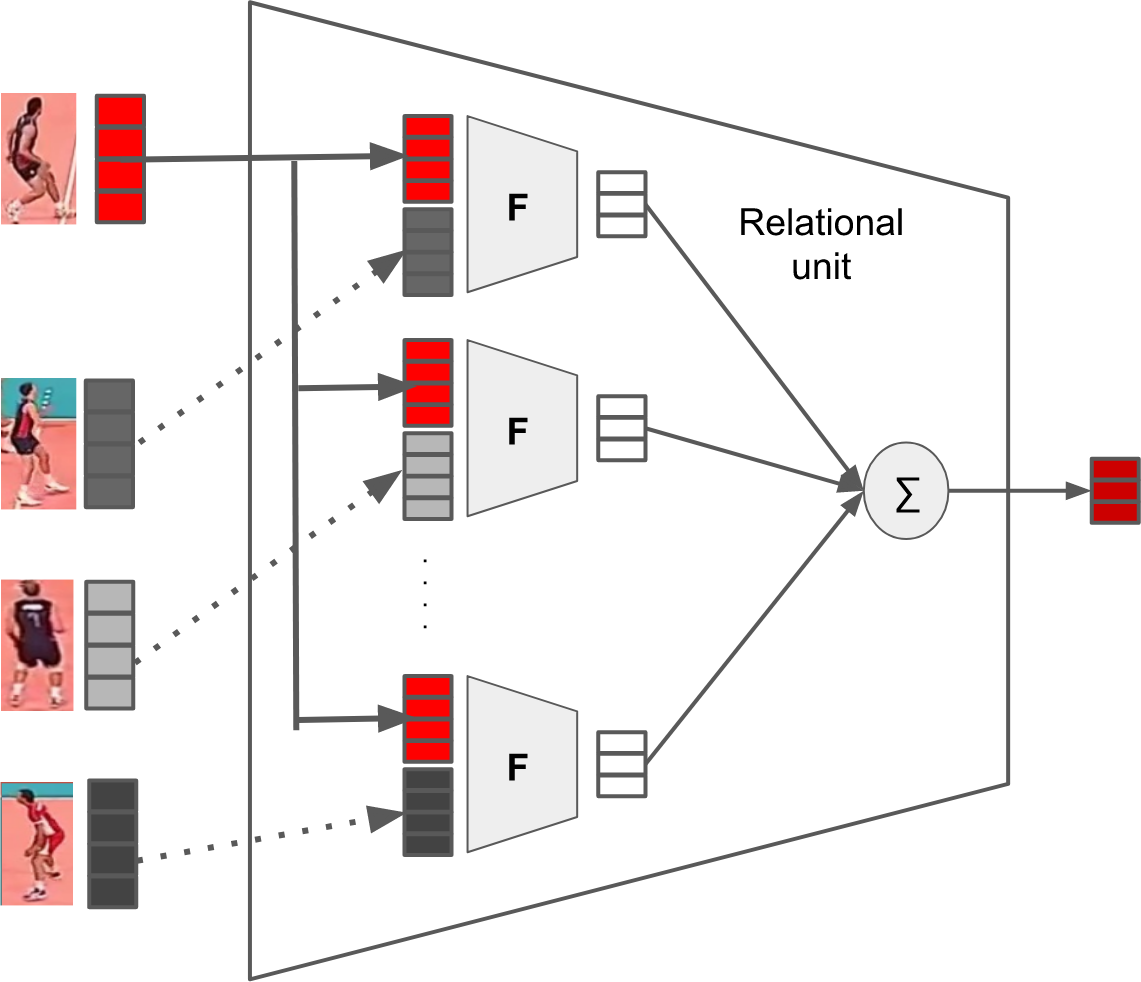
Figure 1: A single relational layer. The layer can process an arbitrary sized set of people from a scene, and produces new representations for these people that capture their relationships. The input to the layer is a set of

Figure 2: Relatinal unit for processing one person inside a relational layer. The feature vector for a person (red) is combined with each of its neighbours'. Resultant vectors are summed to create a new feature vector for the person (dark red).

Figure 3: Our relational network for group activity recognition for a single video frame. Given
Another application in unsupervised areas:

Figure 4: Our relational autoencoder model. The relationship graph for this volleyball scene is 2 disjoint cliques, one for each team and fixed for all layers.
The Collective Activity Dataset (CAD) consists of 44 videos and five labels used as both person action and group activity (crossing, walking, waiting, talking, and queueing). The majority activity in the scene defines the group activity. We followed the same data split, temporal window and implementation details as [25], including AlexNet features (due to the short time; faster to train/extract features).
We used a single relational layer with a simple graph: each 3 consecutive persons (spatially in horizontal dimension) are grouped as a clique. The layer maps a person of size 4096 to 128 and final person representations are concatenated. Our 9 time-steps model's performance is 84.2% vs. 81.5% from [25]. We did not compare with [3] as it uses much stronger features (VGG16) and extra annotations (pairwise interaction). Note that CAD has very simple "relations", in that the scene label is the label of the majority (often entirety) of the people in a scene. However, this result demonstrates that our relational layer is able to capture inter-person information to improve classification results.
- I have started reading in something called Graph Convolutional Network(GNN).
- Our paper is actually a variant of GNN. Our model input is a relational graph and initial CNN representations for the nodes to be updated based on the graph structure.
- Our model scales linearly with the # of edges in a graph. We don't use matrices to update the representations, but a shared MLP that learns an edge representation
- We administrate the importance of hierarchical graph representations by defining manually multiple graphs that express a hierarchy (applying this in Volleyball was easy using Graph Clique style)
- The provided code is a simplified version of our code. With simple effort, you can extend to whatever in the paper.
- The provided code doesn't contain the retrieval part.
- The provided example is for a single frame processing (though the Data Mgr can read temporal data, see Data below)
- The provided code is limited to clique style graphs, not general graphs. E.g. You can use it for a fully connected case or e.g. groups of cliques (e.g. in volleyball team 1 is clique and team 2 is another clique, or every 3 nearby players are a clique
- The provided code doesn't build the data, it just shows how to process the data using the relational network. Build initial representations for people is easy.
- You may use stage 1 in our C++ code for CVPR 16 to get such data (it build classifier, extra representations in the format below). You need to convert LevelDb to PKL format
- In src/data, a simple ready file for train and test in pkl format
- Provided code loads the whole data during the runtime. This might be problematic for some machines due to RAM issue. You may replace this part with another strategy.
- To understand how to structure data for a temporal clip, let's assume we have 12 persons, each clip is 10 frames. Ith Person in frame t is represented using 4096 features from VGG19
- Each entry in the pkl will be a single person representation (4096 features)
- The whole clip will be 12 * 10 = 120 rows
- The first 10 rows will be for the first person (his 10 representations corresponding to the 10 frames)
- The second 10 rows will be for the second person, and so on.
- If there are fewer people than 12 or a person is not available for all 10 frames, use zeros
- The next 120 rows will be for the second video clip.
- Be careful to not stack the data as 10 (steps) * 12 (persons), but as I clarified.
- The program reads the 120 lines, rearrange them as 10*(12*4096), that is 10 rows, each row has the whole scene people concatenated
- Lasagne 0.1, Theano 0.8.2, Python 2.7.11, CUDA 8.0
- Run the main of relational_network.py for an example that load attached basic Data.
Source code is released under the BSD 2-Clause license
@inproceedings{msibrahiECCV18RelationalNetwork,
author = {Mostafa S. Ibrahim and Greg Mori},
title = {Hierarchical relational network for group activity recognition and retrieval},
booktitle = {2018 European Conference on Computer Vision (ECCV)},
year = {2018}
}

Mostafa while presenting the poster.