Accessing the WER #181
Comments
|
The WER should appear at the end of the res.res files. If not, there could be an issue with the scoring script. Could you try to run the bash script "./RESULTS" in the main pytorch-kaldi repository to see what happens? |
|
I tried it ("./RESULTS") but still nothing. I checked the log.log file and saw this: Cannot open transcription file '/home/atos/kaldi/egs/WOLOF/s5/data/test/stm': No such file or directory at local/timit_norm_trans.pl line 74, line 61. and then checked the indicated log and saw this error message Error: Unable to stat GLM file '/home/atos/pytorch-kaldi/exp/WOLOF_MLP_1/decode_WOLOF_test_out_dnn1/scoring/glm_39phn' at /home/atos/kaldi//tools/sctk/bin/hubscr.pl line 265. and now I do not know how to fix it. |
|
It is a scoring problem due to some missing files. Which dataset are you
using?
Mirco
…On Sun, 17 Nov 2019 at 07:10, sawibrah ***@***.***> wrote:
I tried it ("./RESULTS") but still nothing. I checked the log.log file and
saw this:
Cannot open transcription file
'/home/atos/kaldi/egs/WOLOF/s5/data/test/stm': No such file or directory at
local/timit_norm_trans.pl line 74, line 61.
cp: cannot stat '/home/atos/kaldi/egs/WOLOF/s5/data/test/glm': No such
file or directory
run.pl: 10 / 10 failed, log is in
/home/atos/pytorch-kaldi/exp/WOLOF_MLP_1/decode_WOLOF_test_out_dnn1/scoring/log/score.*.log
and then checked the indicated log and saw this error message
Error: Unable to stat GLM file
'/home/atos/pytorch-kaldi/exp/WOLOF_MLP_1/decode_WOLOF_test_out_dnn1/scoring/glm_39phn'
at /home/atos/kaldi//tools/sctk/bin/hubscr.pl line 265.
and now I do not know how to fix it.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#181?email_source=notifications&email_token=AEA2ZVRWS36MQNUFKSJBVL3QUEYEZA5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEEIKNYA#issuecomment-554739424>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AEA2ZVSGV3DZU5ULWPY6FTTQUEYEZANCNFSM4JOEPB4A>
.
|
|
I am using my own dataset, but I followed the TIMIT tutorial. |
|
The scoring is looking for the gml file. In timit you find it in
data/test/glm. Do you have a glm file somewhere? Are you able to complete
scoring with the kaldi baseline?
Mirco
…On Sun, 17 Nov 2019 at 10:07, sawibrah ***@***.***> wrote:
I am using my own dataset, but I followed the TIMIT tutorial.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#181?email_source=notifications&email_token=AEA2ZVUNKDHPF24PPRLNPDLQUFM3NA5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEEIODIA#issuecomment-554754464>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AEA2ZVS4ZDEDCOFKASDTRZTQUFM3NANCNFSM4JOEPB4A>
.
|
|
I looked for glm file but did not see any. I have the decode_test_out_dnn1 folder with subfolders score,soring, log and a zip file lat1.gz. Inside each score_* I see 2 files ctm_39phn and stm_39phn. In the scoring folder I have *.ctm , *.ctm_39phn files, one stm_39phn file and a log folder |
|
i have the same question and i use TIMIT dataset and followed the tutorial , and there was nothing wrong or error in the log.log |
|
When you run the kaldi baseline, the data/test folder should look like this:
cmvn.scp feats.scp glm spk2utt text utt2num_frames wav.scp
conf frame_shift spk2gender stm utt2dur utt2spk
As you can see there are two files glm and stm that are created. In
particular, the stm contains the transcription in the format needed by the
scoring function and it should look like this
;; LABEL "O" "Overall" "Overall"
;; LABEL "F" "Female" "Female speakers"
;; LABEL "M" "Male" "Male speakers"
fdhc0_si1559 1 fdhc0 0.0 3.398438 <O,M> sil v ih zh uw ax l iy dh iy z ix
cl p r aa cl k s ix m ey dx ix vcl w ah dx iy w ix s f iy l iy n w ih cl th
ih n ih m s eh l f sil
fdhc0_si2189 1 fdhc0 0.0 2.252812 <O,M> sil y uw s ao dh ah m ao w iy z cl
t ix vcl g eh dh er vcl dh ow z y ih er z sil
fdhc0_si929 1 fdhc0 0.0 2.860812 <O,M> sil b ah cl t s ah cl ch cl k ey s
ih z epi w er ix n dh ax cl p ae s cl t ah n y uw zh uw el sil
fdhc0_sx119 1 fdhc0 0.0 3.027250 <O,M> sil dh ix m ih s cl k w ow w ix z r
iy cl t r ae cl t ix vcl d w ih cl th ix n ax cl p aa l ix vcl jh iy sil
fdhc0_sx209 1 fdhc0 0.0 2.566437 <O,M> sil m ay cl k el cl k ah l er vcl
dh ix vcl b eh vcl d r uw m w ao l w ix th cl k r ey aa n s sil
fdhc0_sx29 1 fdhc0 0.0 2.540812 <O,M> sil hh eh l cl p vcl g r ey vcl t ix
cl p ih cl k ix cl p eh cl k ix v cl p ix cl t ey dx ow z sil
.....
Do you have something like this in your folder? If not, one should figure
out why kaldi didn't create them.
Best,
Mirco
…On Tue, 19 Nov 2019 at 01:43, weienzhang ***@***.***> wrote:
i have the same question and i use TIMIT dataset and followed the tutorial
, and there was nothing wrong or error in the log.log
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#181?email_source=notifications&email_token=AEA2ZVUIYURT3NAWFF35CBDQUODJPA5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEENBTGQ#issuecomment-555358618>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AEA2ZVQ3DTD3UTAJW2PHNHLQUODJPANCNFSM4JOEPB4A>
.
|
|
That is my issue then, because I don't have the glm and stm files. I will try to figure out why. Thank you. |
|
Maybe it could be helpful to look where kaldi is creating them. I don't
remember exactly at which stage they are created.
Mirco
…On Tue, 19 Nov 2019 at 12:07, sawibrah ***@***.***> wrote:
That is my issue then, because I don't have the glm and stm files. I will
try to figure out why. Thank you.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#181?email_source=notifications&email_token=AEA2ZVROEQTPBQWR6FERC6DQUQMMLA5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEEO6PQA#issuecomment-555608000>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AEA2ZVTZYRSS3JOKF46IXVLQUQMMLANCNFSM4JOEPB4A>
.
|
|
Okay. |
the stm in my timit folder is the same as you and it seems like this: |


|
They both seems correct.
Maybe double check the following things:
1- Do you have a folder called "decode_TIMIT_test_*" that contains the
following subfolders?
lat.1.gz num_jobs score_10 score_3 score_5 score_7 score_9
log score_1 score_2 score_4 score_6 score_8 scoring
2- If yes, do you see some errors in the decode_TIMIT_test_*/log folder?
3- The folders decode_TIMIT_test_*/score* should contain the following
files:
ctm_39phn ctm_39phn.filt.hist.plt
ctm_39phn.filt.sbhist.plt
ctm_39phn.filt ctm_39phn.filt.lur ctm_39phn.filt.sgml
ctm_39phn.filt.det.dat.00 ctm_39phn.filt.pra ctm_39phn.filt.sys
ctm_39phn.filt.det.plt ctm_39phn.filt.prf stm_39phn
ctm_39phn.filt.dtl ctm_39phn.filt.raw stm_39phn.filt
ctm_39phn.filt.hist.dat ctm_39phn.filt.sbhist.dat
Do you have them?
Best,
Mirco
…On Tue, 19 Nov 2019 at 20:22, weienzhang ***@***.***> wrote:
When you run the kaldi baseline, the data/test folder should look like
this: cmvn.scp feats.scp glm spk2utt text utt2num_frames wav.scp conf
frame_shift spk2gender stm utt2dur utt2spk As you can see there are two
files glm and stm that are created. In particular, the stm contains the
transcription in the format needed by the scoring function and it should
look like this ;; LABEL "O" "Overall" "Overall" ;; LABEL "F" "Female"
"Female speakers" ;; LABEL "M" "Male" "Male speakers" fdhc0_si1559 1 fdhc0
0.0 3.398438 <O,M> sil v ih zh uw ax l iy dh iy z ix cl p r aa cl k s ix m
ey dx ix vcl w ah dx iy w ix s f iy l iy n w ih cl th ih n ih m s eh l f
sil fdhc0_si2189 1 fdhc0 0.0 2.252812 <O,M> sil y uw s ao dh ah m ao w iy z
cl t ix vcl g eh dh er vcl dh ow z y ih er z sil fdhc0_si929 1 fdhc0 0.0
2.860812 <O,M> sil b ah cl t s ah cl ch cl k ey s ih z epi w er ix n dh ax
cl p ae s cl t ah n y uw zh uw el sil fdhc0_sx119 1 fdhc0 0.0 3.027250
<O,M> sil dh ix m ih s cl k w ow w ix z r iy cl t r ae cl t ix vcl d w ih
cl th ix n ax cl p aa l ix vcl jh iy sil fdhc0_sx209 1 fdhc0 0.0 2.566437
<O,M> sil m ay cl k el cl k ah l er vcl dh ix vcl b eh vcl d r uw m w ao l
w ix th cl k r ey aa n s sil fdhc0_sx29 1 fdhc0 0.0 2.540812 <O,M> sil hh
eh l cl p vcl g r ey vcl t ix cl p ih cl k ix cl p eh cl k ix v cl p ix cl
t ey dx ow z sil ..... Do you have something like this in your folder? If
not, one should figure out why kaldi didn't create them. Best, Mirco
… <#m_1822525288341036566_>
On Tue, 19 Nov 2019 at 01:43, weienzhang *@*.***> wrote: i have the same
question and i use TIMIT dataset and followed the tutorial , and there was
nothing wrong or error in the log.log — You are receiving this because you
commented. Reply to this email directly, view it on GitHub <#181
<#181>?email_source=notifications&email_token=AEA2ZVUIYURT3NAWFF35CBDQUODJPA5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEENBTGQ#issuecomment-555358618>,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AEA2ZVQ3DTD3UTAJW2PHNHLQUODJPANCNFSM4JOEPB4A
.
the stm in my timit folder is the same as you and it seems like this:
[image: stm]
<https://user-images.githubusercontent.com/24769686/69200483-459a2d80-0b76-11ea-9ec3-bd917e9b828c.png>
but my glm looks like:
[image: glm]
<https://user-images.githubusercontent.com/24769686/69200728-00c2c680-0b77-11ea-9a96-e103487aa182.png>
i am wondering if it is correct
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#181?email_source=notifications&email_token=AEA2ZVVUGMYBY6V7YMPJXTDQUSGMRA5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEEQLLUI#issuecomment-555791825>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AEA2ZVS6AHASQCPAC7XM573QUSGMRANCNFSM4JOEPB4A>
.
|
Oh right i just want to tell you that my "decode_TIMIT_test_*"folder just have log and num_jobs, nothing else, |
I ran 2 models, the liGRU_mfcc and the MLP_mfcc, and one of them has "lat.1.gz" "num_jobs" and "log" and the liGRU only has "num_jobs" and "log", but the "log" of both folders have nothing |
|
It looks like a decoding problem. What you can do is to print the variable
cmd_decode of run.py (see line 608) and run the decoding command manually
in the terminal.
This way you can check directly for the possible decoding errors.
Best,
Mirco
…On Tue, 19 Nov 2019 at 21:14, weienzhang ***@***.***> wrote:
They both seems correct. Maybe double check the following things: 1- Do
you have a folder called "decode_TIMIT_test_*" that contains the
following subfolders? lat.1.gz num_jobs score_10 score_3 score_5 score_7
score_9 log score_1 score_2 score_4 score_6 score_8 scoring 2- If yes, do
you see some errors in the decode_TIMIT_test_*/log folder? 3- The folders
decode_TIMIT_test_*/score* should contain the following files: ctm_39phn
ctm_39phn.filt.hist.plt ctm_39phn.filt.sbhist.plt ctm_39phn.filt
ctm_39phn.filt.lur ctm_39phn.filt.sgml ctm_39phn.filt.det.dat.00
ctm_39phn.filt.pra ctm_39phn.filt.sys ctm_39phn.filt.det.plt
ctm_39phn.filt.prf stm_39phn ctm_39phn.filt.dtl ctm_39phn.filt.raw
stm_39phn.filt ctm_39phn.filt.hist.dat ctm_39phn.filt.sbhist.dat Do you
have them? Best, Mirco
… <#m_-4619576011059768120_>
On Tue, 19 Nov 2019 at 20:22, weienzhang *@*.*> wrote: When you run the
kaldi baseline, the data/test folder should look like this: cmvn.scp
feats.scp glm spk2utt text utt2num_frames wav.scp conf frame_shift
spk2gender stm utt2dur utt2spk As you can see there are two files glm and
stm that are created. In particular, the stm contains the transcription in
the format needed by the scoring function and it should look like this ;;
LABEL "O" "Overall" "Overall" ;; LABEL "F" "Female" "Female speakers" ;;
LABEL "M" "Male" "Male speakers" fdhc0_si1559 1 fdhc0 0.0 3.398438 <O,M>
sil v ih zh uw ax l iy dh iy z ix cl p r aa cl k s ix m ey dx ix vcl w ah
dx iy w ix s f iy l iy n w ih cl th ih n ih m s eh l f sil fdhc0_si2189 1
fdhc0 0.0 2.252812 <O,M> sil y uw s ao dh ah m ao w iy z cl t ix vcl g eh
dh er vcl dh ow z y ih er z sil fdhc0_si929 1 fdhc0 0.0 2.860812 <O,M> sil
b ah cl t s ah cl ch cl k ey s ih z epi w er ix n dh ax cl p ae s cl t ah n
y uw zh uw el sil fdhc0_sx119 1 fdhc0 0.0 3.027250 <O,M> sil dh ix m ih s
cl k w ow w ix z r iy cl t r ae cl t ix vcl d w ih cl th ix n ax cl p aa l
ix vcl jh iy sil fdhc0_sx209 1 fdhc0 0.0 2.566437 <O,M> sil m ay cl k el cl
k ah l er vcl dh ix vcl b eh vcl d r uw m w ao l w ix th cl k r ey aa n s
sil fdhc0_sx29 1 fdhc0 0.0 2.540812 <O,M> sil hh eh l cl p vcl g r ey vcl t
ix cl p ih cl k ix cl p eh cl k ix v cl p ix cl t ey dx ow z sil ..... Do
you have something like this in your folder? If not, one should figure out
why kaldi didn't create them. Best, Mirco … <#m_1822525288341036566_> On
Tue, 19 Nov 2019 at 01:43, weienzhang @.*> wrote: i have the same
question and i use TIMIT dataset and followed the tutorial , and there was
nothing wrong or error in the log.log — You are receiving this because you
commented. Reply to this email directly, view it on GitHub <#181
<#181> <#181
<#181>>?email_source=notifications&email_token=AEA2ZVUIYURT3NAWFF35CBDQUODJPA5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEENBTGQ#issuecomment-555358618>,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AEA2ZVQ3DTD3UTAJW2PHNHLQUODJPANCNFSM4JOEPB4A
. the stm in my timit folder is the same as you and it seems like this:
[image: stm]
https://user-images.githubusercontent.com/24769686/69200483-459a2d80-0b76-11ea-9ec3-bd917e9b828c.png
but my glm looks like: [image: glm]
https://user-images.githubusercontent.com/24769686/69200728-00c2c680-0b77-11ea-9a96-e103487aa182.png
i am wondering if it is correct — You are receiving this because you
commented. Reply to this email directly, view it on GitHub <#181
<#181>?email_source=notifications&email_token=AEA2ZVVUGMYBY6V7YMPJXTDQUSGMRA5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEEQLLUI#issuecomment-555791825>,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AEA2ZVS6AHASQCPAC7XM573QUSGMRANCNFSM4JOEPB4A
.
I ran 2 models, the liGRU_mfcc and the MLP_mfcc, and one of them has
"lat.1.gz" "num_jobs" and "log" and the liGRU only has "num_jobs" and
"log", but the "log" of both folders have nothing
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#181?email_source=notifications&email_token=AEA2ZVTJPXQGPW3LGMDXWITQUSMQZA5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEEQOHTQ#issuecomment-555803598>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AEA2ZVQRD4DO2YP6NDBAGULQUSMQZANCNFSM4JOEPB4A>
.
|
i print the cmd_decode and it looks like this: |

it seems like the '/home/zwe/Downloads/kaldi-master/pytorch-kaldi/exp/TIMIT_MLP_basic/exp_files/forward_TIMIT_test_ep*_ck*_out_dnn1_to_decode.ark' file is missing |
i ran the run_exp.py again, and the log.log file looks like this: |

And i think my timit stuff is alright because the result of timit has scores like: |
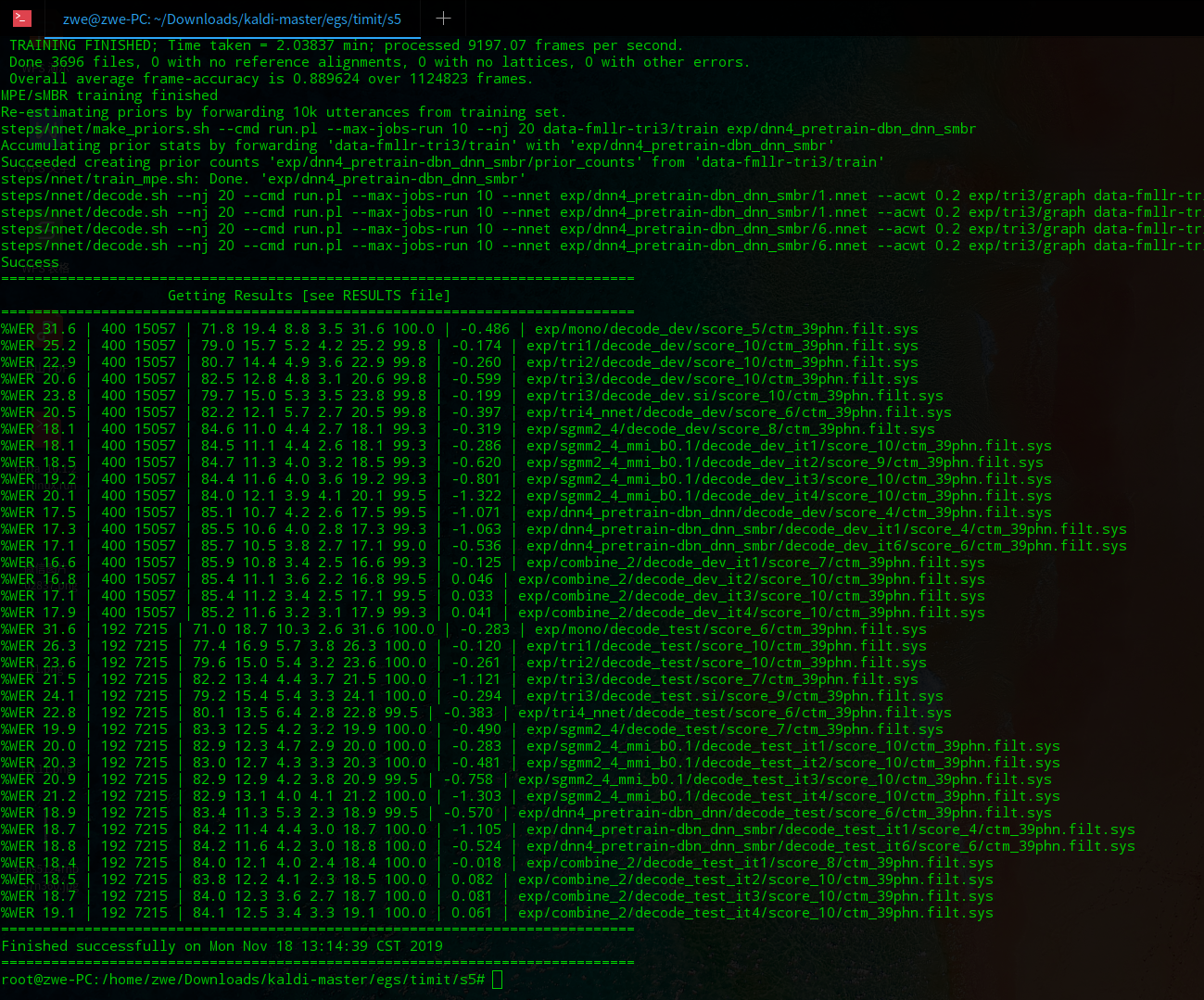
|
Do you have the KALDI_ROOT folder set in your .bash? (See timit tutorial).
It seems that the hubscr file is not found because of that.
…On Nov 20, 2019 20:55, "weienzhang" ***@***.***> wrote:
It looks like a decoding problem. What you can do is to print the variable
cmd_decode of run.py (see line 608) and run the decoding command manually
in the terminal. This way you can check directly for the possible decoding
errors. Best, Mirco
… <#m_6150652629831545749_>
On Tue, 19 Nov 2019 at 21:14, weienzhang *@*.*> wrote: They both seems
correct. Maybe double check the following things: 1- Do you have a folder
called "decode_TIMIT_test_" that contains the following subfolders?
lat.1.gz num_jobs score_10 score_3 score_5 score_7 score_9 log score_1
score_2 score_4 score_6 score_8 scoring 2- If yes, do you see some errors
in the decode_TIMIT_test_/log folder? 3- The folders decode_TIMIT_test_*/score*
should contain the following files: ctm_39phn ctm_39phn.filt.hist.plt
ctm_39phn.filt.sbhist.plt ctm_39phn.filt ctm_39phn.filt.lur
ctm_39phn.filt.sgml ctm_39phn.filt.det.dat.00 ctm_39phn.filt.pra
ctm_39phn.filt.sys ctm_39phn.filt.det.plt ctm_39phn.filt.prf stm_39phn
ctm_39phn.filt.dtl ctm_39phn.filt.raw stm_39phn.filt
ctm_39phn.filt.hist.dat ctm_39phn.filt.sbhist.dat Do you have them? Best,
Mirco … <#m_-4619576011059768120_> On Tue, 19 Nov 2019 at 20:22, weienzhang
*@*.*> wrote: When you run the kaldi baseline, the data/test folder
should look like this: cmvn.scp feats.scp glm spk2utt text utt2num_frames
wav.scp conf frame_shift spk2gender stm utt2dur utt2spk As you can see
there are two files glm and stm that are created. In particular, the stm
contains the transcription in the format needed by the scoring function and
it should look like this ;; LABEL "O" "Overall" "Overall" ;; LABEL "F"
"Female" "Female speakers" ;; LABEL "M" "Male" "Male speakers" fdhc0_si1559
1 fdhc0 0.0 3.398438 <O,M> sil v ih zh uw ax l iy dh iy z ix cl p r aa cl k
s ix m ey dx ix vcl w ah dx iy w ix s f iy l iy n w ih cl th ih n ih m s eh
l f sil fdhc0_si2189 1 fdhc0 0.0 2.252812 <O,M> sil y uw s ao dh ah m ao w
iy z cl t ix vcl g eh dh er vcl dh ow z y ih er z sil fdhc0_si929 1 fdhc0
0.0 2.860812 <O,M> sil b ah cl t s ah cl ch cl k ey s ih z epi w er ix n dh
ax cl p ae s cl t ah n y uw zh uw el sil fdhc0_sx119 1 fdhc0 0.0 3.027250
<O,M> sil dh ix m ih s cl k w ow w ix z r iy cl t r ae cl t ix vcl d w ih
cl th ix n ax cl p aa l ix vcl jh iy sil fdhc0_sx209 1 fdhc0 0.0 2.566437
<O,M> sil m ay cl k el cl k ah l er vcl dh ix vcl b eh vcl d r uw m w ao l
w ix th cl k r ey aa n s sil fdhc0_sx29 1 fdhc0 0.0 2.540812 <O,M> sil hh
eh l cl p vcl g r ey vcl t ix cl p ih cl k ix cl p eh cl k ix v cl p ix cl
t ey dx ow z sil ..... Do you have something like this in your folder? If
not, one should figure out why kaldi didn't create them. Best, Mirco …
<#m_1822525288341036566_> On Tue, 19 Nov 2019 at 01:43, weienzhang @.*>
wrote: i have the same question and i use TIMIT dataset and followed the
tutorial , and there was nothing wrong or error in the log.log — You are
receiving this because you commented. Reply to this email directly, view it
on GitHub <#181 <#181> <
#181 <#181>> <#181
<#181> <#181
<#181>>>?email_source=
notifications&email_token=AEA2ZVUIYURT3NAWFF35CBDQUODJPA
5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5
WW2ZLOORPWSZGOEENBTGQ#issuecomment-555358618>, or unsubscribe
https://github.com/notifications/unsubscribe-auth/
AEA2ZVQ3DTD3UTAJW2PHNHLQUODJPANCNFSM4JOEPB4A . the stm in my timit folder
is the same as you and it seems like this: [image: stm]
https://user-images.githubusercontent.com/24769686/69200483-459a2d80-
0b76-11ea-9ec3-bd917e9b828c.png but my glm looks like: [image: glm]
https://user-images.githubusercontent.com/24769686/69200728-00c2c680-
0b77-11ea-9a96-e103487aa182.png i am wondering if it is correct — You are
receiving this because you commented. Reply to this email directly, view it
on GitHub <#181 <#181> <
#181 <#181>
>?email_source=notifications&email_token=AEA2ZVVUGMYBY6V7YMPJXTDQUSGMRA
5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5
WW2ZLOORPWSZGOEEQLLUI#issuecomment-555791825>, or unsubscribe
https://github.com/notifications/unsubscribe-auth/
AEA2ZVS6AHASQCPAC7XM573QUSGMRANCNFSM4JOEPB4A . I ran 2 models, the
liGRU_mfcc and the MLP_mfcc, and one of them has "lat.1.gz" "num_jobs" and
"log" and the liGRU only has "num_jobs" and "log", but the "log" of both
folders have nothing — You are receiving this because you commented. Reply
to this email directly, view it on GitHub <#181
<#181>?email_source=
notifications&email_token=AEA2ZVTJPXQGPW3LGMDXWITQUSMQZA
5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5
WW2ZLOORPWSZGOEEQOHTQ#issuecomment-555803598>, or unsubscribe
https://github.com/notifications/unsubscribe-auth/
AEA2ZVQRD4DO2YP6NDBAGULQUSMQZANCNFSM4JOEPB4A .
And i think my timit stuff is alright because the result of timit has
scores like:
[image: timit]
<https://user-images.githubusercontent.com/24769686/69293826-04248380-0c45-11ea-9666-78c82597aa09.png>
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#181?email_source=notifications&email_token=AEA2ZVQ2NSEP6CPYUKDK4MDQUXTA3A5CNFSM4JOEPB4KYY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEEYH45Y#issuecomment-556826231>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AEA2ZVVZXUBCHLYJ37H4TBDQUXTA3ANCNFSM4JOEPB4A>
.
|
Thank you very much! Things went well now! I just type the KALDIROOT /kaldi-master with an extra 's'... |
Hello, I would like to get the wer. It is supposed to be the res.res file (when the training is done) but I can't see it there. I also check if there is file called ctm_39phn.filt.sys in the exp/TIMIT_MLP_basic5/decode_TIMIT_test_out_dnn1/score_* directory but nothing.
The text was updated successfully, but these errors were encountered: