spectro is a command line spectral analysis tool designed to visualise the distribution of streams of decimal numbers (not necessarily integers) representing something like latency, duration or size on the command line.
It samples data read from stdin and builds a rotated histogram, using ANSI colour codes to display the distribution as an ascii heat map.
It was inspired by this Sysdig tweet, and follows on from my distribution Awk script which displays an actual histogram (although it also has some realtime functionality).
Please be kind… this is my first play with Go, and I’m not proud of the code. I’d love to hear advice and critique from other Go developers. I’ve only tested this on on OS X and CentOS, so please raise an issue if you experience problems.
## Installing
If you wish to use the commands, you will need to have Go set up. Once you have installed Go you can get the commands by running:
go get github.com/mrmanc/spectro/normal github.com/mrmanc/spectro/pacemaker github.com/mrmanc/spectro/spectro
(dtrace example borrowed from this HeatMap tool)
Using the below (after adjusting spectro.go to use the exponential scale)…
$ sudo dtrace -qn 'syscall::read:entry { self->ts = timestamp; }
syscall::read:return /self->ts/ {
printf("%d\n", (timestamp - self->ts) / 1000); self->ts = 0; }' | spectro
will display something a bit like this in your terminal:
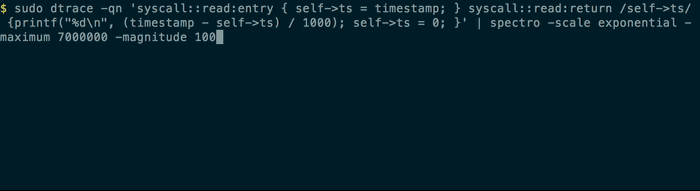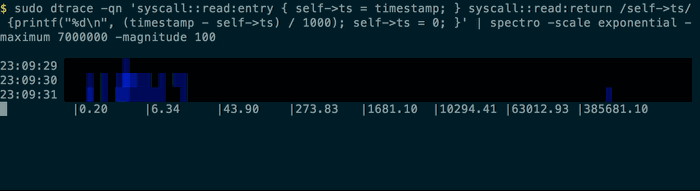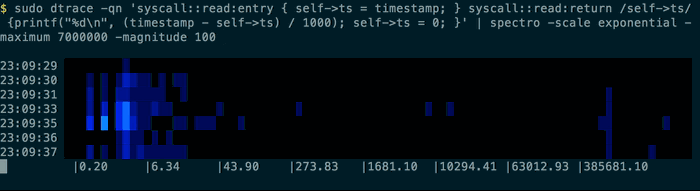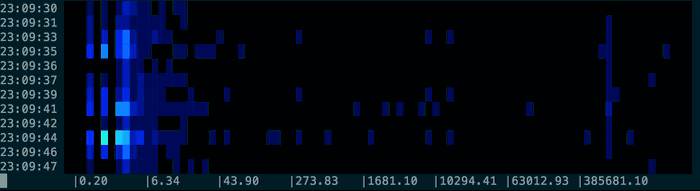
You can use the provided normal command to generate some test data based on a normal distribution:
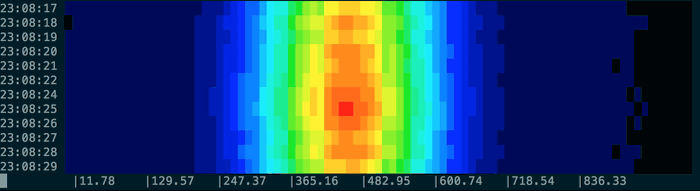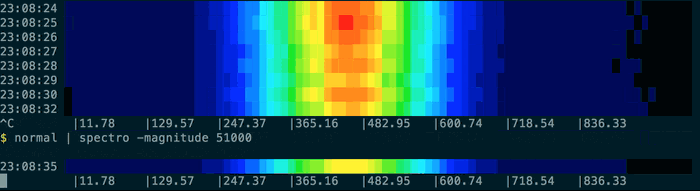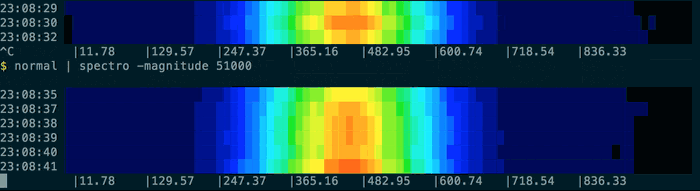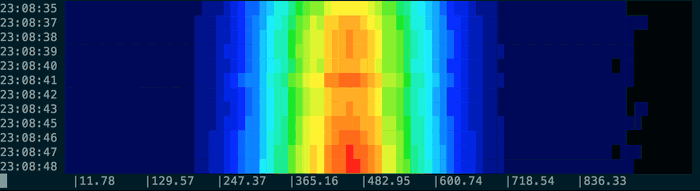
You can tell spectro to sample at intervals other than the default once-per-second using the sample-period-ms option. For example to sample once every ten seconds:
$ sudo dtrace -qn 'syscall::read:entry { self->ts = timestamp; }
syscall::read:return /self->ts/ {
printf("%d\n", (timestamp - self->ts) / 1000); self->ts = 0; }' | spectro -sample-period-s 10000
`
If you have historic logs with a formatted time in the line, you can use the pacemaker command to indicate to spectro how to sample the data. The pacemaker command will add extra lines to the streamed output as a signal to the spectro command.
Feel free to leave the time text in the output, so long as the number you wish to visualise is the last thing in the line. Pacemaker will look for a time matching something like this: 10:14:52. It’s tolerant of times out of order, but this will result in repeated periods.
For example, with a log file such as below, you could run cat test.log | pacemaker | spectro.
Tue Nov 11 10:14:52.130 duration=60.7
Tue Nov 11 10:14:53.130 duration=15.2
Tue Nov 11 10:14:53.131 duration=39.5
Tue Nov 11 10:14:53.140 duration=20.2
Tue Nov 11 10:14:53.237 duration=55.9
Tue Nov 11 10:14:56.845 duration=44.4
Tue Nov 11 10:14:58.493 duration=56.8
Tue Nov 11 10:14:58.510 duration=62.4
Tue Nov 11 10:14:58.510 duration=24.3
Tue Nov 11 10:14:58.510 duration=43.2
Tue Nov 11 10:14:58.510 duration=66.0
Tue Nov 11 10:14:59.199 duration=72.7
Using the provided sample.log and the pacemaker command you can play back activity:
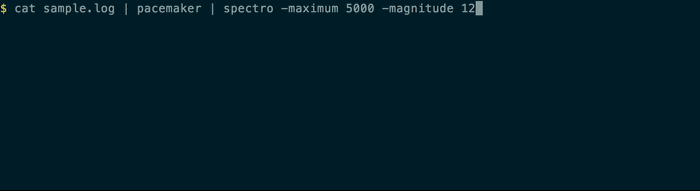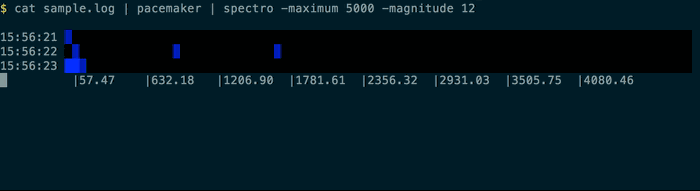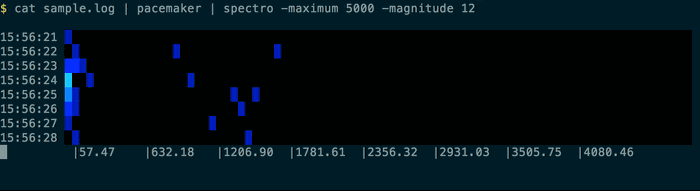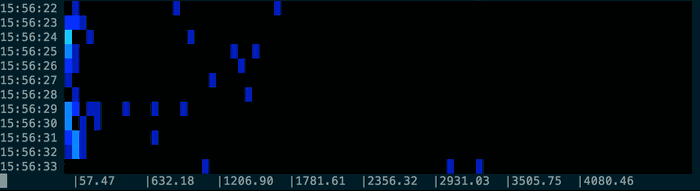
{kind=link}
{kind=link}
By default pacemaker will trigger a sample once per second, but you can adjust that by specifying the sample-period-s option. For example to sample once evety ten minutes you might run cat test.log | pacemaker -sample-period-s 600 | spectro
I would love to welcome improvements to spectro, no matter how large or small! If you want to further develop spectro fork the repo and see How to Write Go Code for advice if you are not familiar with Go.
- Potentially split the summarisation (histogram) functionality from the rendering, since it is useful on its own and can allow you to use much less space to store a replay of a period in plain text
- Normalise the amplitude using the time since last sample to smooth out results when processing is slow
- Try using a static logarithmic scale for the amplitude scaling to provide consistency and better resolution on small amplitudes
- Allow the user to switch scales dynamically when the command is running
- Use rank based rendering as suggested by this blog post by Dave Pacheco.