This repository contains the PyTorch implementation of the following paper:
Distinguishing Homophenes using Multi-head Visual-audio Memory for Lip Reading
Minsu Kim, Jeong Hun Yeo, and Yong Man Ro
[Paper]
- python 3.7
- pytorch 1.6 ~ 1.8
- torchvision
- torchaudio
- ffmpeg
- av
- tensorboard
- scikit-image
- pillow
LRW dataset can be downloaded from the below link.
The pre-processing will be done in the data loader.
The video is cropped with the bounding box [x1:59, y1:95, x2:195, y2:231].
To test the model, run following command:
# Testing example for LRW
python test.py \
--lrw 'enter_data_path' \
--checkpoint 'enter_the_checkpoint_path' \
--batch_size 80 \
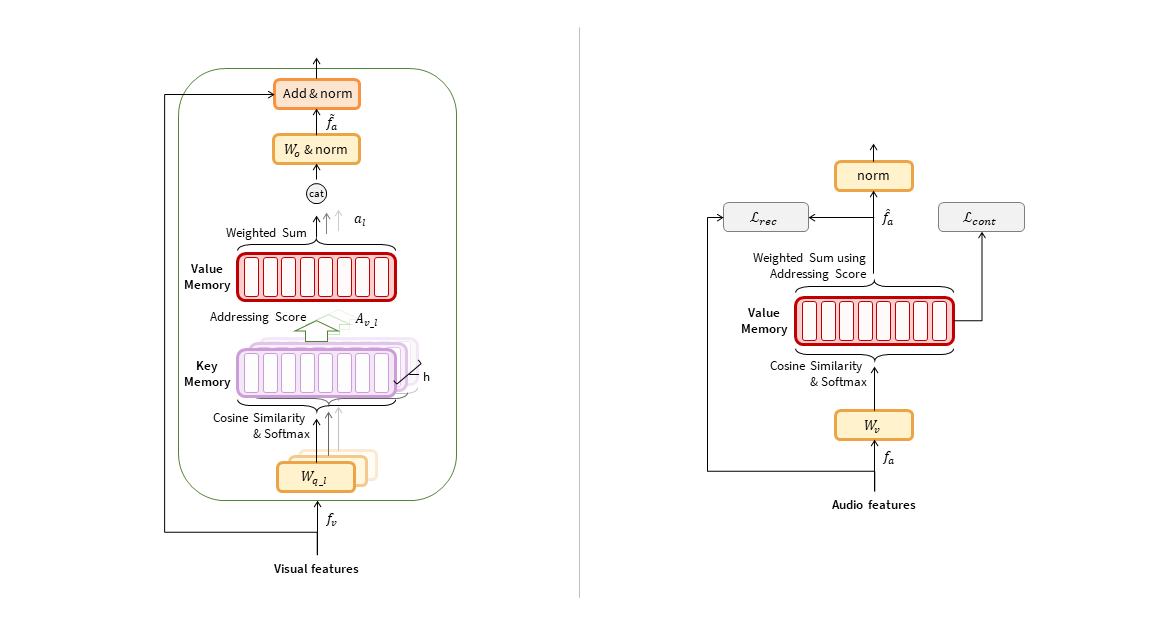
--radius 16 --n_slot 112 --head 8 \
--test_aug \
--gpu 0Descriptions of training parameters are as follows:
--lrw: training dataset location (lrw)--checkpoint: the checkpoint file--batch_size: batch size--test_aug: whether performing test time augmentation--distributed: Use DataDistributedParallel--dataparallel: Use DataParallel--gpu: gpu for using--lr: learning rate--n_slot: memory slot size--radius: scaling factor for addressing score--head: number of heads for visual-audio memory- Refer to
test.pyfor the other testing parameters
You can download the pretrained models.
Put the ckpt in './data/'
Pretrained model
To test the pretrained model, run following command:
# Testing example for LRW
python test.py \
--lrw 'enter_data_path' \
--checkpoint ./data/Pretrained_Ckpt.ckpt \
--batch_size 80
--radius 16 --slot 112 --head 8 \
--test_aug \
--gpu 0| Architecture | Acc. |
|---|---|
| Resnet18 + MS-TCN + Multi-head Visual-audio Mem | 88.508 |
To train the model, run following command:
# One GPU Training example for LRW
python train.py \
--lrw 'enter_data_path' \
--checkpoint 'enter_the_checkpoint_path' \
--batch_size 40 \
--radius 16 --n_slot 112 --head 8 \
--augmentations \
--mixup \
--gpu 0# Dataparallel GPU Training example for LRW
python train.py \
--lrw 'enter_data_path' \
--checkpoint 'enter_the_checkpoint_path' \
--batch_size 80 \
--radius 16 --n_slot 112 --head 8 \
--augmentations \
--mixup \
--dataparallel \
--gpu 0,1# Distributed Dataparallel GPU Training example for LRW
python -m torch.distributed.launch --nproc_per_node='# of GPU' train.py \
--lrw 'enter_data_path' \
--checkpoint 'enter_the_checkpoint_path' \
--batch_size 40 \
--radius 16 --n_slot 112 --head 8 \
--augmentations \
--mixup \
--distributed \
--gpu 0,1,2,3Descriptions of training parameters are as follows:
--lrw: training dataset location (lrw)--checkpoint_dir: the location for saving checkpoint--checkpoint: the checkpoint file--batch_size: batch size--augmentation: whether performing augmentation--distributed: Use DataDistributedParallel--dataparallel: Use DataParallel--mixup: Use mixup augmentation--gpu: gpu for using--lr: learning rate--n_slot: memory slot size--radius: scaling factor for addressing score--head: number of heads for visual-audio memory- Refer to
train.pyfor the other training parameters
If you find this work useful in your research, please cite the paper:
@inproceedings{kim2022distinguishing,
title={Distinguishing Homophenes using Multi-head Visual-audio Memory for Lip Reading},
author={Kim, Minsu and Yeo, Jeong Hun and Ro, Yong Man},
booktitle={Proceedings of the 36th AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada},
volume={22},
year={2022}
}