Regression in toJSON #572
Comments
|
Basically, non of your provided Files are affecting this. Commit 424560d causes the problem.
|
did you test that to be certain? accurate testing would require you to build master, but with a manually downgraded json-c version. |
|
Yes, i reverted changes by this commit and tested - expected result is returned:
|
|
Thanks for your bug report, we'll look into this. |
This comment has been minimized.
This comment has been minimized.
|
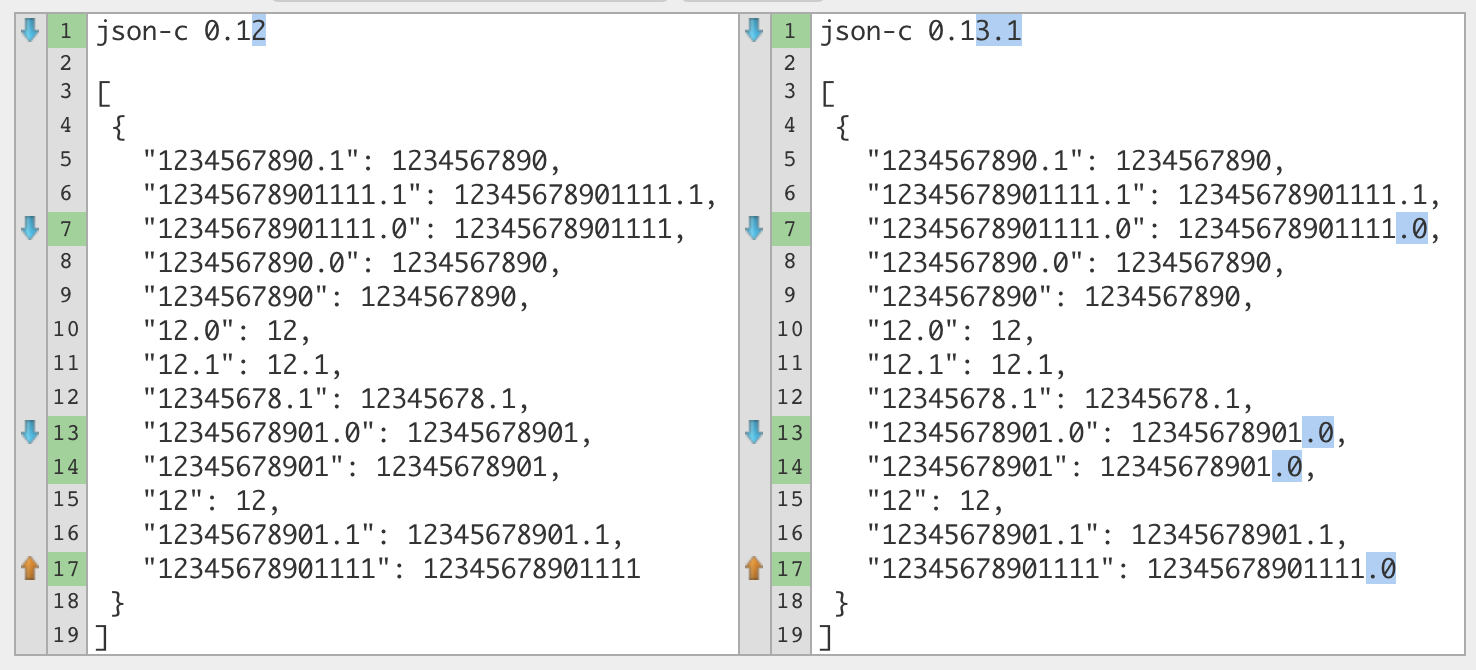
No I can certainly confirm this is an issue and has changed double behavior since the update which I did not test at the time. Sorry for any inconvenience. json-c 0.13.1 json-c 0.12 Since we haven't appended a trailing zero before, do we want to change behavior? Changing behavior requires scripters to force a Note that this behavior only occurs with a double. I guess we can raise a question why they changed this behavior in json-c library since the change seems very obvious and fairly easy to come across in the end. As for whether this is a truly code-breaking issue, I don't think so. Trailing zero or not, the number is the same. Only problem I can think of is if you're counting on it not having any non-numeric characters, but at that point you might as well handle that case separately... and another issue would be a slight increase in storage size as it appends two characters more than it used to. I thought I found the exact commits that caused this change in behavior but it seems it's somewhere deeper in the changes since 0.12 (modf produces same results). I'll try to dig up some more... |
|
Difference visualised
So the extra
Testing against Python, Lua stores all numbers (even numbers that happen to be integers) as doubles (in 5.1) and we shouldn't hide that behaviour. Yes, the behaviour has changed from before but I think it has changed for the better. There is no real problem with the change unless people are (for some reason) doing equality comparisons on JSON strings... which is kinda an odd thing to do. |
|
Hmm, our |
You mean the |
|
@patrikjuvonen @qaisjp I mean no disrespect but this is not a “better” behaviour. It’s nonstandard JSON. If you guys plan to keep the change then please at least have an option to disable this. It breaks certain pipelines that expect integers in the JSON(since that’s what we pass it). Furthermore, yes Lua can represent all integers as doubles but doesn't kt have lua_Integer data type for "long long" and a lua_isinteger check? It would become impossible to represent large integers if this change stays :( In a particular example, JSON files are outputted and picked up by Filebeat for elasticsearch for logging capabilities. Doubles are expected and without them completely break the pipeline. Please consider adding an option if you plan to make a nonstandard the default. |
Well, a digit of any kind in the fractional part is standard JSON according to the ECMA-404 JSON Data Interchange Standard Syntax. So it's not about the standard, it's about how we want our functions to behave, which in this case is indeed debatable. I don't know should we just remove the trailing zero part or wrap it around some flag. Either way we will end up changing json-c source code if we decide to do something about this. |
|
What I refer to is it's not standard compared to other JSON serializers to implicitly convert integers to a double. Anyways just hoping there will be someway soon to return to the previous functionality. I suppose the only way possible to represent a large integer as JSON in MTA is to now do some string manipulation to remove the |
|
@Chaosca No worries, we get what you mean. 😄
Both versions in this screenshot seem to have inconsistent behaviour so I'm not sure what we need to do here... @patrikjuvonen I've just noticed you've edited your comment to reflect that you're still looking for the correct commit. Thanks — keep us updated! 😊
Whoops, I made a typo in my comment and forgot the extra 0. I've edited my comment to fix this and have rectified which line of the screenshot I'm referring to. In addition, I would expect lines 9, 10, and 15 (in the screenshot) to have a trailing I find Both the old and new behaviour seems like weird behaviour to me... I think we should do whatever Python does. Running this: # Python
print(json.dumps(
{
"1234567890.1": 1234567890.1,
"12345678901111.1": 12345678901111.1,
"12345678901111.0": 12345678901111.0,
"1234567890.0": 1234567890.0,
"1234567890": 1234567890,
"12.0": 12.0,
"12.1": 12.1,
"12345678.1": 12345678.1,
"12345678901.0": 12345678901.0,
"12345678901": 12345678901,
"12": 12,
"12345678901.1": 12345678901.1,
"12345678901111": 12345678901111
},
indent=4, separators=(',', ': ')
))gives this: // JSON
{
"1234567890.1": 1234567890.1,
"12345678901111.1": 12345678901111.1,
"12345678901111.0": 12345678901111.0,
"1234567890.0": 1234567890.0,
"1234567890": 1234567890,
"12.0": 12.0,
"12.1": 12.1,
"12345678.1": 12345678.1,
"12345678901.0": 12345678901.0,
"12345678901": 12345678901,
"12": 12,
"12345678901.1": 12345678901.1,
"12345678901111": 12345678901111
}Also... I realise I'm being contradictory about the integers in Lua bit... I dunno anymore |
|
I did a more throughough test using the following Lua table: {
{
1,
1.0,
1.1,
1.123
},
{
12,
12.0,
12.1,
12.123
},
{
123,
123.0,
123.1,
123.123
},
{
1234,
1234.0,
1234.1,
1234.123
},
{
12345,
12345.0,
12345.1,
12345.123
},
{
123456,
123456.0,
123456.1,
123456.123
},
{
1234567,
1234567.0,
1234567.1,
1234567.123
},
{
12345678,
12345678.0,
12345678.1,
12345678.123
},
{
123456789,
123456789.0,
123456789.1,
123456789.123
},
{
1234567890,
1234567890.0,
1234567890.1,
1234567890.123
},
{
12345678901,
12345678901.0,
12345678901.1,
12345678901.123
},
{
123456789012,
123456789012.0,
123456789012.1,
123456789012.123
},
{
1234567890123,
1234567890123.0,
1234567890123.1,
1234567890123.123
},
{
12345678901234,
12345678901234.0,
12345678901234.1,
12345678901234.123
},
{
123456789012345,
123456789012345.0,
123456789012345.1,
123456789012345.123
},
{
1234567890123456,
1234567890123456.0,
1234567890123456.1,
1234567890123456.123
},
{
12345678901234567,
12345678901234567.0,
12345678901234567.1,
12345678901234567.123
},
{
123456789012345678,
123456789012345678.0,
123456789012345678.1,
123456789012345678.123
},
{
1234567890123456789,
1234567890123456789.0,
1234567890123456789.1,
1234567890123456789.123
},
{
12345678901234567890,
12345678901234567890.0,
12345678901234567890.1,
12345678901234567890.123
}
}Essentially the only difference I found was a number value containing 11 or more characters will always have at least one fractional digit in 0.13.1, but not in 0.12. Both share same sort of weird behavior here: {
123456789, -- becomes 123456789
123456789.0, -- becomes 123456789
123456789.1, -- becomes 123456789
123456789.123 -- becomes 123456789
},
{
1234567890, -- becomes 1234567890
1234567890.0, -- becomes 1234567890
1234567890.1, -- becomes 1234567890
1234567890.123 -- becomes 1234567890
}
Some topics that may be of interest:
|
Fix #572: Don't forcefully append .0 decimal when calling toJSON
In the newer builds after our update to MTASA server 1.5.6, toJSON no longer works as expected.
Large integers passed to toJSON will now return a float, which differs from the expected and previous behavior.
Outputs incorrectly by converting my integer to a float
[ 1234567890000.0 ]I'm unfamiliar with the codebase so bear with me.
The check here: https://github.com/multitheftauto/mtasa-blue/blame/40118f7875516304ff585c4c9ef360a7e887ca41/Client/mods/deathmatch/logic/lua/CLuaArgument.cpp#L912
Maybe fails?
https://github.com/multitheftauto/mtasa-blue/blame/40118f7875516304ff585c4c9ef360a7e887ca41/Shared/sdk/SharedUtil.Math.h#L47
Perhaps the value is too large? But this worked with 1.5.5, also it needs to work for larger ints because of the way we use it for milliseconds since epoch.
The text was updated successfully, but these errors were encountered: