Maximum size exceeded #34
Comments
|
Hi, Could you tell me, if, when you do
Caution: This message won't display if you initialize with If this message appears, could you please give me the result of the following command ? |
|
yes, get |

|
this error i get also when set 5gb anв else |
|
Thanks, and so what is the result of |
|
sorry |
|
i understood I have not much memory |
|
No its the contrary, 1% represents the used memory, and not the free memory. So it should be OK ... Can you tell me more about your computer ? |
|
exactly, mixed up |

|
so, from Pool, i can easily do processing |
|
Well, for your case I don't really understand what's happening, I have to dig more. Do you have the last version of Pandarallel ? (v1.2.0, because I changed things in case of multiple initializations in this version) |
|
i installed today lib |
|
I don't know if it's the same error, but I get the "Maximum size exceeded (2GB)" from Arrow. I run within Jupyter. pandarallel.initialize(shm_size_mb=10000)
decoded = df.myjsonfield.parallel_apply(json.loads) # ~4M rows---------------------------------------------------------------------------
ArrowInvalid Traceback (most recent call last)
<ipython-input-2-102322070224> in <module>()
28 denials_json = denials_json.append(d)
29
---> 30 decoded = df.myjsonfield.parallel_apply(json.loads)
~/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/pandarallel/utils.py in wrapper(*args, **kwargs)
61 """Please see the docstring of this method without `parallel`"""
62 try:
---> 63 return func(*args, **kwargs)
64
65 except _PlasmaStoreFull:
~/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/pandarallel/series.py in closure(series, func, *args, **kwargs)
69 def closure(series, func, *args, **kwargs):
70 chunks = chunk(series.size, nb_workers)
---> 71 object_id = plasma_client.put(series)
72
73 with ProcessPoolExecutor(max_workers=nb_workers) as executor:
~/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/pyarrow/_plasma.pyx in pyarrow._plasma.PlasmaClient.put()
~/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/pyarrow/serialization.pxi in pyarrow.lib.serialize()
~/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Maximum size exceeded (2GB) |
|
I am encountering same error as well. |
|
Well I cannot reproduce this issue on my computer. Could one of you send me the portion of code (with the dataframe) to reproduce this issue? Curiously, the "2GB" seems to be hard coded directly in Pyarrow error message: Thanks! |
|
I can't make it happen anymore, I'm afraid - could it be thanks to the 1.3.0 version? |
|
so, i think the problems with the shape string |
|
nice, get the new error |
|
@nalepae i think this can help u |
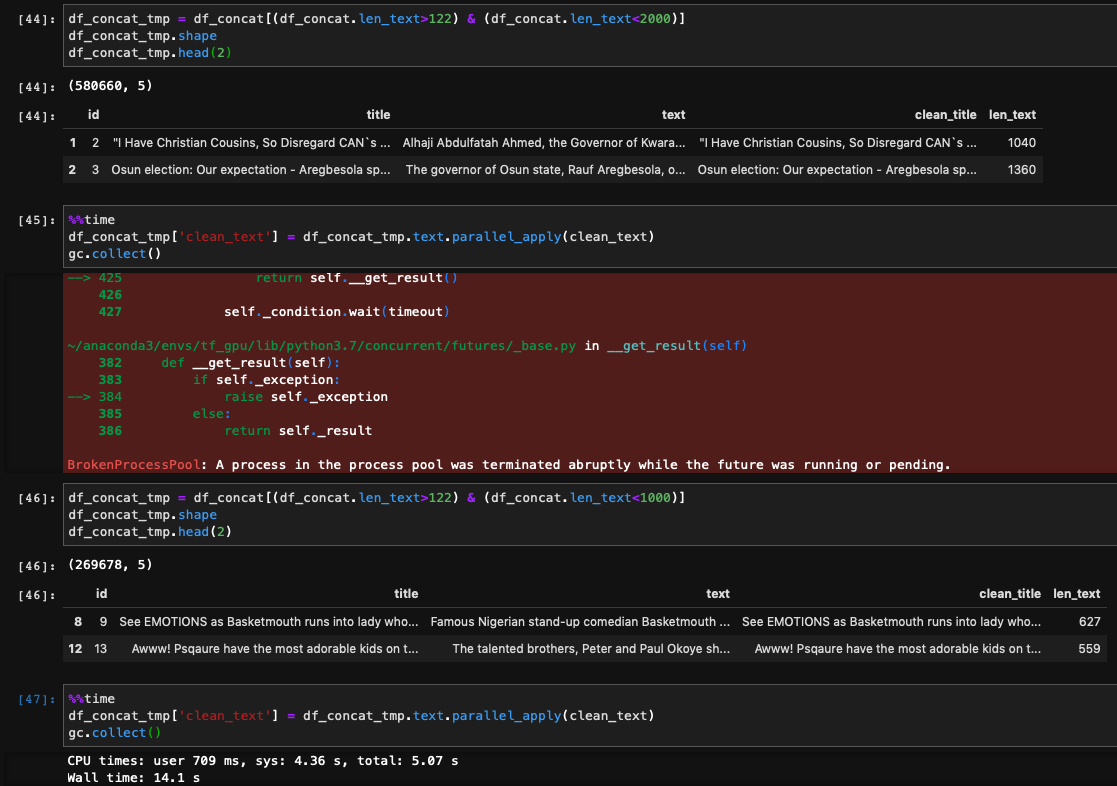
|
I'm having this issue as well on python 3.6.5 using an AWS Sagemaker Notebook. |
Like @nalepae mentioned here , the 2GB message is hardcoded into Arrow, so it doesn't mean you are only getting 2GB of memory. |
|
I have the same issue also. Machine: Setting: info: And i getting always the Error: |
|
I'm currently developing a new version of Pandarallel without PyArrow Plasma (which seems to be the cause of your bug). This version is not yet relased, but you can already try it by:
By default, this version of Pandarallel will try to use See the docstring of Note the In you chosoe to use
Note that I did not re-implemented (yet) progress bar and verbosity option in this version. To remove this develop version and retrieve the official one:
Please let me know if you encounter a new bug or if it works better now. Regards, Manu |
|
Fixed with It seems your bug comes from the usage of
|
hi
I set
pandarallel.initialize(shm_size_mb=10000)and after apply parallel_apply to my column i get the net errorMaximum size exceeded (2GB)why i get this message when i set more than 2gb?
The text was updated successfully, but these errors were encountered: