A question #8
Comments
|
Hi @Melika-Ayoughi, and thank you for your interest. I'm not sure I understood your concern. Please forgive me if it's not. D |
|
No it's not. I don't have problem with the order. So first of all W is the same for all lines, so instead of having W_xi, W_xf, W_hi, W_hf, ... u have one W. |
|
Ok, I think I see your point now. This repo implements the following dynamic: Which is significantly different from the one you reported. Thank you for pointing it out, we should mention it in the README. D |
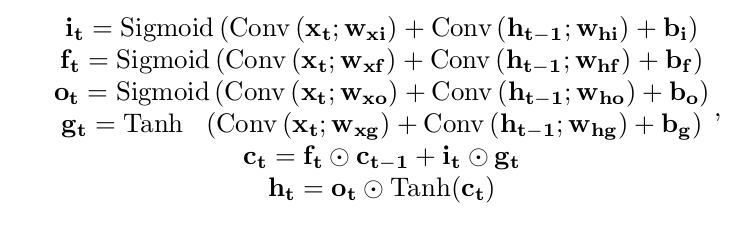
|
great! I still don't understand how your implementation has all these weights and not just one weight. can u explain that? because u only convolve x_t and w once. so I assumed there would only be one w and not 8! |
|
Sure! It's a common trick when dealing with the LSTM family.
Does this make sense? D |
The reported formulation of the ConvLSTM was first introduced in this paper (I believe): https://arxiv.org/pdf/1506.04214.pdf. |

|
Hi, I'm curious are there any particular reasons for implementing this variant of the LSTM model? Rather than the original one from the paper https://arxiv.org/pdf/1506.04214.pdf? I'm specifically asking about using Thank you! |
I have a question regarding your implementation:

As I understood the original convolutional lstm formulation is as follows:
But in your implementation, u used only one convolution layer. I don't understand how these 2 correspond with each other. because in the formulation, c is only used in the Hadamard product and not in convolutions, but here c and h are both used in convolutions.
in fact, all weights are shared for all 4 formulas, although there are 11 weights in the original formula.
The text was updated successfully, but these errors were encountered: