Integrator performs much better with a recurrent transform of 1.12 - 1.15 #114
Comments
|
Very useful..... I'd be curious to look at whether this is mostly due to the U/V overflow, or due to the V being reset to zero, or due to some other problem.... |
|
I don't think it's due to a bug per se, I think Loihi tuning curves are consistently lower than the tuning curves we're used to in Nengo, which we try to account for in decoder solving, but regardless at a given x a neuron is only ever going to fire at the rate you would expect in Nengo, or lower than that rate due to the discretization. Given that, it's not too surprising that upping the strength on the connection would help. I think any kind of overflow would give a much worse RMSE, but that's just a guess. |
|
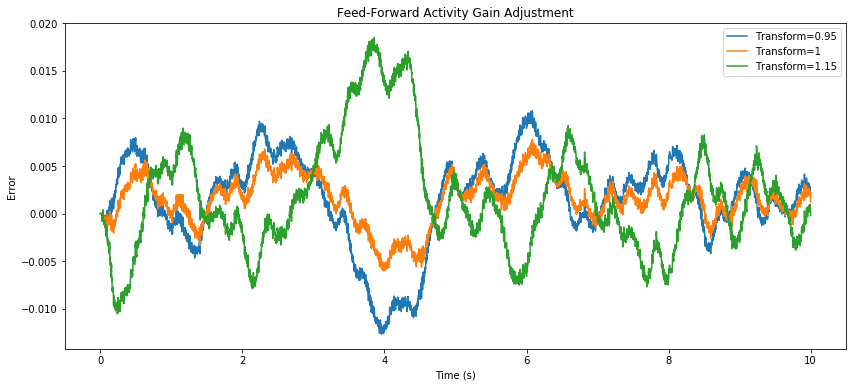
What are some of the challenges when it comes to using the quantized version of their neuron model to estimate the tuning curves? I haven't looked at this part of the code, but thinking purely about the emulator, could we do something like However, these questions might not tap into what's going on here, as I'm seeing, in the feed-forward case, that an output transform of 1 is better than 1.15. Note that, by linearity, applying a transform to the probed value is equivalent to rescaling the decoders, which in turn is equivalent to rescaling the y-axis on the tuning curves. And what we're seeing here is that the transform that makes things best for the recurrent case actually makes things worse for the feed-forward case.
(Note: y-axis is error.) From this, I'm thinking that a tuning shift from quantization error is not the main problem. It seems as though there's something more subtle going on pertaining to the dynamics of the system. This is not to rule out quantization effects as entirely irrelevant, however, as they could still play some important role in the context of a recurrent feedback loop. import numpy as np
import matplotlib.pyplot as plt
import nengo
import nengo_loihi; nengo_loihi.set_defaults()
from nengolib import DoubleExp
sim_t = 10
freq = 5
rms = 0.3
tau_conn = 0.1
tau_probe = 1.0
with nengo.Network() as model:
u = nengo.Node(nengo.processes.WhiteSignal(period=sim_t, high=freq, rms=rms, y0=0))
x = nengo.Ensemble(100, 1)
nengo.Connection(u, x, synapse=tau_conn)
p_x = nengo.Probe(x, synapse=tau_probe)
p_u = nengo.Probe(u, synapse=DoubleExp(tau_conn, tau_probe))
with nengo_loihi.Simulator(model) as sim:
sim.run(sim_t)
plt.figure(figsize=(14, 6))
plt.title("Feed-Forward Activity Gain Adjustment")
for transform in (0.95, 1, 1.15):
plt.plot(sim.trange(), transform*sim.data[p_x] - sim.data[p_u],
label="Transform=%s" % transform)
plt.legend()
plt.xlabel("Time (s)")
plt.ylabel("Error")
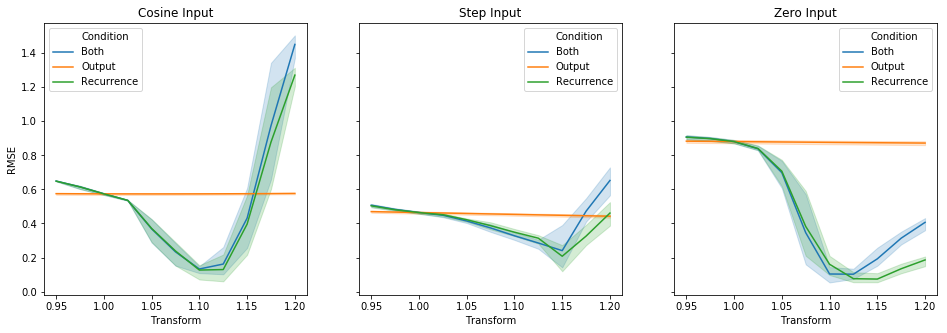
plt.show()To get a better understanding of what could be going on here, I re-ran the initial experiment at the top, in three different conditions: (1) varying only the output gain, similar to the above feed-forward experiment, (2) varying only the recurrent gain (as done in the original post), and (3) varying both gains together -- while keeping everything else fixed. Each subplot corresponds to a different input type, and each line is a separate condition. full_data = defaultdict(list)
for label, data in (('Both', data_both), ('Output', data_output), ('Recurrence', data_rec)):
for name, column in data.items():
full_data[name].extend(column)
full_data['Condition'].extend([label] * len(column))
df = DataFrame(full_data)
fig, ax = plt.subplots(1, 3, figsize=(16, 5), sharey=True)
for i, desc in enumerate(('Cosine', 'Step', 'Zero')):
ax[i].set_title("%s Input" % desc)
sns.lineplot(data=df[df['Input'] == desc], ax=ax[i],
x="Transform", y="RMSE", hue="Condition", ci=95)
fig.show()
Adjusting only the recurrence seems slightly better than adjusting both in some cases, although the 95% confidence intervals overlap at the optimal values. This makes sense when you look at the feed-forward results, since the difference in error there is relatively quite small. Taken together with the feed-forward observation, this appears to me to be consistent with there being dynamics other than |
That sounds like an excellent idea. I don't think we have a built-in way of probing the PSC at the moment, but it's definitely available from the chip. At the moment we probe the |
Conveniently, I added this in 4bec822 yesterday for my own purposes. You can probably cherry-pick it to your own branch if you want to play around with probing input currents. |
|
I've done some exploring. I think this behaviour is related to a number of factors in the overall discretization done by the chip, but I've found one major factor, and the good news is I think I can fix it. In I was computing these values based on the ideal math, which is what would happen if we had real values multiplied by Taking this rounding into account when computing u/v infactors seems to help integrator performance considerably. Now I just have to figure out an efficient way to compute these new values, as well as good starting conditions. (Since the amount of rounding depends on the starting value of the series, choosing a good initial value is important. For example, the 7, 3, 1 series from before exhibits much more rounding with respect to the sum of the series than 70, 35, 17, ... The most conservative choice here is the maximum possible values for voltage and current. This assumes that their full dynamic range is being used. But to know their actual dynamic range is very difficult without running a simulation.) |
|
Thanks for looking into this in detail. Sounds like a very promising lead. There may already be some literature on this subject that might help. A quick Google search revealed this for instance: https://www.researchgate.net/publication/262361908_On_the_verification_of_hybrid_DEVS_models (see Figure 2) which, from my brief skim, appears to give a method for mapping an ideal exponential decay onto a quantized one. From what I understand, this would be like trying to find a different decay value that maintains approximately the same trace as the ideal -- then you could stick to using your ideal math. But I haven't looked that closely, and there might be better stuff out there to look at. Using the term "quantized" or "quantization" should give you much more relevant search material than "discretization" in this context, as the former typically refers to truncation/rounding of values due to limited bit-precision, while the latter typically refers to discretization in time when converting from continuous-time to discrete-time. |
|
This issue was auto-closed by #124, which at least partially addresses the issue. If there are remaining issues related to integrators, I think it'd be best to open up a new issue, as this thread's gotten relatively long already, though feel free to reopen if anyone thinks it's important to keep all of the integrator issues in one place. |
I did a little benchmarking of an integrator network, for several different inputs:
I measured the RMSE across multiple trials with different seeds, while varying the gain on the recurrent feedback.
For the reference simulator, a recurrent transform of 1 is optimal. But here, I'm getting 1.12 - 1.15, depending on the kind of input. I'm not using any interneurons, and I'm using a fairly long time-constant (100 ms).
Might be useful to eventually have a collection of similar benchmarks in a regression test framework.
Also see #90 which may be related.
The text was updated successfully, but these errors were encountered: