The architecture of this app is inspired by and (generally and hopefully) follows the following architectures and patterns:
- Flux/redux.
- Clean architecture.
- Unidirectional data flow.
- MVVM.
- Android app architecture by Google.
- I went back to this guide frequently, so the overall design is quite close, except for details like the pagination mechanism or the concept of mutable and immutable data sources.
- Protocol-based programming.
- Dependency injection.
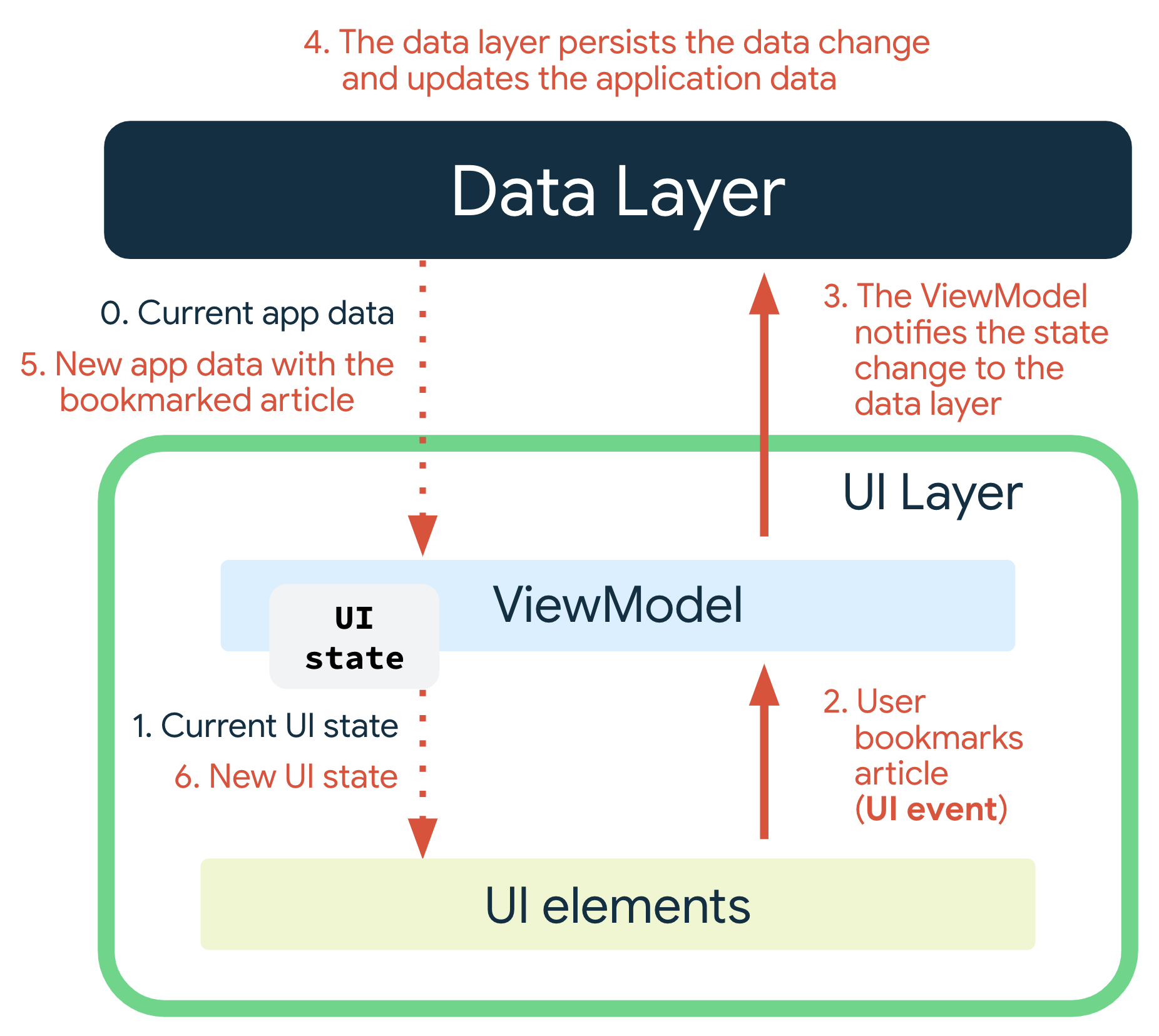
The architecture consists of 2 layers: Data and UI. This page explains them well.
- Data layer:
- Repository:
- The storefront for anything related to its data/model objects. It supports data querying (with a generic pagination mechanism built-in) as well as modification. Right now each repository has 1 or more data sources, but I may, later on, change it so that each would have only 1 data source and is composable (i.e a repository may have sub-repositories).
- Data source:
- Immutable data source: provides data querying with pagination. The data can come from different sources, like backend API or a local non-persistent/persistent store.
- Mutable data source: extends immutable data source and provides data modification.
- Network client: Used by a remote data source to make network requests. A concrete implementation can use URLSession but doesn't have to.
- Model: Immutable model objects.
- Repository:
- UI layer:
- View Model:
- Responsible for sending commands to its repository for data querying and modification, be notified when the data comes back and turns it into an immutable UI state.
- View: responsible for displaying the information encapsulated in a UI state. Any events triggered by the user, like bookmarking, will invoke a callback embedded into the UI state to communicate back to the View Model.
- View Model:
Here are the protocols of the components and how they fit together:
[Views] -- [ComicListViewModel] -- [ComicRepository] -- [ComicDataSource] -- [NetworkClient]
In general, the data flows from the left all the way to the right in the above (ugly) diagram and back, forming a cycle/loop:
- Commands triggered by the UI or user flow from the Views to the View Model to the repository and data source(s) via callbacks and function calls.
- Once a command is finished and new data comes back, it comes in the form of events delivered by Combine's publishers.
- For example, RemoteComicDataSource delivers a new page of comics as part of the output of its batch fetching publisher. The repository will get that output and update its backing "comics" array. Then because the view model observes that array using the array's publisher, it will receive an event and compose a new UI state. Finally, because the views observe that UI state, they will in turn get an event and update too.
- Bookmarking a comic works similarly:
(Source)
- Data predictability and consistency
- Testability
- For example, RemoteComicDataSourceTests don't hit the network/backend because I can inject a mock NetworkClient that returns the expected response(s) or throws error(s).
- Swappable and extensible components:
- For example, URLSessionNetworkClient uses URLSession under the hood, but I can swap it with something that uses Cronet or Envoy Mobile. I can have a LocalComicDataSource that persists its data using CoreData or the file system. And I think I can have a thin wrapper that implements the ComicRepository protocol and encapsulates Apollo with GraphQL. I can even swap them at run-time and run A/B tests.
- Reusability:
- For example, to support a feed of the latest comics from backend and a feed of bookmarked comics, I was able to reuse the same views, view model, and repository concrete implementations (see xkcdApp).
- For the latest feed, I gave the repository a remote data source for querying and a local data source for bookmarking. Bookmarking after all is simply the act of adding a comic to specific local storage, like a "Bookmarks" DB table or file.
- The bookmarks feed is powered by a repository with that same local data source instance for both querying and bookmarking.
- Since the 2 feeds share the same local data source instance, data consistency is guaranteed.
- LocalComicDataSource can also be used to support new features like offline reading. Just give it a different DB table or file name.
- For example, to support a feed of the latest comics from backend and a feed of bookmarked comics, I was able to reuse the same views, view model, and repository concrete implementations (see xkcdApp).
There is a generic pagination mechanism built into the data source protocol. This makes it easy to query the data regardless of the actual backing store. It works like this:
- Whenever a batch is requested, the data source will return the data along with a "bookmark". To query the next page, the client embeds that bookmark into the next batch request.
- The bookmark itself is a protocol. Each data source is responsible for its own concrete implementation of this protocol and knows how to use it for the next page. For example:
- RemoteComicDataSource's bookmark contains the id of the next batch's first comic. The id runs from N to 1.
- On the other hand, LocalComicDataSource's bookmark contains the array index of the next batch's first comic. And so the index runs from 0 to (N - 1).
- The bookmark itself is a protocol. Each data source is responsible for its own concrete implementation of this protocol and knows how to use it for the next page. For example:
- The pagination protocol requires two functions: fetch the first page and fetch the next page(s).
- For RemoteComicDataSource, since xkcd JSON API only supports fetching a single comic at a time, fetching the first page means loading the latest comic, then using its id to load the remaining comics in parallel. Fetching one of the next pages means loading individual comics in parallel. The resulting comics are then collected and sorted to form a page.
- For LocalComicDataSource, fetching the pages is straightforward since we control how the data is stored and queried.
- Prewarming: The repository and data source protocols have a prewarm function that can be called very early on, before they are injected to any View Model. Prewarming includes tasks such as warming up connections to backend and local DB and fetching the first page. Telling the repository and data source(s) to prewarm early helps to speed up the first data request when the UI finally makes it.
The structure follows the overall architecture closely. Each layer/component lives in its own directory.
As the project gets bigger, each feature will probably have its own directory within each component directory. For example, the view model(s) for Home Feed will live in a HomeFeed directory within ViewModels, and the views will live in a HomeFeed directory in Views.
Swift, Combine, and SwiftUI. No 3rd-party dependencies.
It's worth noting that I'm new to all of the above technologies, so there are mistakes or bad practices here and there. Please point them out!