Code and Pre-Processed data for our paper in SDU AAAI 2022 titled: CABACE: Injecting Character Sequence Information and Domain Knowledge for Enhanced Acronym and Long-Form Extraction
Acronyms and long-forms are commonly found in research documents, more so in documents from scientific and legal domains. Many acronyms used in such documents are domain-specific, and are very rarely found in normal text corpora. Owing to this, transformer-based NLP models often detect OOV (Out of Vocabulary) for acronym tokens, especially for non-English languages, and their performance suffers while linking acronyms to their long forms during extraction. Moreover, pre-trained transformer models like BERT are not specialized to handle scientific and legal documents. With these points being the overarching motivation behind this work, we propose a novel framework CABACE: Character-Aware BERT for ACronym Extraction, which takes into account character sequences in text, and is adapted to scientific and legal domains by masked language modelling. We further use an objective with an augmented loss function, adding max loss and mask loss terms to the standard cross-entropy loss for training CABACE. We further leverage pseudo labelling and adversarial data generation to improve the generalizability of the framework. Experimental results prove the superiority of the proposed framework in comparison to various baselines. Additionally, we show that the proposed framework is better suited than baseline models for zero-shot generalization to non-English languages, thus reinforcing the effectiveness of our approach. Our team BacKGProp secured the highest scores on the French dataset, second-highest on Danish and Vietnamese, and third-highest in English-Legal dataset on the global leaderboard for the acronym extraction (AE) shared task at SDU AAAI-22.
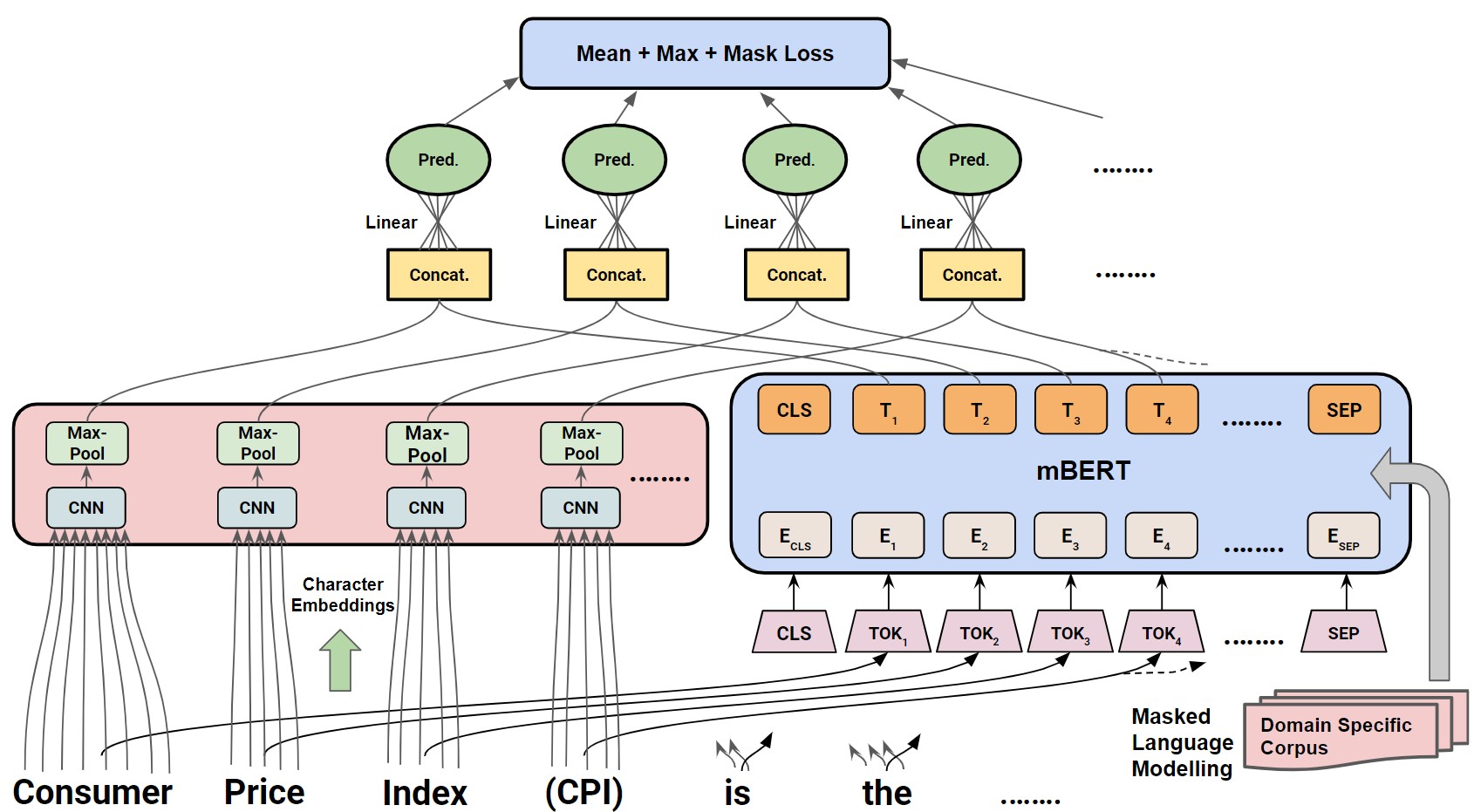 Figure: The CABACE Architecture
Figure: The CABACE Architecture
To create BIO tags, use the following example command
python data/prep_BIO_tags.py -s data/english/legal/dev.json -t data/sample.txt
We support different model architectures to solve AE, and they can be identified using the following model_ids
- SimpleBert - 0
- CharacterTransformBert - 1
To run the code on English Legal dataset using simple BERT for Sequence labelling(model_id = 0) use:
python main.py --src_folder data \
--trg_folder logs \
--model_id 0 \
--seed_value 42 \
--batch_size 8 \
--epoch 6 \
--tokenizer_checkpoint bert-base-cased \
--model_checkpoint bert-base-cased \
--dataset english/legal \
--lambda_max_loss 1.0 \
--lambda_mask_loss 1.0 \
--mask_rate 0.1 \
--cnn_filter_size 5 \
--max_word_len 16
To run the code on English Legal dataset using CharacterTransformBert for Sequence labelling(model_id = 1) use:
-
- Download and unzip fastText Word Vectors in the root directory using the following commands:
wget https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M.vec.zip
unzip wiki-news-300d-1M.vec.zip
-
- Now use the command to run code:
python main.py --src_folder data \
--trg_folder logs \
--model_id 1 \
--seed_value 42 \
--batch_size 8 \
--epoch 6 \
--tokenizer_checkpoint bert-base-cased \
--model_checkpoint bert-base-cased \
--dataset english/legal \
--lambda_max_loss 1.0 \
--lambda_mask_loss 1.0 \
--mask_rate 0.1 \
--cnn_filter_size 5 \
--max_word_len 16
The notebook for Sequence to Sequence model is included.
python run_LM.py --train_data_file train.txt
--output_dir models/
--model_type bert
--eval_data_file eval.txt
--model_name_or_path bert-base-uncased
--mlm
--mlm_probability 0.15
--tokenizer_name bert-base-uncased
--per_gpu_train_batch_size 4
--block_size 512
--num_train_epochs 6
--save_total_limit 5
Add --should_continue to continue from checkpoint
The Scraping code is also included in scraping/ which includes the English Scientific scraping code from ArXiV anf French scraping code from Wikipedia. The french code can be edited by replacing fr in links with the corresponding language code in wikipedia. Also the link of the initial page where scraping starts shall be changed to any similar page (on topics like Neural Networks, Artificial Intelligence or any other scientific topic with a lot of acronyms) in the other language.