![]()


Nixiesearch is a hybrid (semantic + lexical) search engine, focused on simplicity and developer UX:
- state-of-the-art hybrid search: combinging Lucene-powered lexical retrieval, bi-encoder retrieval and LambdaMART Learn-to-Rank reranking for the best search quality.
- zero configuration: batteries included, but everything is tunable.
- (coming soon) fine-tuned for your data: fine-tune semantic search models like E5 or MiniLM-L6-v2 for your data out-of-the-box.
- (coming soon) cloud-native: stateless searchers allow smooth auto-scaling in Kubernetes.
Want to learn more? Go straight to the quickstart.
Unlike some of the other vector search engines:
- Supports facets, rich boolean filtering, sorting and autocomplete: things you got used to in traditional search engines.
- Text in, text out: LLM embedding is handled by the search engine, not by you.
- Exact-match search: Nixiesearch is a hybrid retrieval engine searching over terms and embeddings. Your brand or SKU search queries will return what you expect, and not what the LLM hallucinates about.
The project is in active development and not intended for production use just yet. Stay tuned and reach out if you want to try it!
Get the sample MS MARCO dataset:
curl -L -O http://nixiesearch.ai/data/msmarco.json % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 162 100 162 0 0 3636 0 --:--:-- --:--:-- --:--:-- 3681
100 32085 100 32085 0 0 226k 0 --:--:-- --:--:-- --:--:-- 226k
Run the Nixiesearch docker container:
docker run -i -t -p 8080:8080 nixiesearch/nixiesearch:latest standalone12:40:47.325 INFO ai.nixiesearch.main.Main$ - Staring Nixiesearch
12:40:47.460 INFO ai.nixiesearch.config.Config$ - No config file given, using defaults
12:40:47.466 INFO ai.nixiesearch.config.Config$ - Store: LocalStoreConfig(LocalStoreUrl(/))
12:40:47.557 INFO ai.nixiesearch.index.IndexRegistry$ - Index registry initialized: 0 indices, config: LocalStoreConfig(LocalStoreUrl(/))
12:40:48.253 INFO o.h.blaze.server.BlazeServerBuilder -
███╗ ██╗██╗██╗ ██╗██╗███████╗███████╗███████╗ █████╗ ██████╗ ██████╗██╗ ██╗
████╗ ██║██║╚██╗██╔╝██║██╔════╝██╔════╝██╔════╝██╔══██╗██╔══██╗██╔════╝██║ ██║
██╔██╗ ██║██║ ╚███╔╝ ██║█████╗ ███████╗█████╗ ███████║██████╔╝██║ ███████║
██║╚██╗██║██║ ██╔██╗ ██║██╔══╝ ╚════██║██╔══╝ ██╔══██║██╔══██╗██║ ██╔══██║
██║ ╚████║██║██╔╝ ██╗██║███████╗███████║███████╗██║ ██║██║ ██║╚██████╗██║ ██║
╚═╝ ╚═══╝╚═╝╚═╝ ╚═╝╚═╝╚══════╝╚══════╝╚══════╝╚═╝ ╚═╝╚═╝ ╚═╝ ╚═════╝╚═╝ ╚═╝
12:40:48.267 INFO o.h.blaze.server.BlazeServerBuilder - http4s v1.0.0-M38 on blaze v1.0.0-M38 started at http://0.0.0.0:8080/
Build an index for a hybrid search:
curl -XPUT -d @msmarco.json http://localhost:8080/msmarco/_index{"result":"created","took":8256}Send the search query:
curl -XPOST -d '{"query": {"match": {"text":"new york"}},"fields": ["text"]}'\
http://localhost:8080/msmarco/_search{
"took": 13,
"hits": [
{
"_id": "8035959",
"text": "Climate & Weather Averages in New York, New York, USA.",
"_score": 0.016666668
},
{
"_id": "2384898",
"text": "Consulate General of the Republic of Korea in New York.",
"_score": 0.016393442
},
{
"_id": "2241745",
"text": "This is a list of the tallest buildings in New York City.",
"_score": 0.016129032
}
}You can also open http://localhost:8080/_ui in your web browser for a basic web UI:
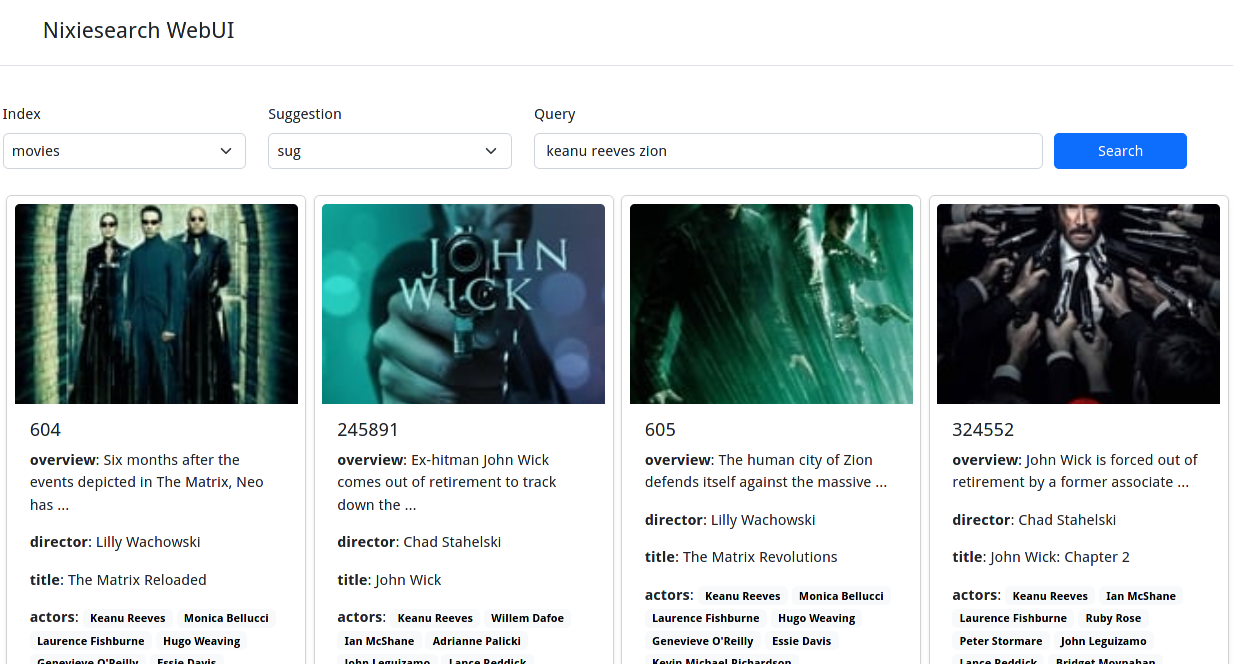
For more details, see a complete Quickstart guide.
Nixiesearch is inspired by an Amazon search engine design described in a talk E-Commerce search at scale on Apache Lucene:
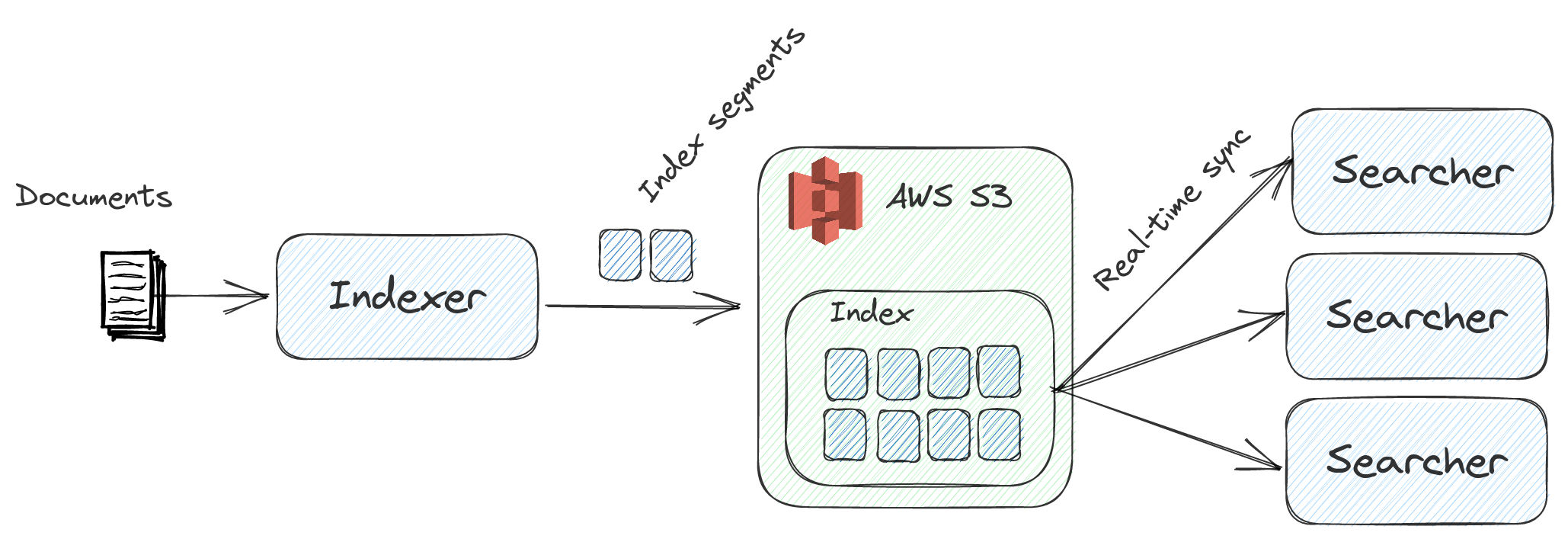
Compared to traditional search engines like Elasticsearch/Solr:
- Independent stateful indexer and stateless search backends: with index sync happening via S3-compatible block storage. No more red index status and cluster split-brains due to indexer overload.
- Pull-based indexing: pull updated documents right from Kafka in real-time, no need for separate indexing ETL jobs with limited throughput.
Nixiesearch uses RRF for combining text and neural search results.
Nixiesearch is not a general-purpose search engine like Elasticsearch:
- No sharding support (yet): so it's not made for logs and APM data. Indices up to 5M docs are OK.
- May require GPU: computing embeddings for large search corpora during indexing is a compute-intensive task and may take a lot of resources if run on CPU. And GPU is a must for a model fine-tuning.
At the moment, Nixiesearch is in the process of active development, so please reach out to use via the contact form if you want to try it!
- Search/Index API
- Index mapping
- Config file parsing
- Lexical search with Lucene
- Semantic search with Lucene
- Hybrid search
- MSMARCO E2E hybrid test
- Facets for terms and ranges
- Boolean filtering for lexical/semantic search
- Autocomplete suggestions
- S3 index sync
- LLM fine-tuning
- Cut-off threshold prediction for semantic search
This project is released under the Apache 2.0 license, as specified in the License file.