{kind=link}
This project began as a single weekend project completed for my COMP_SCI 349 (Machine Learning) course at Northwestern University. Students were offered the choice of a number of fixed toy datasets and tasks to complete. I chose to perform multi-label classification based on a custom-generated dataset.
To reduce redundancy/ambiguity, the original copy of my COMP_SCI 349 (Machine Learning) final has been privated. The PDF write-up I submitted for that project has been provided in ./OLD_COMP_SCI_349_NK_Final.pdf if you're curious to compare performance then vs now (in short, F1 macro score increased from .79 to around .88)
A list of Reddit posts (comments or primary submissions) containing links two websites (Homebrewery or GMBinder) was obtained using a command-line tool built ontop of the Python Reddit API (PRAW) by myself located here. Some processing of the specific web URLs collected via Reddit is provided by functions which live in ./src/scraping.py and ./src/preprocessing/text_cleaning.py
4-5k Reddit posts were eventually collected (the initial dataset was close to 2.5-3K at the time of my COMP SCI final). Out of these, around 3K unique pieces of fan-made content were eventually obtained.
Overall, it's worth noting that class-imbalance is heavy within this dataset (see EDA Highlights below), so weighted sampling/training methods are utilized in Part 3 for model fitting.
This repo expects/creates a ./data folder which contains data and intermediates for different stages. The final size of this folder, with all check-points is around 1.7 GB, so it is not provided here.
All the basic inputs/intermediates used in these notebook are provided on a separate Google Drive folder here. This includes a pickled version of the pickled SVC/sklearn model and a .pth file from the trained RoBERTA model. Note that version 1.2.2 of sklearn was used for this (see requirements.txt)
There are 9 notebooks organized into three parts.
This part is entirely devoted to integrating new and old data together, filtering out redundant or irrelevant content, collecting and cleaning text from the web, and identifying improperly labeled content and fixing it. I recommend skipping over these notebooks, they behave a bit oddly, in particular because the initial dataset was collected in a dirtier manner than follow-up collections since the first collection was done as part of a short one weekend project for a class final.
This part is devoted to exploratory data analysis on three different levels/scopes:
- Statistics/data associated with the underlying metadata from Reddit (Part2A)
- Statistics associated with very basic language usage (Part3A) with the aim of finding oddities in the data cleaning/processing steps
- An exploration of word usage, including visualization of the class labels in a bag-of-words feature space
A few figures, mainly from the third notebook in Part 2 are highlighted in the EDA Highlights section.
In this part I fit two types of models to the data as either a BoW (SVC-based) model or sequence classifier (RoBERTA) task. Both peak out at around a F1 of .9, which appears to be in part because only a small portion of the class labels have been manually reviewed and sometimes the Reddit dataset is mislabeled for a number of reasons (partly explored in Part 1 and discussed below. On top of this, my current labels only allow for one class to be assigned when in fact the task is really a multi- label/multi-class one, with a fairly substantial number of texts likely including more than one valid label. However, for an initial demonstration project, this is satisfactory to me for now.
As noted above, there are many instanced of mislabeled content when relying on Reddit flair. For this reason, I developed a small CLI tool for reviewing and updating labels manually, which is used in Part 1 to catch/review around 10% of labels which are at a high risk for being mislabeled. For improved performance, it may be necessary to employ further until the labels can all be trusted.
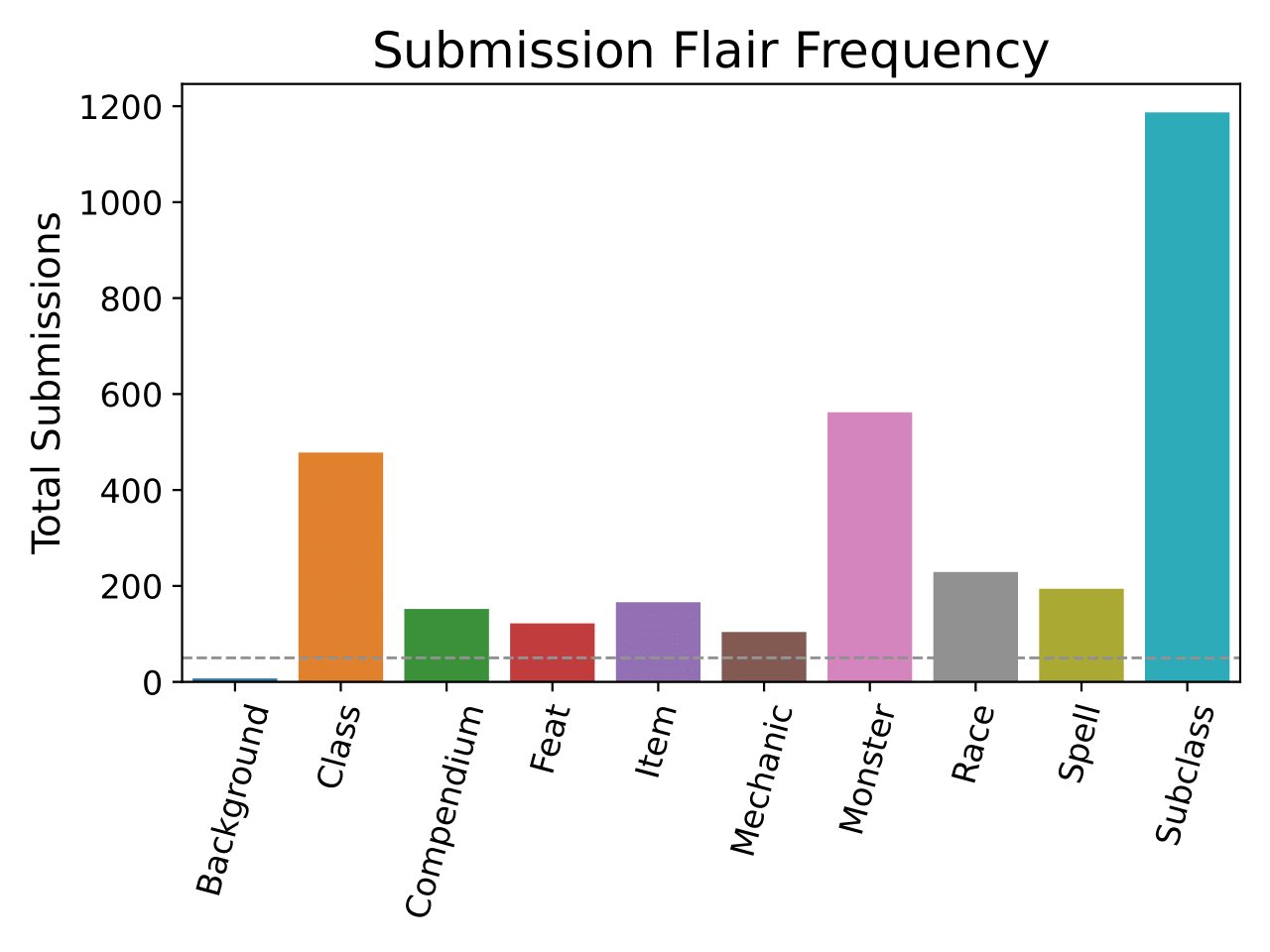
Notably, class/label imbalance is vast within this dataset, hence the use of a custom, weighted sampler in the fitting of the RoBERTA model/calculating model loss and the use of balanced class/label weighting by the SVC models for bag of words.
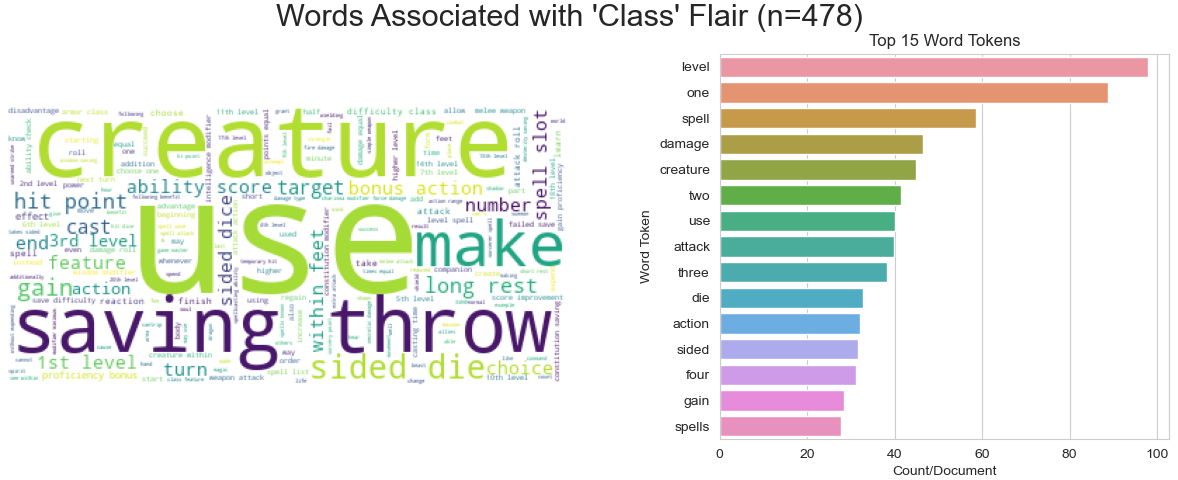
In general, there seem to be a few highly over-represented or under-represented terms per label class relative to all of the others. Here are a few of these visualized by both barplot and word cloud:
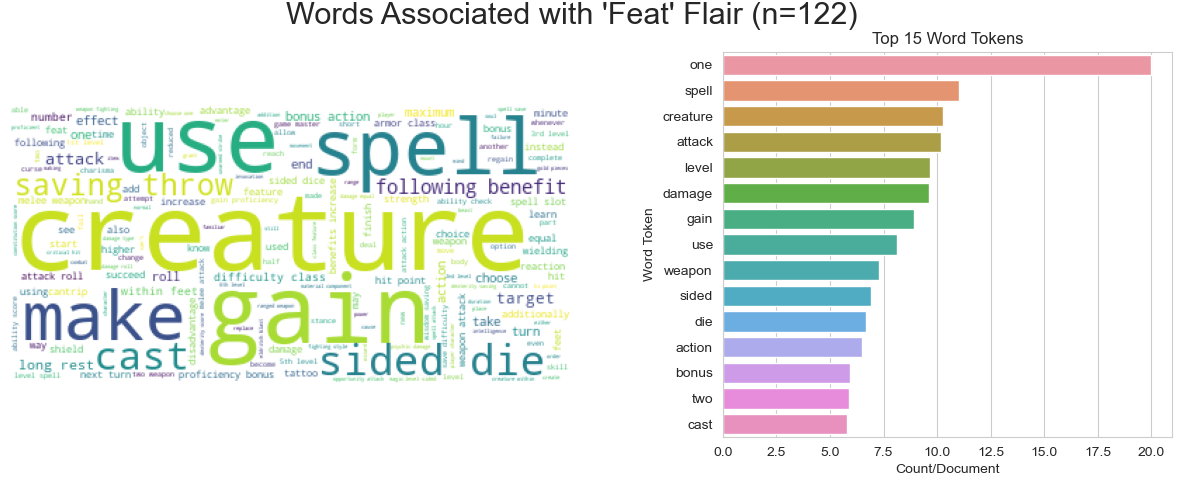
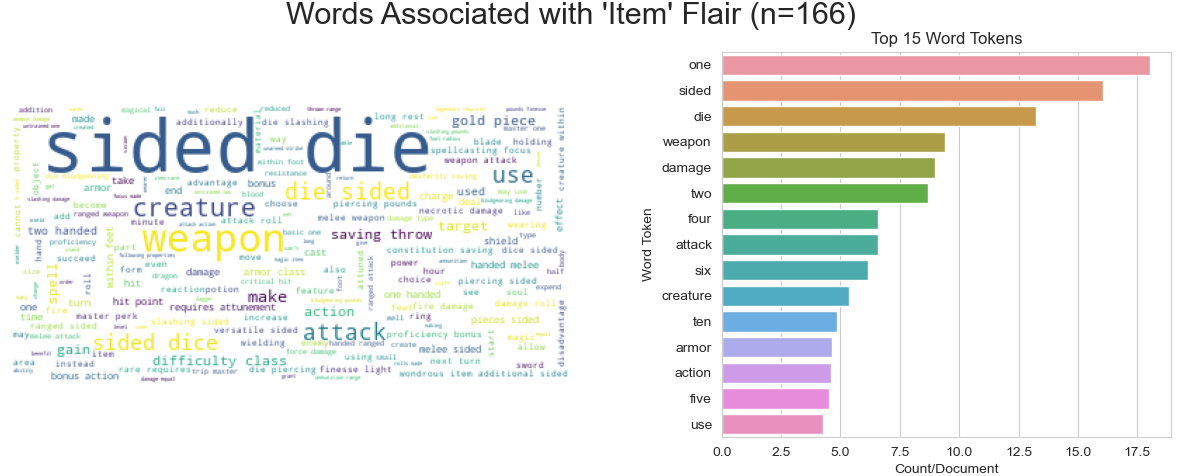
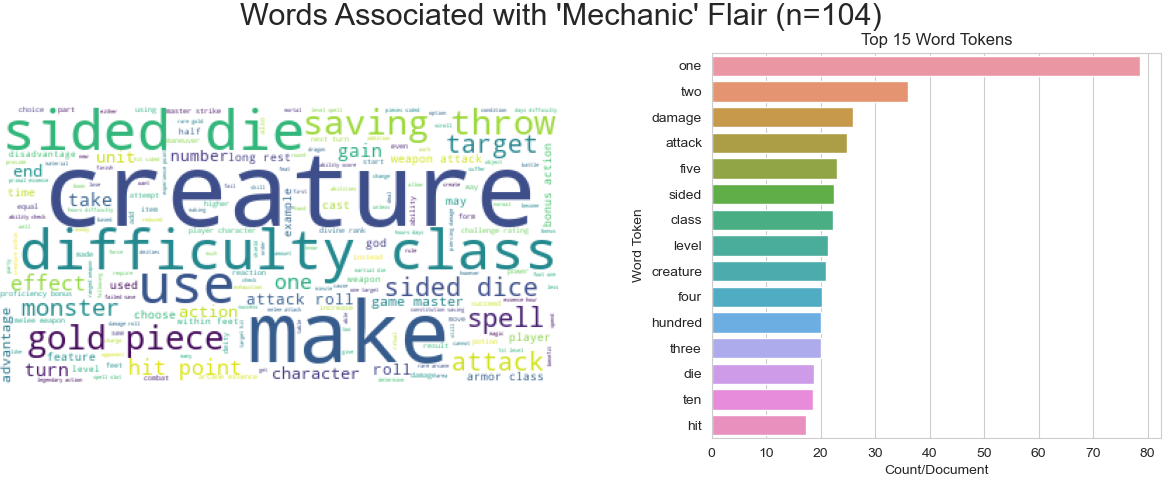
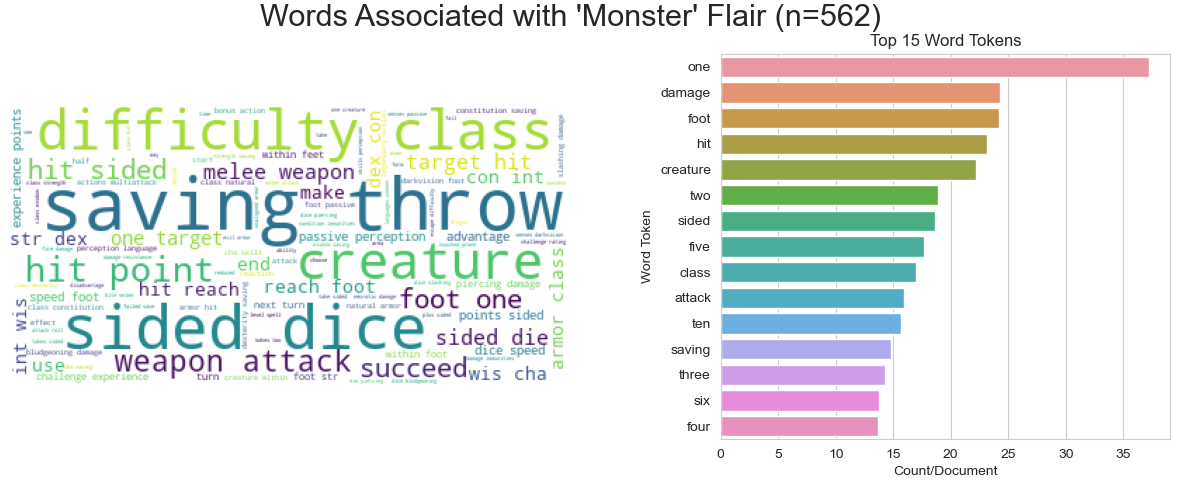
There is very limited class-based separation in the first few PCs of these data, but based on UMAP projections of simple TF-IDF bag of words vectors, the classes already separate nicely, thus I expected that many simple non-linear algorithms will work will quite well for this classification task.