


![]()

Fast, robust sentence splitting with bindings for Python, Rust and Javascript and pretrained models for English and German.
- Robust: Does not depend on proper punctuation and casing to split text into sentences.
- Small: NNSplit uses a character-level LSTM, so weights are very small (~ 350 kB) which makes it easy to run in the browser.
- Portable: Models are trained in Python, but inference can be done from Javascript, Rust and Python.
- Fast: Can run on your GPU to split 100k paragraphs from wikipedia in 50 seconds. With RTX 2080 TI and i5 8600k. Paragraphs have an average length of ~ 800 characters. See
benchmark.ipynbfor the code.
NNSplit has PyTorch as the only dependency.
Install it with pip: pip install nnsplit
>>> from nnsplit import NNSplit
>>> splitter = NNSplit("en")
# NNSplit does not depend on proper punctuation and casing to split sentences
>>> splitter.split(["This is a test This is another test."])
[[[Token(text='This', whitespace=' '),
Token(text='is', whitespace=' '),
Token(text='a', whitespace=' '),
Token(text='test', whitespace=' ')],
[Token(text='This', whitespace=' '),
Token(text='is', whitespace=' '),
Token(text='another', whitespace=' '),
Token(text='test', whitespace=''),
Token(text='.', whitespace='')]]]Models for German (NNSplit("de")) and English (NNSplit("en")) come prepackaged with NNSplit. Alternatively, you can also load your own model:
import torch
model = torch.jit.load("/path/to/your/model.pt") # a regular nn.Module works too
splitter = NNSplit(model)See the Python README for more information.
The Javascript bindings for NNSplit have TensorFlow.js as the only dependency.
Install them with npm: npm install nnsplit
>>> const NNSplit = require("nnsplit");
// pass URL to the model.json, see https://www.tensorflow.org/js/tutorials/conversion/import_keras#step_2_load_the_model_into_tensorflowjs for details
>>> const splitter = NNSplit("path/to/model.json");
>>> await splitter.split(["This is a test This is another test."]);
[
[
{
"text": "This",
"whitespace": " "
},
{
"text": "is",
"whitespace": " "
},
{
"text": "a",
"whitespace": " "
},
{
"text": "test",
"whitespace": " "
}
],
[
{
"text": "This",
"whitespace": " "
},
{
"text": "is",
"whitespace": " "
},
{
"text": "another",
"whitespace": " "
},
{
"text": "test",
"whitespace": ""
},
{
"text": ".",
"whitespace": ""
}
]
]Note: when running NNSplit from Node.js, you'll have to manually import @tensorflow/tfjs-node before instantiating NNSplit.
require("@tensorflow/tfjs-node");
const NNSplit = require("nnsplit");For size reasons, the Javascript bindings do note come prepackaged with any models. Instead, download models from the Github Repo:
| Model Name | |
|---|---|
| en | Path |
| de | Path |
See the Javascript README for more information.
Add NNSplit as a dependency to your Cargo.toml:
[dependencies]
# ...
nnsplit = "<version>"
# ...use nnsplit::NNSplit;
fn main() -> failure::Fallible<()> {
let splitter = NNSplit::new("en")?;
let input = vec!["This is a test This is another test."];
println!("{:#?}", splitter.split(input));
Ok(())
}Models for German (NNSplit::new("de")) and English (NNSplit::new("en")) come prepackaged with NNSplit. Alternatively, you can also load your own model with NNSplit::from_model(model: tch::CModule).
See the Rust README for more information.
I developed NNSplit for a side project where I am working on Neural Text Correction. In Neural Text Correction, it makes the most sense to me to have sentence-level input, rather than entire paragraphs. In general, NNSplit might be useful for:
- NLP projects where sentence-level input is needed.
- For feature engineering (# of sentences, how sentences start, etc.)
- As inspiration for neural networks that work everywhere. NNSplit has bindings for Python, Rust and Javascript. But the code is really simple, so it is easy to use it as a template for other projects.
NNSplit uses wikipedia dumps in the Linguatools format to train.
- ) Paragraphs are extracted from the dump.
- ) Split the paragraphs into tokens and sentences using a very accurate existing rule based sentencizer and tokenizer: SoMaJo.
- ) With some probability, words at the start of a sentence are converted from uppercase to lowercase, and dots at the end of a sentence are removed. This is the step that allows NNSplit to be more tolerant to errors than SoMaJo. For a rule-based system, it is nearly impossible to split sentences that don't have proper separation in the form of punctuation and casing. NNSplit solves this problem.
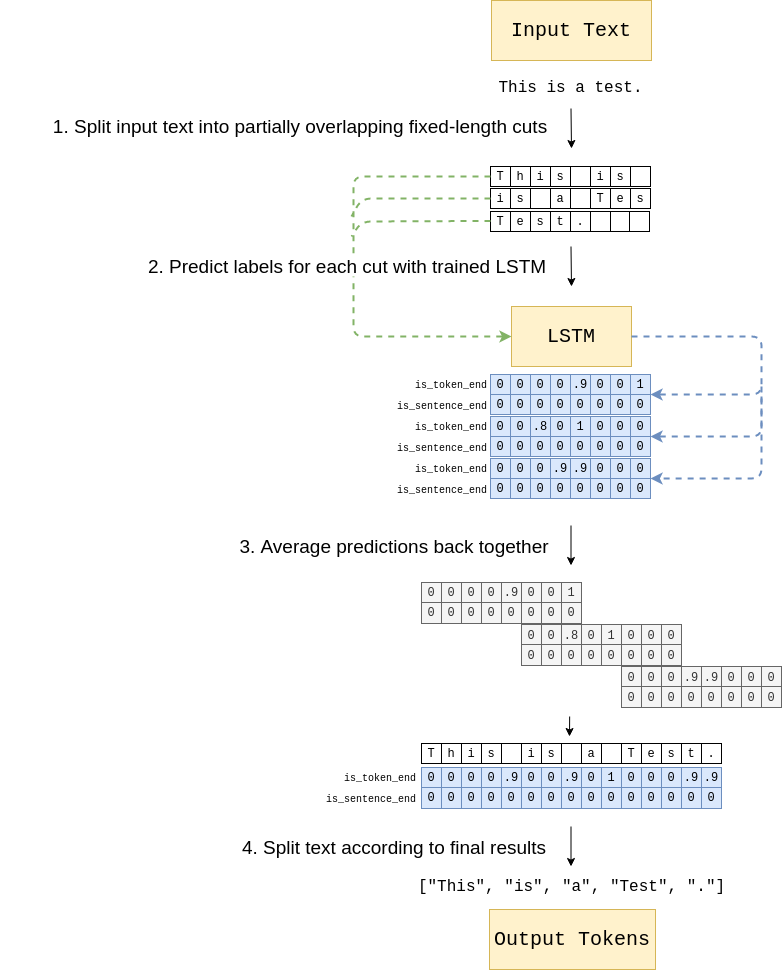
- ) Multiple "cuts" with a fixed length (default 500 characters) are extracted from a paragraph. This makes NNSplit invariant to input length.
- ) A simple sequence labeling RNN is trained to predict the two labels for each character. Because the NN works on character-level, embedding sizes are very small.
- ) At inference time, the input text is split into multiple cuts with the same length of 500 characters so that the entire text is covered. NNSplit predicts each cut separately. The predictions are then averaged together for the final result.

It is not trivial to evaluate NNSplit since I do not have a dataset of human-annotated data to use as ground truth. What can be done is just reporting metrics on some held out data from the auto-annotated data used for training.
See F1 Score, Precision and Recall averaged over the predictions for every character at threshold 0.5 below on 1.2M held out text cuts.
Tokenization
| Model Name | F1@0.5 | Precision@0.5 | Recall@0.5 |
|---|---|---|---|
| en | 0.999 | 0.999 | 0.999 |
| de | 0.999 | 0.999 | 0.999 |
Sentence Splitting
| Model Name | F1@0.5 | Precision@0.5 | Recall@0.5 |
|---|---|---|---|
| en | 0.963 | 0.948 | 0.979 |
| de | 0.978 | 0.969 | 0.988 |
These metrics are not comparable to human-level sentence splitting. SoMaJo, the tool used to annotate paragraphs, is a good tool though so I do consider the results to be solid.