Jobber is a job queue service implemented using GO and Redis. Its scalable and resilient. Each component can be horizontally scalled. It can recover jobs from workers who fail to execute a job and assign them to other workers.
Jobber is the version 2 of Walrus project (https://github.com/nmjmdr/walrus)
Jobber simplifies the design and improves the project structure. It does not have built in scheduler like Walrus (A scheduler is used to schedule jobs for execution - execute job at a point intime). It implements dispatcher, worker and recoverer.
Jobber can be easily extended to perform the functionality of Walrus by adding the scheduler component to it.
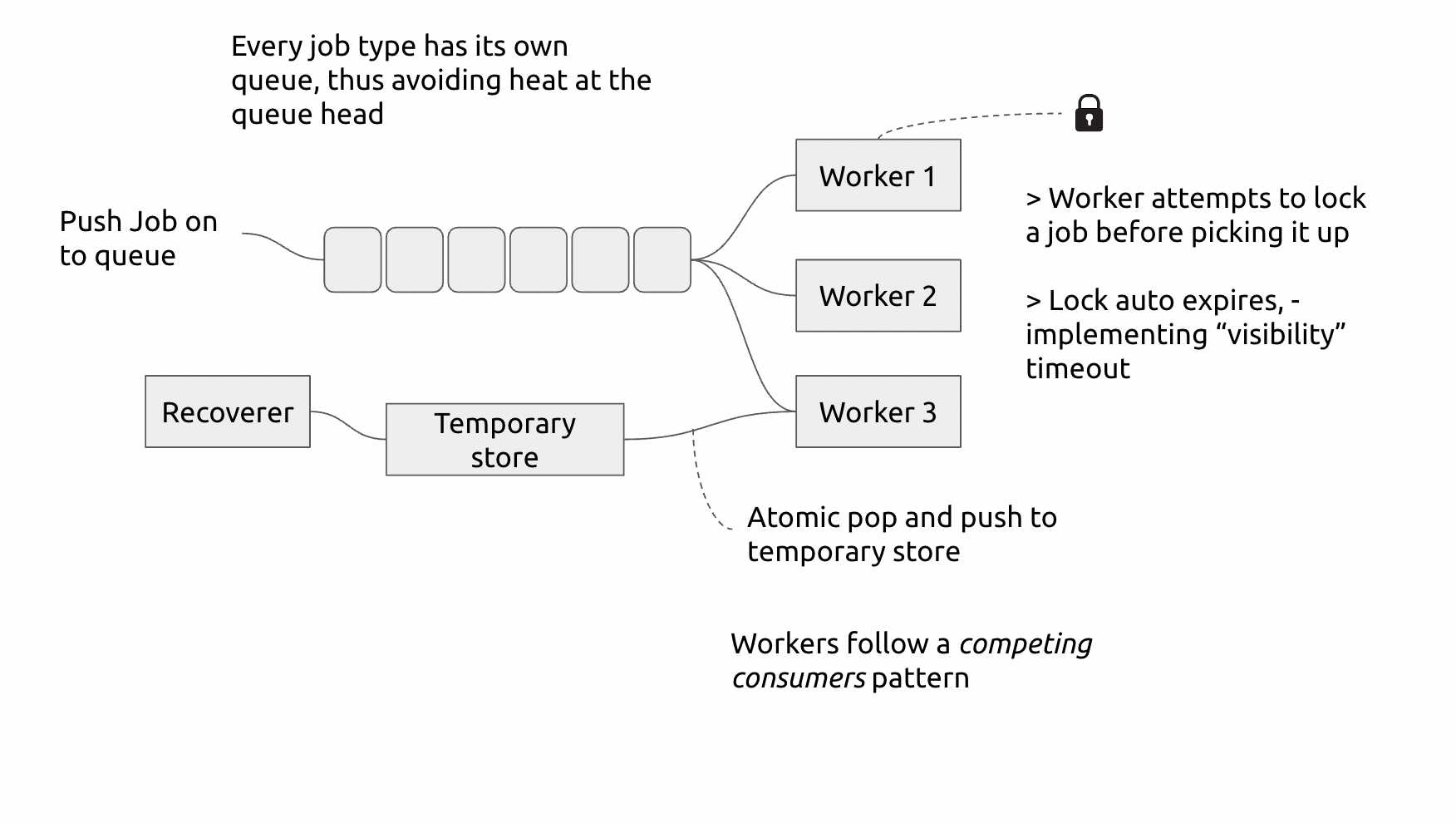
Jobber has the concept of a Job Type. Each job type gets its own worker queue. One can have a number of worker instances running to execute job depending upon the load on the worker queue. A future enhancment would be be auto-scale the number of workers depending upon the jobs that are queued in the worker queue.
Jobber supports recovering a job. If a worker fails during the execution of a job, the job can be recovered and executed by another worker. Recovery is supported using the concept of Visiblity timeout
When a worker picks up a job to execute it has fixed amount of time in which to complete it. Within this time window the job is not visible to other workers. This time period is called as Visiblity timeout If the worker fails to do so, then a recoverer process recovers the job and pushes it back onto the worker queue.
The API supports operation to queue a job: Request
POST: https://<host>/jobber/queue
Body:
{
"type": "job-type"
"payload": {
/* free-form json payload */
}
}
Response
201 OK
{
"job-id": "uuid"
}
I have discussed the design details in this 4-part video series


{kind=link}
- The API accepts a new job and queues it a queue named
job_queue_job-type. - An instance of the worker is ready to take a new job, it tries to acquire lock on the job (job-id). The lock is set to auto expire after
visibility_timeouttime period. - If successful, it then does RPOPLPUSH, poping the job from the worker queue and pushing it onto
in_process_queue - Worker then works to finish the job and then deletes it from
in_process_queue - If in case worker is unable to finish the job and delete it from
in_process_queue, then the recoverer process pushes it back onto the worker queue
- Recoverer regularly scans the
in_process_queuefor jobs that do not have an active lock - If it finds a job present in the
in_process_queuebut without an active lock, it then pops that job and pushes it back onto the worker queue
The worker follows the below steps:
- Read the head of the queue
- Try and lock the job
- If it cant, return and go back to waiting for the next job
- If the job is locked, then the worker pops the job from the worker queue and pushes it to in_process_queue (It does this using RPOPLPUSH so that the push and pop operations are done in a single step)
- Meanwhile if the recoverer tries to recover a job, it finds that there is an active lock on the job and it returns
- Process the job
- Delete from in_process_queue
- Delete the lock
If the worker fails in processing the job, the job remains in in_process_queue and the locks expires. The recoverer can then recover the job.
Currently the recoverer attempts to recover only the job at the head of the queue. It does not look further down the queue. This should not be a problem as along the visibility timeouts are small and it is not highly critical to recover the jobs relatively early.
Visiblity time out is implemented using SETNX with expiry. SETNX sets a key only if it does not exist. Lock attempts to create a new key using SETNX for the given job id. If it can create it then the a lock has successfully placed on the job. The key is set to expire within the visibility time out period.
Note that currently I have not used Redlock mechanism https://redis.io/topics/distlock and only done a SETNX without a random value. The drawback of this is that in a master slave setup of redis, if the master goes down, then there is a chance that a valid lock could be removed by another process (in our case the recoverer).
Currently this is not handled and the lock can be easily enhanced to handle it.
- Making the recovere look through the in_proceses_queue to recover jobs