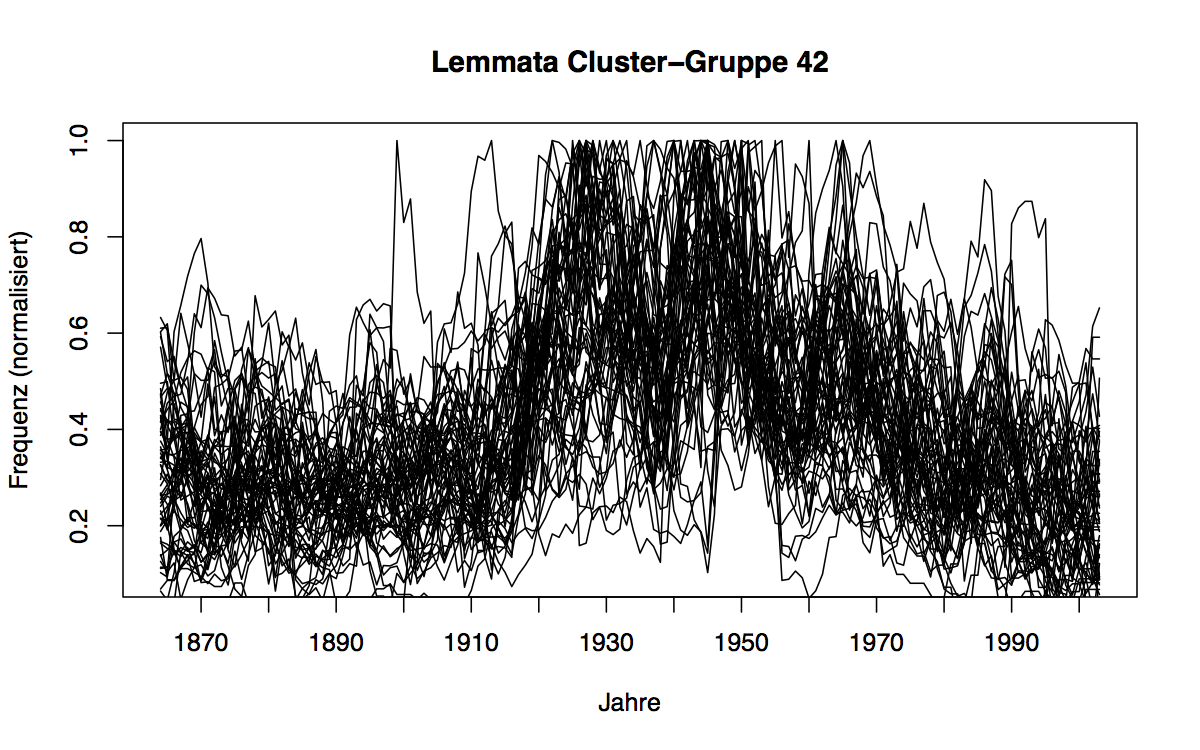
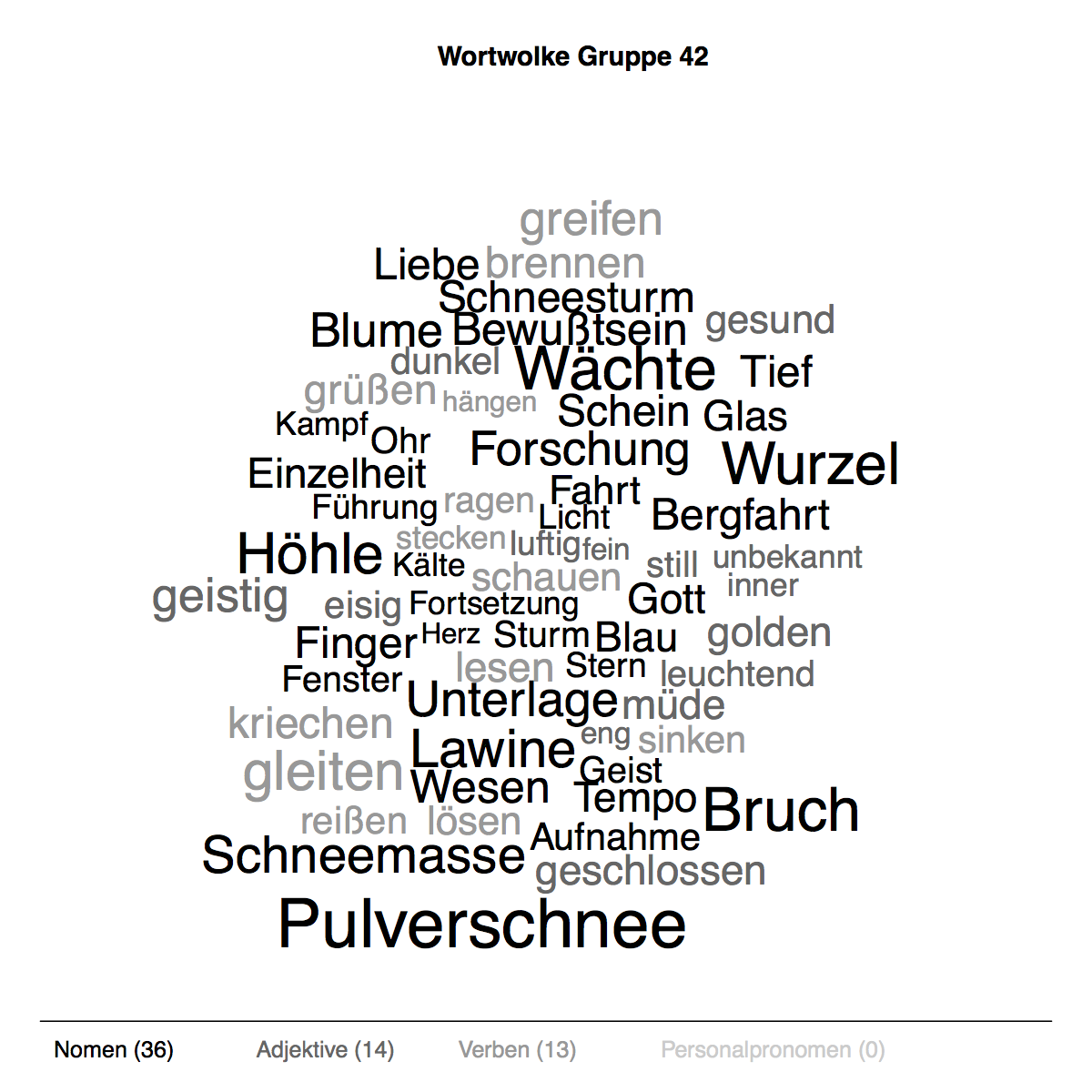
clustering of frequency distributions over time
Used in: Bubenhofer, Noah/Scharloth, Joachim (2014): "Korpuspragmatische Methoden für kulturanalytische Fragestellungen". In: Benitt, Nora et al. (Hrsg.): Kommunikation – Korpus – Kultur. Ansätze und Konzepte einer kulturwissenschaftlichen Linguistik. Giessen Contributions to the Study of Culture, Trier: Wvt Wissenschaftlicher Verlag. S. 47-66.
http://www.bubenhofer.com/publikationen/PreprintBubenhoferKorpuspragmatikKulturanalyse.pdf
See the following blog post: https://www.bubenhofer.com/sprechtakel/2013/01/17/diachrone-analysen-verlaufskurven-clustern/
CWB> A = <text_date_published = "2...-..-.."> [] expand to text;
CWB> dump A > "dump.bfe_de.tbl"
cwb-decode -Cx -f dump.bfe_de.tbl BFE_DE -P word -P pos -P lemma -S text -S text_date_published > corpus.bfe_de.vrt
A Perl-script calculates frequencies of all types in a corpus over time:
perl semtracks_words.pl --out corpus.bfe_de.words.tbl corpora/corpus.bfe_de.vrt
Its output is as follows:
April_NN 1.85E-17 1.85E-17 1.85E-17 1.85E-17 1.85E-17 1 0.934902788 0.919769464 0.903005247 0.843910568 0.807908532 0.783319772
Art_NN 4.87E-16 4.87E-16 4.87E-16 4.87E-16 4.87E-16 1 0.954222465 0.860096473 0.812486598 0.727636026 0.646087508 0.573866272
Artikel_NN 0 0 0 0 0 1 0.904079875 0.716713973 0.610993548 0.557065572 0.521863921 0.473729264
Aufgabe_NN 0 0 0 0 0 1 0.900355838 0.832735852 0.783733414 0.739622588 0.669389506 0.632951271
August_NN 1.00E-16 1.00E-16 1.00E-16 1.00E-16 1.00E-16 0.942386955 0.972609084 1 0.998735575 0.940385983 0.906432886 0.873261635
Use R-script lexiconClustering.r.
- semtracks_words.pl
- lexikonclustering.r
- lib-files for
lexikonClustering.r:griesDP.rand_dispersions2.r(by Stephan Gries)