Noto Sans Limbu shows dotted circles with U+193A LIMBU SIGN KEMPHRENG #3
Comments
|
If I swap the order of the vowel sign and KEMPHRENG (option 3 in the comment above) the rendering does not show any dotted circles with the same environments as above. File File |

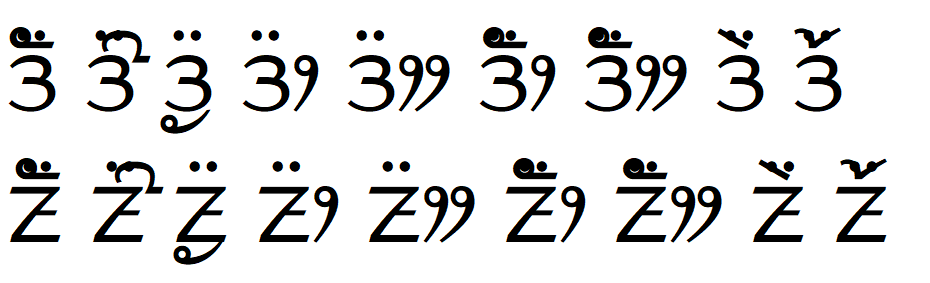
|
I forgot to add the table referenced in the original post
|
|
I don't see a major problem with using a smart keyboard. A minor one though. It makes the keyboard more complicated, especially if a user is editing text with two marks (vowel and kemphreng) and wishes to delete one mark, which mark gets deleted? There is a lot of digital text with the kemphreng after VBlw or VPst, but most (if not all) of that text was derived from Devanagari using a conversion table. I don't know of a standard that requires that order. Linguistically it is the most straightforward, and therefore I would guess easier for any user to understand how to type (with a non-smart keyboard). |
|
The choice here is whether we recategorise U+193A from VAbv to VMAbv. Linguistically, functionally, typing orderly, it is a VMAbv. That it is a VAbv is really a bug. The question is whether changing it is too costly and whether there is a willingness to change. We know of no other Unicode data in Limbu beyond the text we have auto converted from Devanagari script. So redoing that to reorder is not a problem. The technical change within the USE is trivial and alleviates the need for smarts in the keyboard. But the keyboard smarts aren't huge either if your keyboard has the general capability. In terms of UX with U+193A being left as VAbv; for the most part a smart keyboard can fake the reordering (the user always types it after a vowel, as they are used to). But there are some rough edges to that. For example, dropping a cursor and hitting backspace will almost certainly delete the VPst (or more confusingly the VBlw) before deleting the U+193A when the user would expect the opposite experience. If there is a willingness in the community to make the change, then we could write a Unicode proposal to change the category. The question is how long it would take to roll out the change, if it is agreed. |
|
In my original post my description of auto-length.txt as (U+190B|U+190F)(VOWEL SIGN x)(U+193A) is a bit incorrect. There are 9 vowels, but ten clusters in each line. The extra cluster (at the beginning of the line) does not have a vowel sign, just a consonant and the U+193A. In a later post I swapped the order of the vowel sign and the U+193A. Since there was no vowel sign in the first cluster in the original post to swap, the example would have been the same, so I omitted the first cluster in the second test. |
|
Sounds obvious candidate for change to me. We can get this in HarfBuzz very quickly. Definitely right after UTC approving and possibly earlier. If there's no huge Android userbase for it I don't see a problem since chrome and Firefox would update rather quickly. |
|
Fixed in both HB (tested with 2.8.0) and DW (tested with the following version of Windows) I think DW made the fix first in microsoft/font-tools@e8e20f5 and HB imported this fix for itself in harfbuzz/harfbuzz@06f49fc Thanks to @xadxura and @dscorbett for doing this. |
- move data from most text files to a ftml file - remove trial encoding of consonant + kemphreng + vowel The second issue is explained in a bug report https://github.com/googlefonts/noto-fonts/issues/1623
Font
NotoSansLimbu-Regular.ttf
Where the font came from, and when
Site: https://github.com/googlefonts/noto-fonts/blob/master/phaseIII_only/unhinted/ttf/NotoSansLimbu/NotoSansLimbu-Regular.ttf
Date: 2019-12-02
Font Version
2.000
OS name and version
Ubuntu Bionic amd64
Windows 10 Pro 1909
Application name and version
On Ubuntu - Libre Office Writer 6.0.7
On Windows - Notepad
Issue
Using U+193A LIMBU SIGN KEMPHRENG as a length mark after a vowel sign causes dotted circles with some vowel signs.
Using the file
auto-length.txtformat with font in the above applications.auto-length.txt
The file has space separated clusters of (U+190B|U+190F)(VOWEL SIGN x)(U+193A). I suspect the issue would happen with any consonant.
File
harfbuzz-noto.pngfrom LibreOffice Writer on UbuntuFile
directwrite-noto.pngfrom Notepad on Windows. Note that DirectWrite produces more dotted circles than HarfBuzz.File
harfbuzz-namdhinggo.pngThis last example was created with the Namdhinggo font with
limbscript lookups removed, leaving onlylatnscript lookups. I suspect the results would be the same if thelatnlookups were replaced withDFLTscript. This way, the USE does not get invoked on Ubuntu LibreOffice Writer. On Widows, the USE would have been called, and dotted circles produced.If I use
hb-view, I can have lookups for bothlimbandlatnscript, and by passing--scripttohb-viewI can reproduce the dotted circles withlimband the desired result (no dotted circles) withlatn.The character U+193A LIMBU SIGN KEMPHRENG has Unicode Indic Syllabic Category (UISC) of Vowel_Dependent and a Unicode Indic Positional Category (UIPC) of Top. This causes the character to have a Sigla of VAbv. The USE allows a sequence of multiple characters with VAbv. However, the cluster model (the Standard cluster is what is used for the text that is having rendering issues) says that all VAbv must come before all VBlw and all VPst. As you can see in the table below, HarfBuzz (HB) and DirectWrite (DW) fails if the vowel sign is VBlw or VPst, since the following Kemphreng is VAbv.
If U+193A is classified with UISC = Tone_Mark, this would cause the Sigla to become VMAbv (VOWEL_MOD_ABOVE) and since all vowel modifiers come after vowels, then the cluster validation will pass. Changing the HB source code (locally) to use VMAbv instead of VAbv fixes the issue.
So, can the Noto font be modified to have a lookup that removes the dotted circle that USE inserts? Other options are:
Personally, I suspect option 1 or 2 would be best, but that is just my opinion.
Character data
Attached above.
Screenshot
Attached above.
The text was updated successfully, but these errors were encountered: