The intention of this project is to review and implement the existing Gradient Descent optimization algorithms.
- Test Functions
- Gradient Descent
- Nesterov Accelerated Gradient
- AdaGrad — Adaptive Gradient
- RMSProp - Root Mean Square Propagation
- License
The following are the functions that are used for testing the algorithms.
- Ackley function
- Gradient descent example from Wikipedia
- Himmelblau function
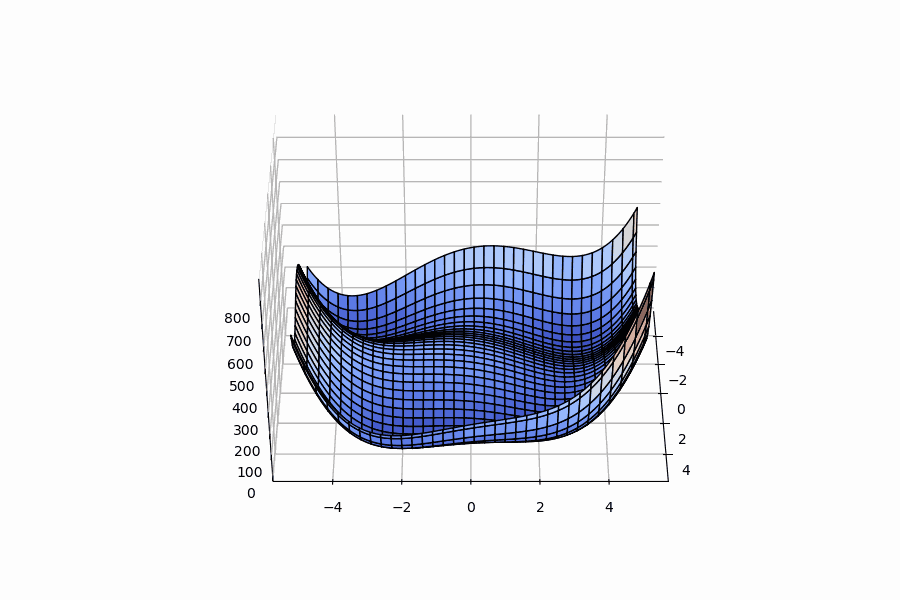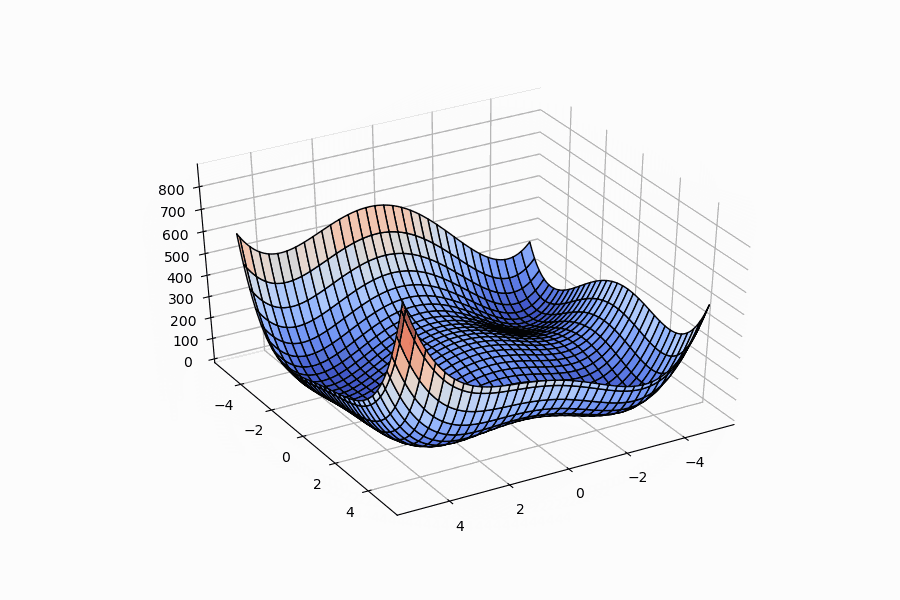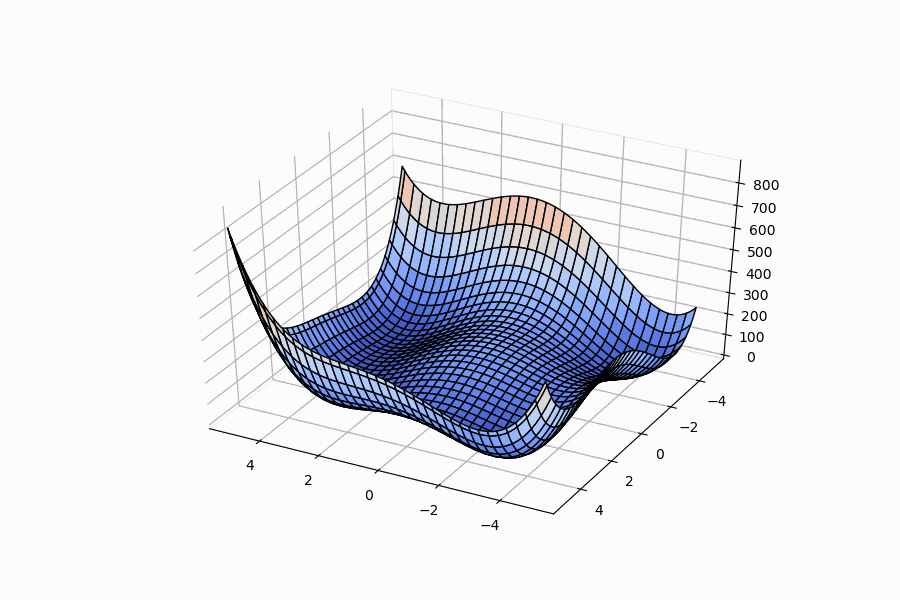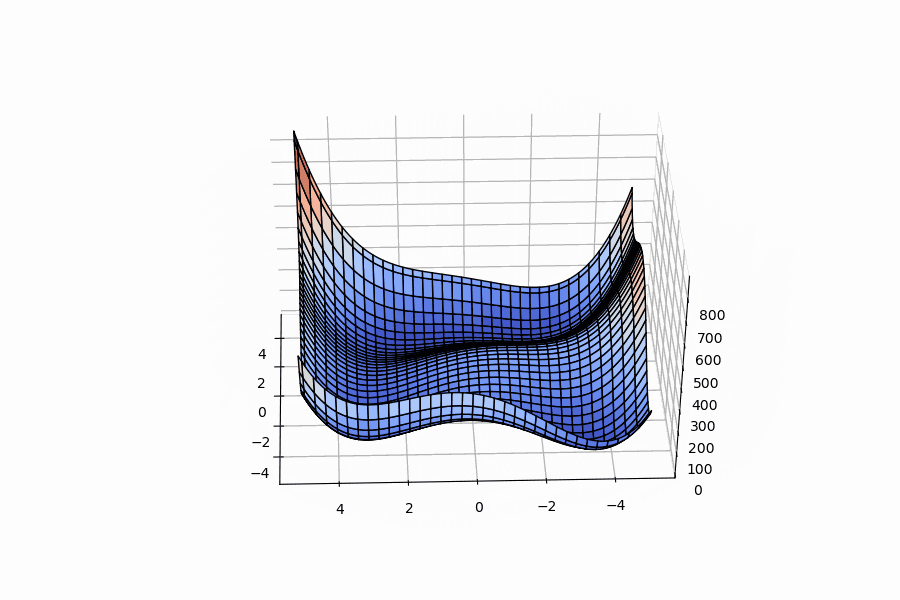
Below are 3D surface, contour and 3D animation plots of these functions respectively:
| Ackley function | example from Wikipedia | Himmelblau function |
 |
 |
 |
 |
 |
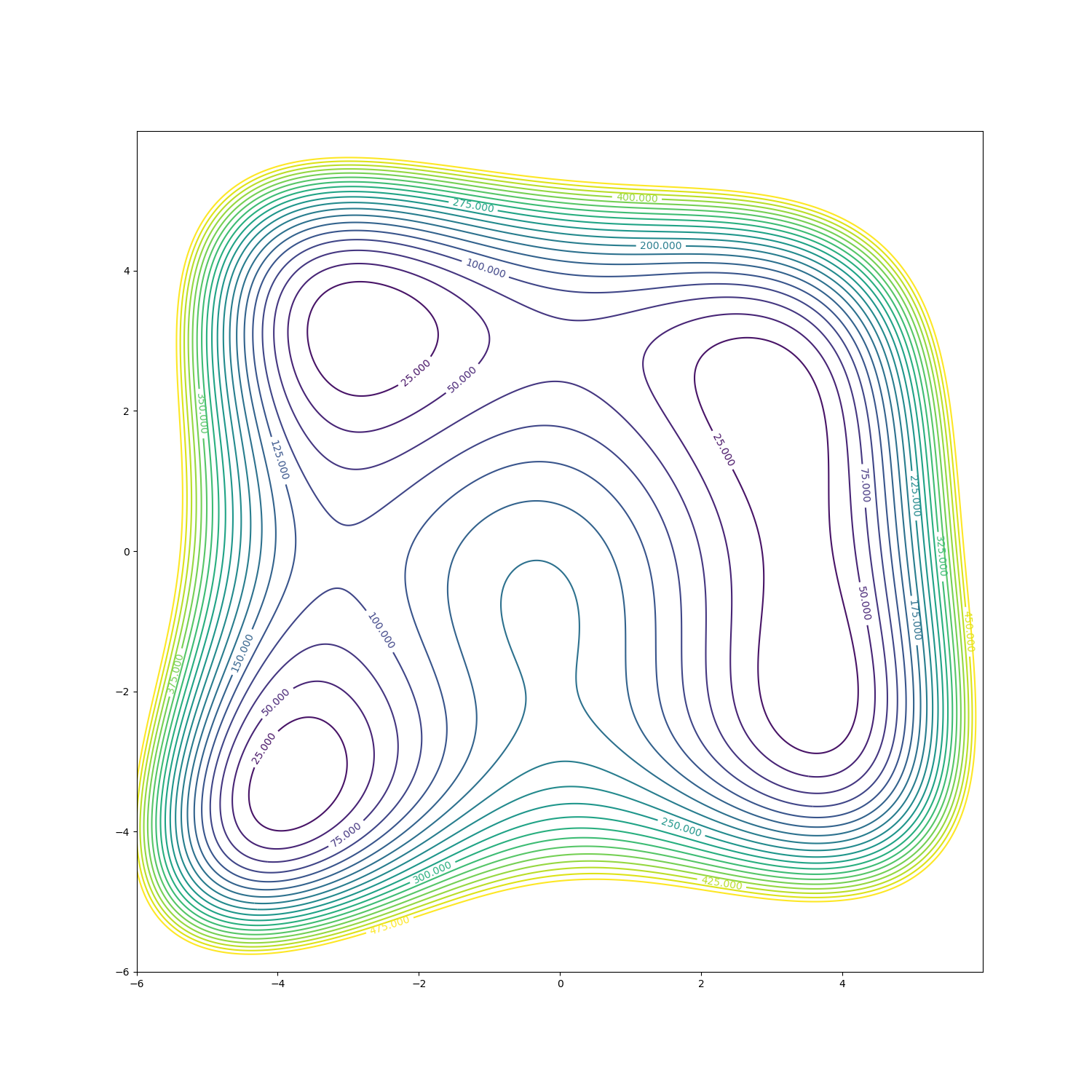 |
 |
 |
 |
See:
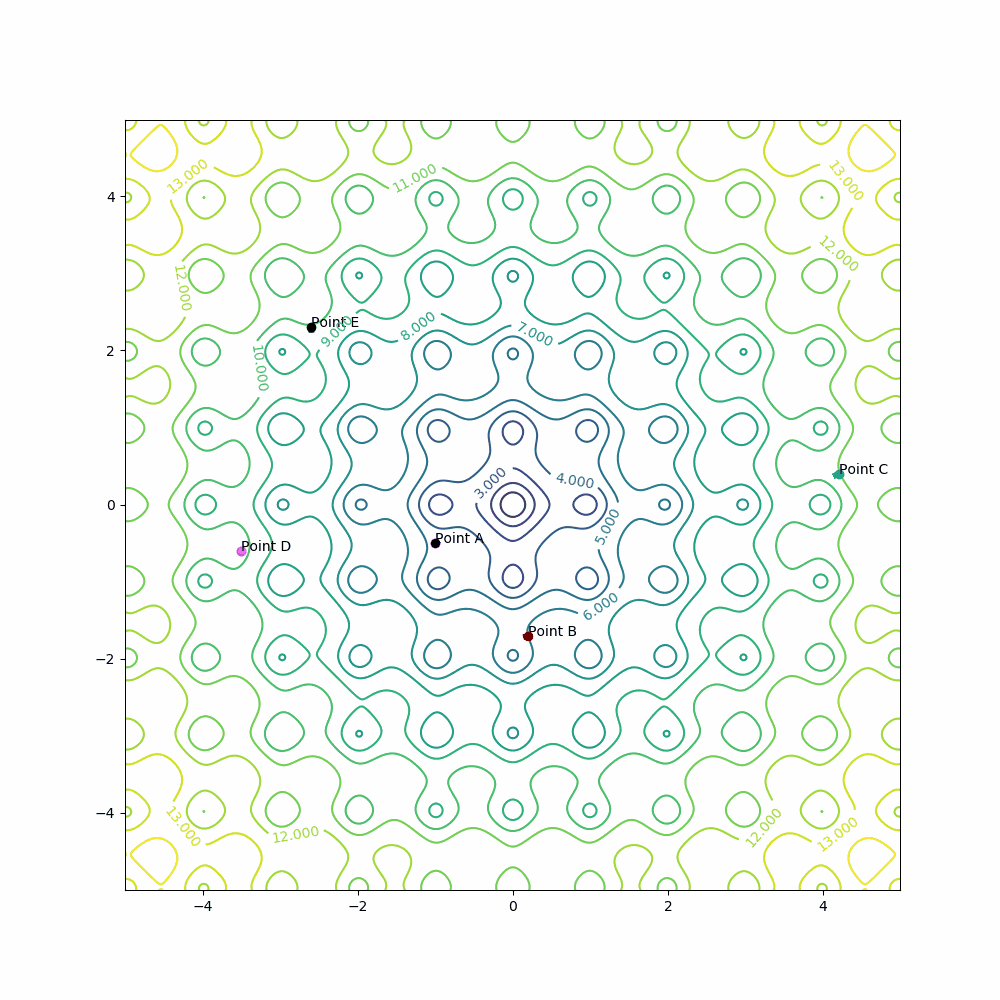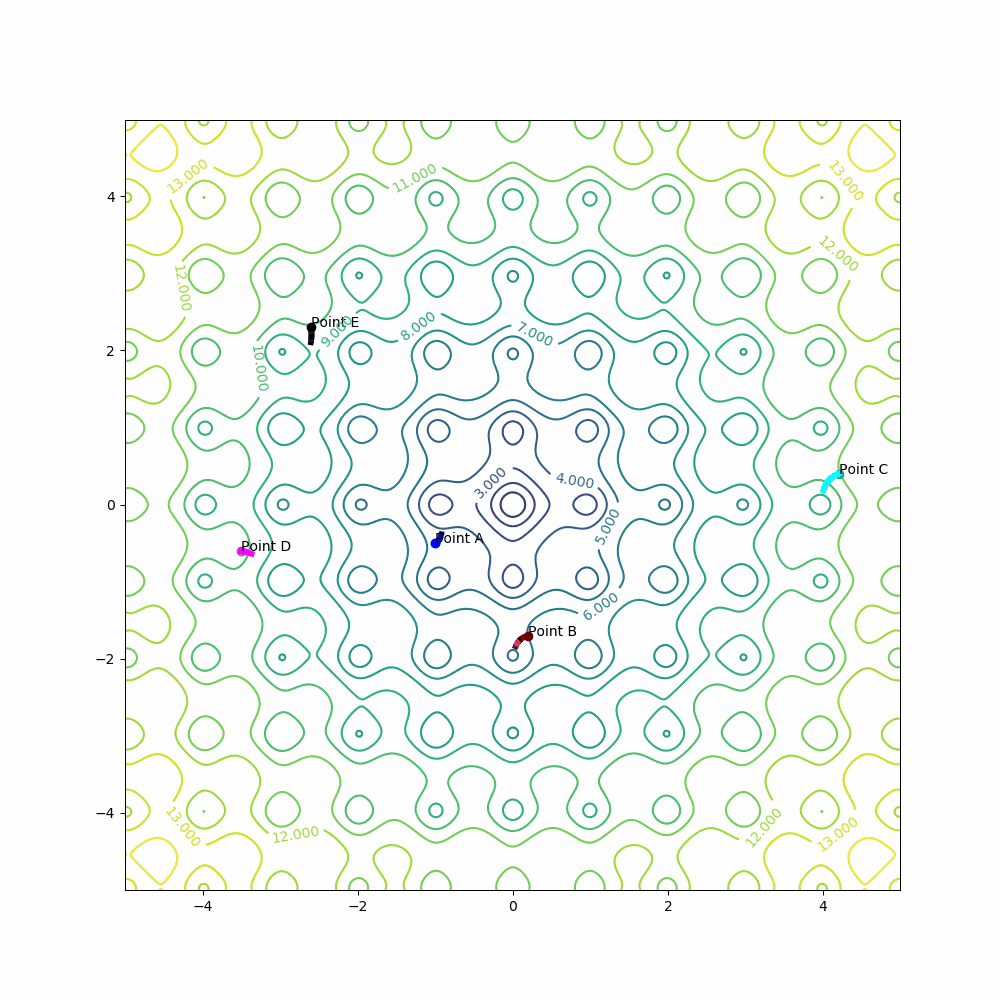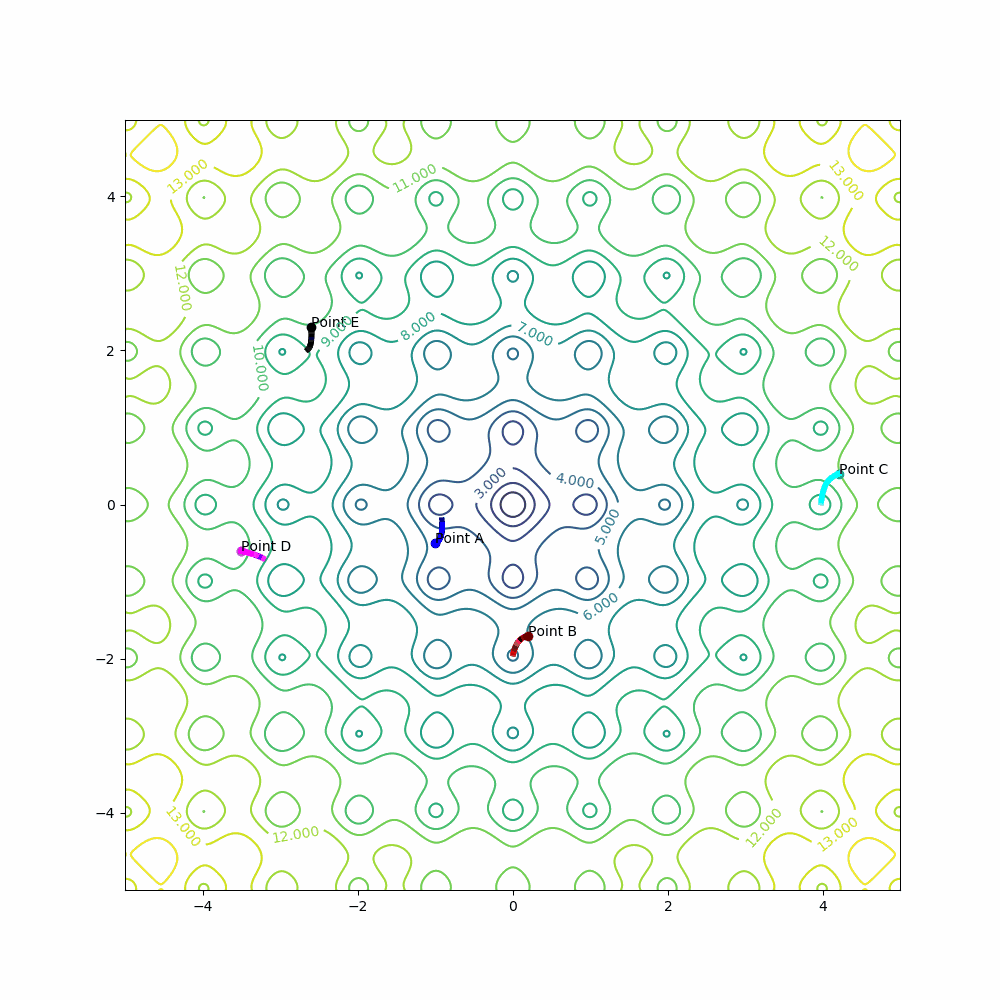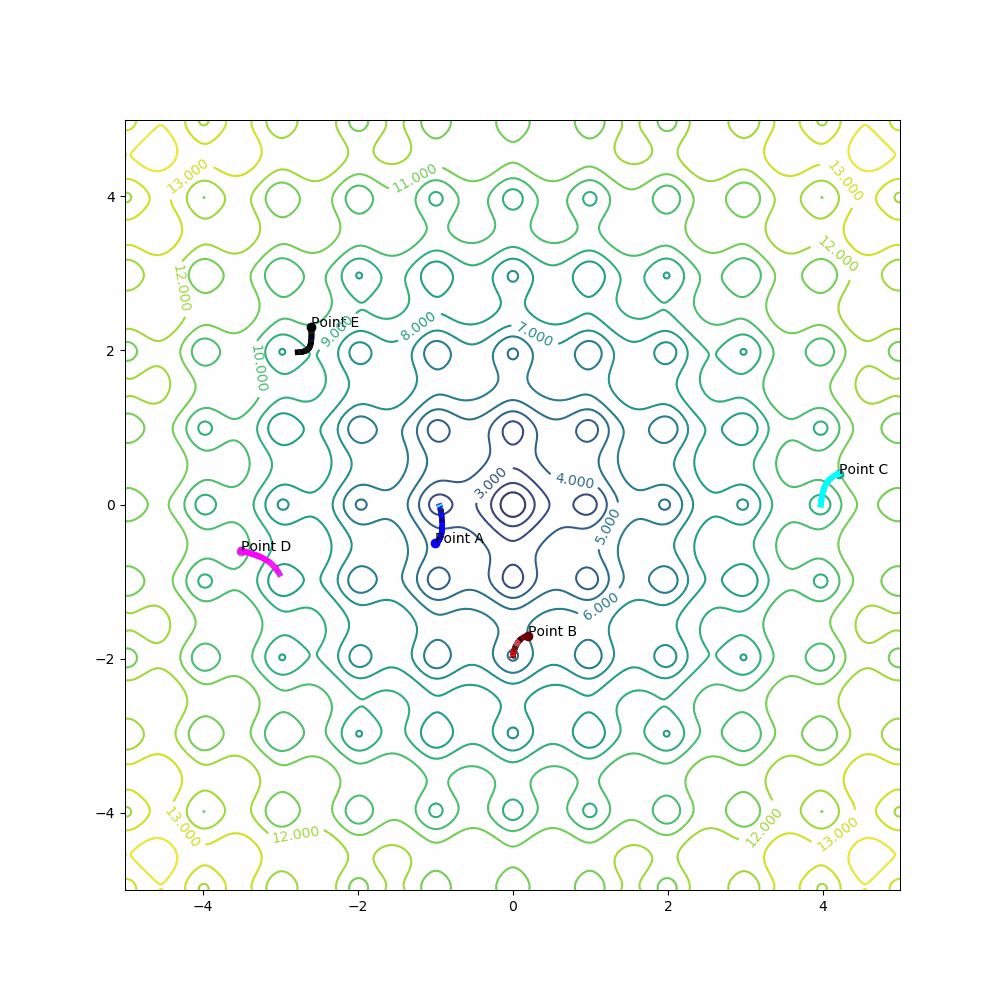
Example for point A:
learning_rate = 0.001
epochs = 150
for iter in range(epochs):
...
A[0] = A[0] - learning_rate * derivative_x(A[0], A[1])
A[1] = A[1] - learning_rate * derivative_y(A[0], A[1])
 |
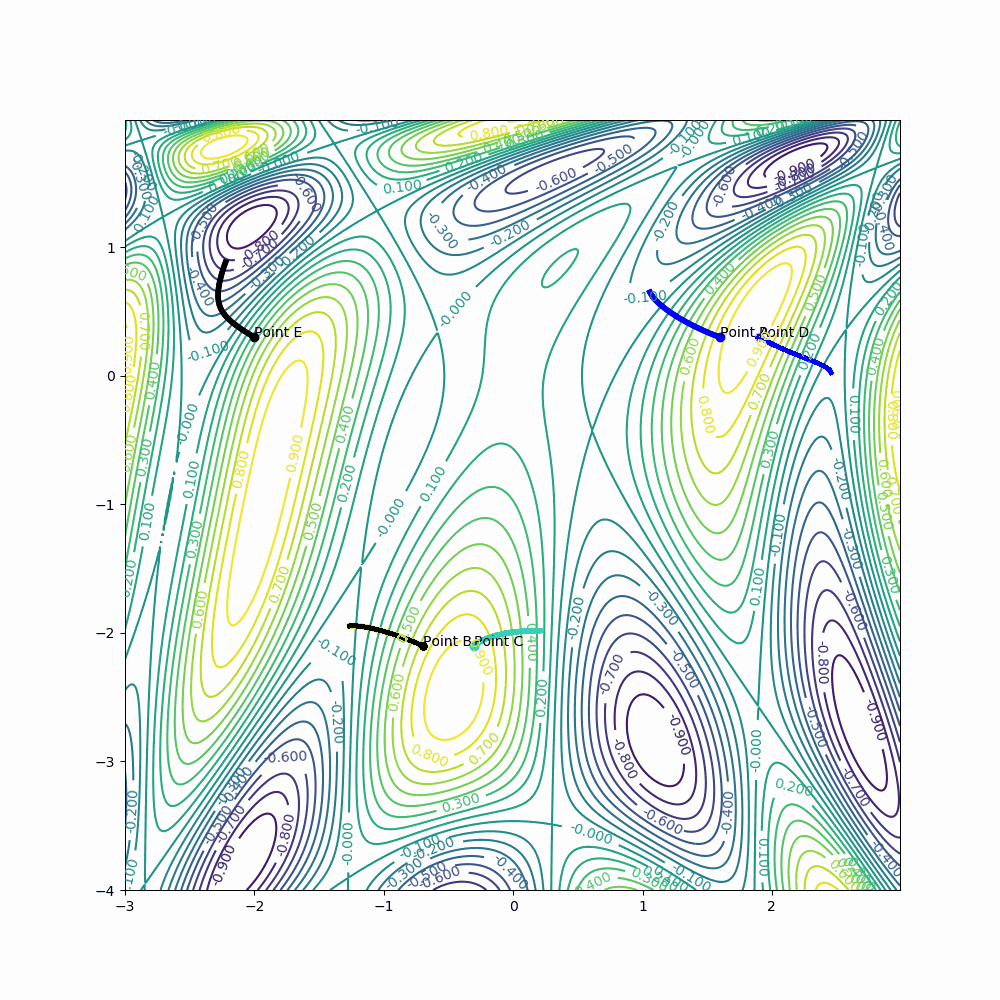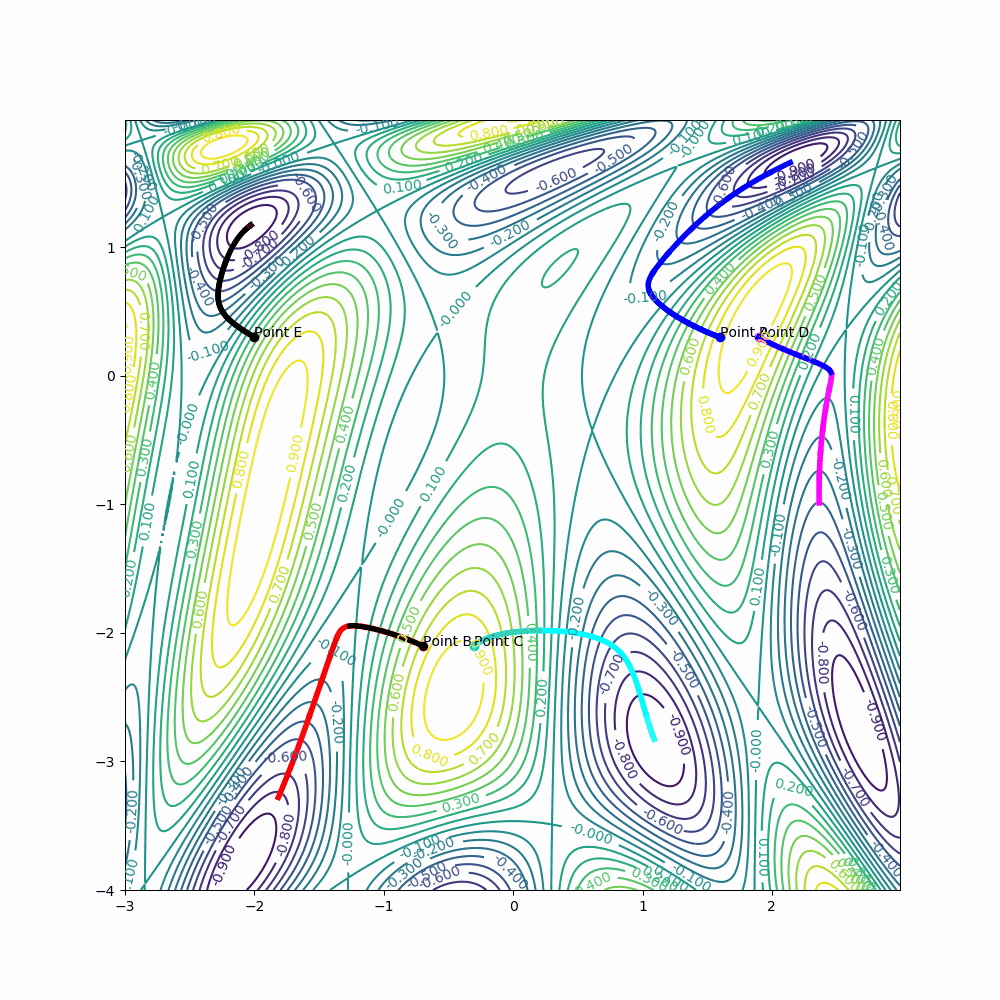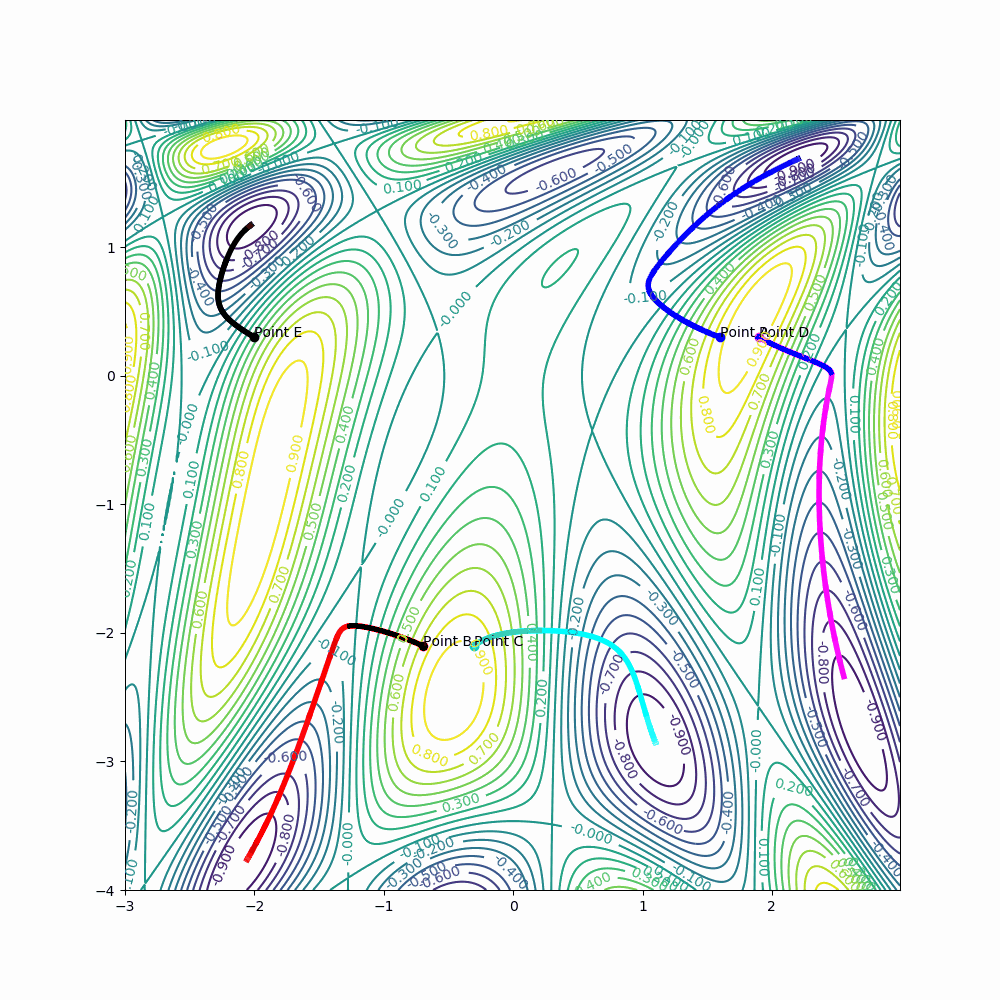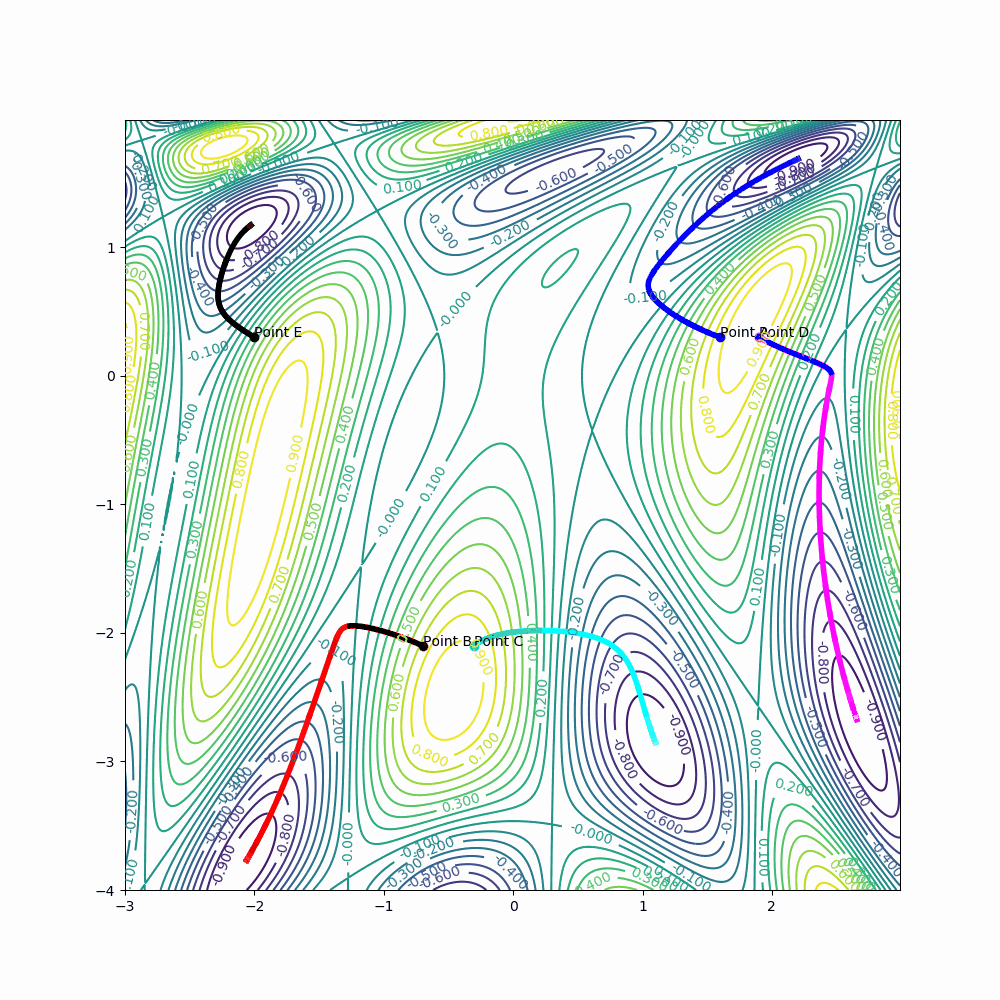 |
 |
See:
Example for point A:
learning_rate = 0.005
epochs = 5000
gamma = 0.997
delta_A = [0,0]
for iter in range(epochs):
...
delta_A[0] = gamma*delta_A[0] + (1 - gamma) * learning_rate * derivative_x(A[0], A[1])
delta_A[1] = gamma*delta_A[1] + (1 - gamma) * learning_rate * derivative_y(A[0], A[1])
A[0] = A[0] - delta_A[0]
A[1] = A[1] - delta_A[1]
 |
 |
 |
 |
 |
 |
 |
 |
 |
See:
Example for point A:
learning_rate = 0.5
epochs = 30
diag_G_A = [0,0]
for iter in range(epochs):
...
diag_G_A[0] = diag_G_A[0] + (derivative_x(A[0], A[1]))**2
diag_G_A[1] = diag_G_A[1] + (derivative_y(A[0], A[1]))**2
A[0] = A[0] - learning_rate * (1/math.sqrt(diag_G_A[0])) * derivative_x(A[0], A[1])
A[1] = A[1] - learning_rate * (1/math.sqrt(diag_G_A[1])) * derivative_y(A[0], A[1])
 |
 |
 |
See:
Example for point A:
learning_rate = 0.2
epochs = 50
gamma = 0.90
# a running average of the magnitudes of recent gradients
grad_ra_A = [0,0]
for iter in range(epochs):
...
grad_ra_A[0] = gamma * grad_ra_A[0] + (1 - gamma) * (derivative_x(A[0], A[1]))**2
grad_ra_A[1] = gamma * grad_ra_A[1] + (1 - gamma) * (derivative_y(A[0], A[1]))**2
A[0] = A[0] - learning_rate * (1/math.sqrt(grad_ra_A[0])) * derivative_x(A[0], A[1])
A[1] = A[1] - learning_rate * (1/math.sqrt(grad_ra_A[1])) * derivative_y(A[0], A[1])
 |
 |
 |
 |
 |
 |
This project is available under the MIT license © Nail Sharipov