AMRICA (AMR Inspector for Cross-language Alignments) is a simple tool for aligning and visually representing AMRs (Banarescu, 2013), both for bilingual contexts and for monolingual inter-annotator agreement. It is based on and extends the Smatch system (Cai, 2012) for identifying AMR interannotator agreement.
It is also possible to use AMRICA to visualize manual alignments you have edited or compiled yourself (see Common Flags).
Download the python source from github.
We assume you have pip. To install the dependencies (assuming you already have graphviz dependencies mentioned below), just run:
pip install argparse_config networkx==1.8 pygraphviz pynlpl
pygraphviz requires graphviz to work. On Linux, you may have to install graphviz libgraphviz-dev pkg-config. Additionally, to prepare bilingual alignment data you will need GIZA++ and possibly JAMR.
./disagree.py -i sample.amr -o sample_out_dir/
This command will read the AMRs in sample.amr (separated by empty lines) and put their graphviz visualizations in .png files located in sample_out_dir/.
To generate visualizations of Smatch alignments, we need an AMR input file with each
::tok or ::snt fields containing tokenized sentences, ::id fields with a sentence ID, and ::annotator or ::anno fields with an annotator ID. The annotations for a particular sentence are listed sequentially, and the first annotation is considered the gold standard for visualization purposes.
If you only want to visualize the single annotation per sentence without interannotator agreement, you can use an AMR file with only a single annotator. In this case, annotator and sentence ID fields are optional. The resulting graph will be all black.
For bilingual alignments, we start with two AMR files, one containing the target annotations and one with the source annotations in the same order, with ::tok and ::id fields for each annotation. If we want JAMR alignments for either side, we include those in a ::alignments field.
The sentence alignments should be in the form of two GIZA++ alignment .NBEST files, one source-target and one target-source. To generate these, use the --nbestalignments flag in your GIZA++ config file set to your preferred nbest count.
Flags can be set either at the command line or in a config file. The location of a config file can be set with -c CONF_FILE at the command line.
In addition to --conf_file, there are several other flags that apply to both monolingual and bilingual text. --outdir DIR is the only required one, and specifies the directory to which we will write the image files.
The optional shared flags are:
--verboseto print out sentences as we align them.--no-verboseto override a verbose default setting.--json FILE.jsonto write the alignment graphs to a .json file.--num_restarts Nto specify the number of random restarts Smatch should execute.--align_out FILE.csvto write the alignments to file.--align_in FILE.csvto read the alignments from disk instead of running Smatch.--layoutto modify the layout parameter to graphviz.
The alignment .csv files are in a format where each graph matching set is separated by an empty line, and each line within a set contains either a comment or a line indicating an alignment. For example:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
The tab-separated fields are the test node index (as processed by Smatch), the test node label, the gold node index, and the gold node label.
Monolingual alignment requires one additional flag, --infile FILE.amr, with FILE.amr set to the location of the AMR file.
Following is an example config file:
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
In bilingual alignment, there are more required flags.
--src_amr FILEfor the source annotation AMR file.--tgt_amr FILEfor the target annotation AMR file.--align_tgt2src FILE.A3.NBESTfor the GIZA++ .NBEST file aligning target-to-source (with target as vcb1), generated with--nbestalignments N--align_src2tgt FILE.A3.NBESTfor the GIZA++ .NBEST file aligning source-to-target (with source as vcb1), generated with--nbestalignments N
Now if --nbestalignments N was set to be >1, we should specify it with --num_aligned_in_file. If we want to count only the top --num_align_read as well.
--nbestalignments is a tricky flag to use, because it will only generate on a final alignment run. I could only get it to work with the default GIZA++ settings, myself.
Since AMRICA is a variation on Smatch, one should begin by understanding Smatch. Smatch attempts to identfy a matching between the variable nodes of two AMR representations of the same sentence in order to measure inter-annotator agreement. The matching should be selected to maximize the Smatch score, which assigns a point for each edge appearing in both graphs, falling into three categories. Each category is illustrated in the following annotation of "It didn't take long."
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
- Instance labels, such as
(instance, t, take-10) - Variable-variable edges, such as
(ARG0, t, i) - Variable-const edges, such as
(polarity, l2, -)
Because the problem of finding the matching maximizing the Smatch score is NP-complete, Smatch uses a hill-climbing algorithm to approximate the best solution. It seeds by matching each node to a node sharing its label if possible and matching the remaining nodes in the smaller graph (hereafter the target) randomly. Smatch then performs a step by finding the action that will increase the score the most by either switching two target nodes' matchings or moving a matching from its source node to an unmatched source node. It repeats this step until no step can immediately increase the Smatch score.
To avoid local optima, Smatch generally restarts 5 times.
For technical details about AMRICA's inner workings, it may be more useful to read our NAACL demo paper.
AMRICA begins by replacing all constant nodes with variable nodes that are instances of the constant's label. This is necessary so we can align the constant nodes as well as the variables. So the only points added to AMRICA score will come from matching variable-variable edges and instance labels.
While Smatch tries to match every node in the smaller graph to some node in the larger graph, AMRICA removes matchings that do not increase the modified Smatch score, or AMRICA score.
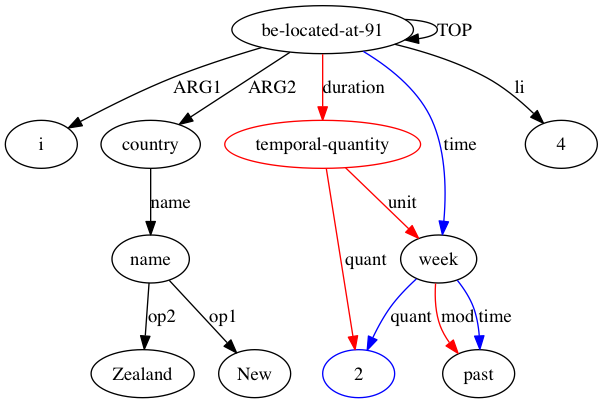
AMRICA then generates image files from graphviz graphs of the alignments. If a node or edge appears only in the gold data, it is red. If that node or edge appears only in the test data, it is blue. If the node or edge has a matching in our final alignment, it is black.
In AMRICA, instead of adding one point for each perfectly matching instance label, we add a point based on a likelihood score on those labels aligning. The likelihood score ℓ(aLt,Ls[i]|Lt,Wt,Ls,Ws) with target label set Lt, source labels set Ls, target sentence Wt, source sentence Ws, and alignment aLt,Ls[i] mapping Lt[i] onto some label Ls[aLt,Ls[i]], is computed from a likelihood that is defined by the following rules:
- If the labels for Ls[aLt,Ls[i]] and Lt[i] match, add 1 to the likelihood.
- Add to the likelihood:
∑j=1|Wt|∑k=1|Ws|ℓ(aLt,Wt[i]=j)ℓ(aWt,Ws[j]=k)ℓ(aWs,Ls[k]=aLt,Ls[i])
- Compute ℓ(aLt,Wt[i]=j) by one of two methods.
- If there are JAMR alignments available, for each JAMR alignment containing this node, 1 point is partitioned among the tokens in the range aligned to the label. If there are no such tokens in the range, the 1 point is partitioned among all tokens in the range.
- If no JAMR alignment contains the ith node, treat it as though the token ranges with no JAMR aligned nodes were aligned to the ith node.
- If there are no JAMR alignments available, then 1 point is partitioned among all tokens string-matching label i.
- If there are JAMR alignments available, for each JAMR alignment containing this node, 1 point is partitioned among the tokens in the range aligned to the label. If there are no such tokens in the range, the 1 point is partitioned among all tokens in the range.
- Compute ℓ(aWs,Ls[k]=aLt,Ls[i]) by the same method.
- Compute ℓ(aWt,Ws[j]=k) from a posterior word alignment score extracted from the source-target and target-source nbest GIZA alignment files, normalized to 1.
- Compute ℓ(aLt,Wt[i]=j) by one of two methods.
In general, bilingual AMRICA appears to require more random restarts than monolingual AMRICA to perform well. This restart count can be modified with the flag --num_restarts.

We can observe the degree to which using Smatch-like approximations (here, with 20 random initializations) improves accuracy over selecting likely matches from raw alignment data (smart initialization). For a pairing declared structurally compatible by (Xue 2014).
- After initialization:

- After bilingual smatch, with errors circled:

For a pairing considered incompatible:
- After initialization:

- After bilingual smatch, with errors circled:

This software was developed partly with the support of the National Science Foundation (USA) under awards 1349902 and 0530118. The University of Edinburgh is a charitable body, registered in Scotland, with registration number SC005336.