Export Notebook - markdown cells not correctly exported to ipynb #1296
Comments
|
Picking this up, as I made the original PR for exporting to notebook. |
|
@dynobo Is the "%%markdown" syntax expected to be like the ipython's "%%markdown" cell magic ? I think in that case, the expected output would be this ?
|

|
@Madhu94 For an example, see the text in this shot of a notebook. The first two cells ("Jupyter Notebook Slides.." and "Overview") are markdown cells: |
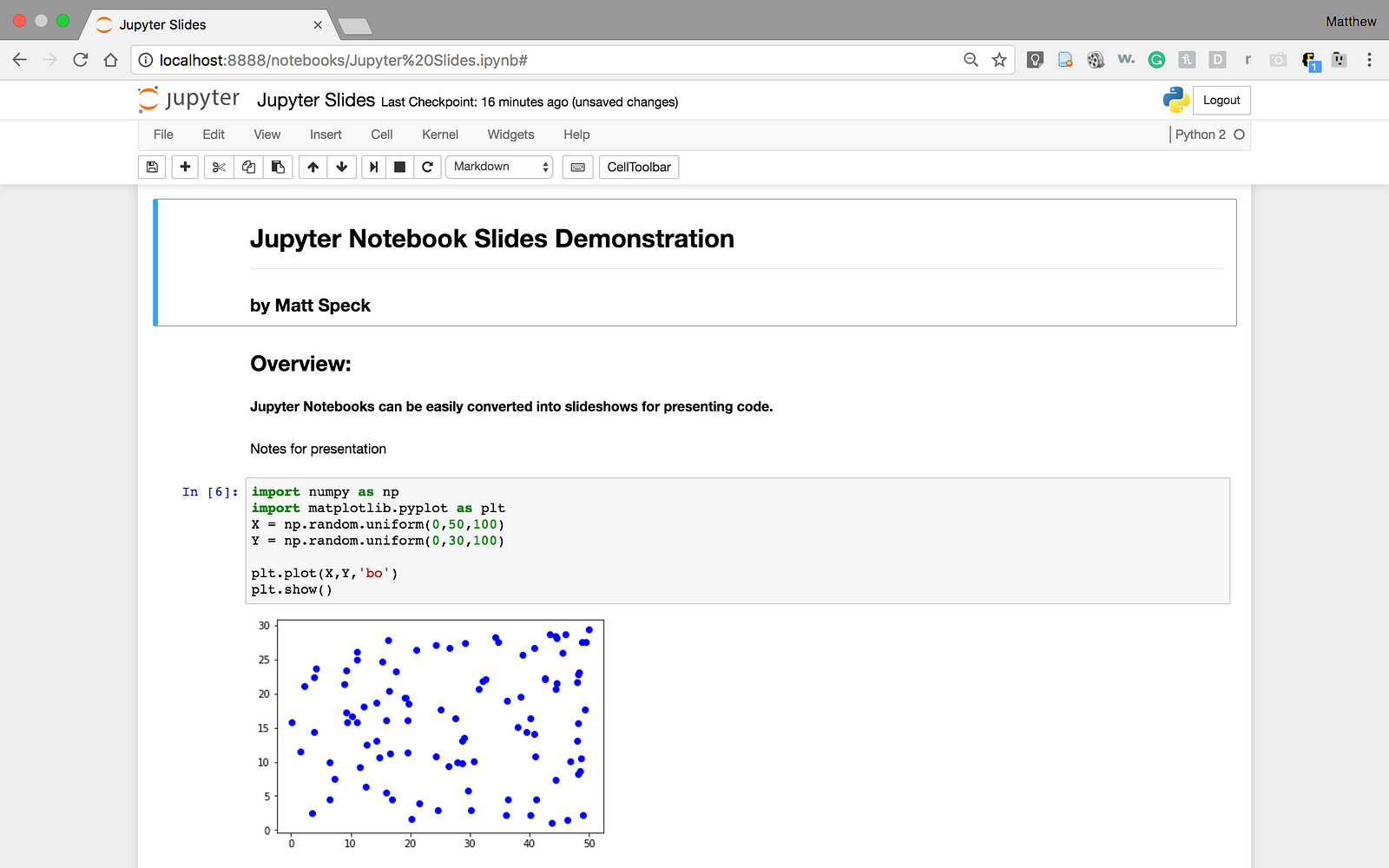
|
My mistake, I thought |
|
@Madhu94: I stumbled upon it through the "rich document" feature, described shortly on the bottom of this page. I expected the markdown-parts of such an document to be exported as markdown-cells even without "%%markdown" syntax (this would be my favourite solution), but as it didn't do this, I thought at least the markdown syntax might be able to handle that. But I want to give a bit background: I like a lot the R-Notebooks, which allow to mix Code and Markdown in the same file. There, I can write everything from top to bottom in a single text file in my IDE, and it can also be read in every simple Text-Editor. In e.g. Jupyter I have to create/move cells in the Web-App, and I need a notebook viewer to render the content. Hydrogen, with "Rich documents" is just soooo close to filling this need, which would be really cool. Unfortunately, as long as a Hydrogen is not "the standard", such a feature still would be quite worthless without being able to export such a Rich Document to Jupyter Notebooks, so I can share it in my university class or something... So, if the markdown-parts of a "Rich document" would be rendered as jupyter-markdown-cells (with, or even better without %%markdown), this would be so perfect. I guess other people knowing R-Notebooks might feel the same... :-) |
|
I'm interested in taking a closer look at this, though I'm about to go on vacation for a week and a half. It seems like it's currently a simple wrapper around hydrogen/lib/export-notebook.js Line 19 in 3291db2 |
|
@kylebarron yes, it would be in commutable. We have actually been talking about refactoring that package. |
|
Hello @dynobo, I see you have previous experience with R markdown notebooks. Have you ever tried to open these documents with Jupyter? There are a few plugins around that allow this. I recommend in particular notedown (many GitHub stars) and jupytext (my contribution). Are you able to run python cells in markdown or R markdown documents in Hydrogen? If yes, you could experiment editing these documents simultaneously in Hydrogen and Jupyter (run |
|
Does this work in Hydrogen export to ipynb? # <markdowncell>
# # Headline1
# - bullet point
# **bold text**As nbconvert seems to support that: http://ipython.org/ipython-doc/2/notebook/nbconvert.html#notebook-json-file-format |
|
Hello @kiwi0fruit , I think there are plans to support this in Hydrogen at some point. For now you can use an independent program named |
|
I think I've narrowed down the issue in Hydrogen. JSON.stringify(store.notebook, null, 2)So the issue here is in Lines 66 to 83 in 1a41f82 To me, it appears the issue is likely in |
|
Actually the |
|
Hello @kylebarron , I think we should use compatible specifications across the multiple implementations of the text to jupyter notebook converters. May I suggest that Hydrogen could use See also the documentation for the |
|
What about Hydrogen having a superset? Something like Hydrogen already supports other cell markers, So we might also allow something like |
|
I think block comment way is more convenient for one way conversion (hydrogen to ipynb). Like in vscode-ipynb-py-convert and pandoctools. # %%
'''
# Header
text.
'''
# %%
print('hello') |
|
Well in the long term I think it's optimal to have two-way conversion in Hydrogen, both to and from Those multiline strings are problematic because, most importantly, you're using Python-specific syntax. Nothing in Hydrogen should be Python specific. Everything should be language agnostic, because we're aiming to support all Jupyter kernels. |
|
If we speak about python only then two way conversion is possible (stringify to python strings). But there would be problems on other languages.
Yep, it's more difficult to implement. Your second concern adds to this (first one does not matter).
|
|
Thanks @kylebarron , @kiwi0fruit ! It's good to have this conversation.
Well, if you choose a superset that we can also implement in
The Spyder team also suggested to represent markdown cells as multiline strings - they like the potential for using f-strings. And Sphinx-Galleries also offer markdown cells as multiline strings. However, we have not yet implemented support for these multiline strings in
|
|
If you want to make it comfortable with in-line comments then you can add Atom hot keys 'uncomment cell' and 'comment cell'.
|
|
Any language with block comments can be used with block comments instead of inline comments the very same way. Not any markdown text can be encoded though. Cases that cannot be encoded via block comments can always be encoded via in-line comments.
|
|
Sorry, I edited my previous post a bit too extensively after posting... I think one of the best and most important features of Hydrogen is its total language agnosticness. I don't think any of the maintainers want to add something to Hydrogen that only works for Python.
Not in the short term, theoretically in the long term, but it really depends if there's a desire for it in the community. |
|
In addition to vscode-ipynb-py-convert the block commented Markdown cells are supported by pandoctools (that uses knitty that uses stitch). And the |
Description:
When exporting a py-File to ipynb-File the Markdown-Cells are exported as Code-Cells, not as Markdown cells.
Steps to Reproduce:
Run "Hydrogen - Export Notebook"
Open the created ipynb-File in Jupyter Notebook, you'll see:
Expected would be a markdown cell:
Versions:
Hydrogen 2.4.1
Atom 1.25.1
Running on Solus Linux
Which OS and which version of Hydrogen and Atom are you running?
Logs:
not relevant
The text was updated successfully, but these errors were encountered: