[cuda] lineinfo for device function #5311
Comments
|
Win 2016 Datacenter, CUDA 10.1, numba 0.48.0, numpy 1.18.1, llvmlite 0.31.0 - you don't even get near the profiling.
|

|
Using the goofy inline-closure format: |

|
hmm... i think this might be a problem in libNVVM in CUDA 10.1. @gmarkall, do you know if there are known problems regarding debug-symbols in newer CUDA. |
|
Yeah, you'll excuse me, I did very minorly goof - 10.2. Forgot we had upgraded. |
|
@sklam If you're referring to the appearance of the message "Debugging support cannot be enabled when the number of debug compile units is more than 1", it's a message I've bumped into before but hadn't yet got around to looking into... I didn't realise it ever did work with 9.2 though. |
|
I've also seen that message a fair few times. |
|
@stuartarchibald, on what hardwares and CUDA versions? |
|
I've seen it with CUDA 10.0 and a V100. |
Stretching memory, but CUDA 10.2 and a GTX970. |
I just noticed that it's documented that only a single module is supported: https://docs.nvidia.com/cuda/nvvm-ir-spec/index.html#source-level-debugging-support:
|
|
Hm... we can possibly prelink the module in llvm before sending it over to nvvm. |
|
Is this one a fundamental limitation or should the prelink workaround fix? |
|
@gmarkall, the doc change first happened in 10.0 (https://docs.nvidia.com/cuda/archive/10.0/nvvm-ir-spec/index.html#source-level-debugging-support). In 9.2 (https://docs.nvidia.com/cuda/archive/9.2/nvvm-ir-spec/index.html#source-level-debugging-support), there were no restriction on "a single debug compile unit" and it works. Why is this restriction needed? I would think that one can use LLVM to link the modules together and the debug symbol will merge fine. If it is not that simple, I don't know what Numba can do to address this problem. @c200chromebook is reporting (at https://gitter.im/numba/numba?at=5f35a6314bb58d3181951aea) that this affects a single kernel case in Numba. Which is odd because there should only be one LLVM module. Unless NVVM is counting the libdevice that we are linking in. |
|
See also the below, which has two items to compile, thus causing a fail. yields This is an idiosyncrasy of the tuple, as you don't get it with: |
|
On master with CUDA 11.2 (NVVM 7.0) line info seems to be available again with
|
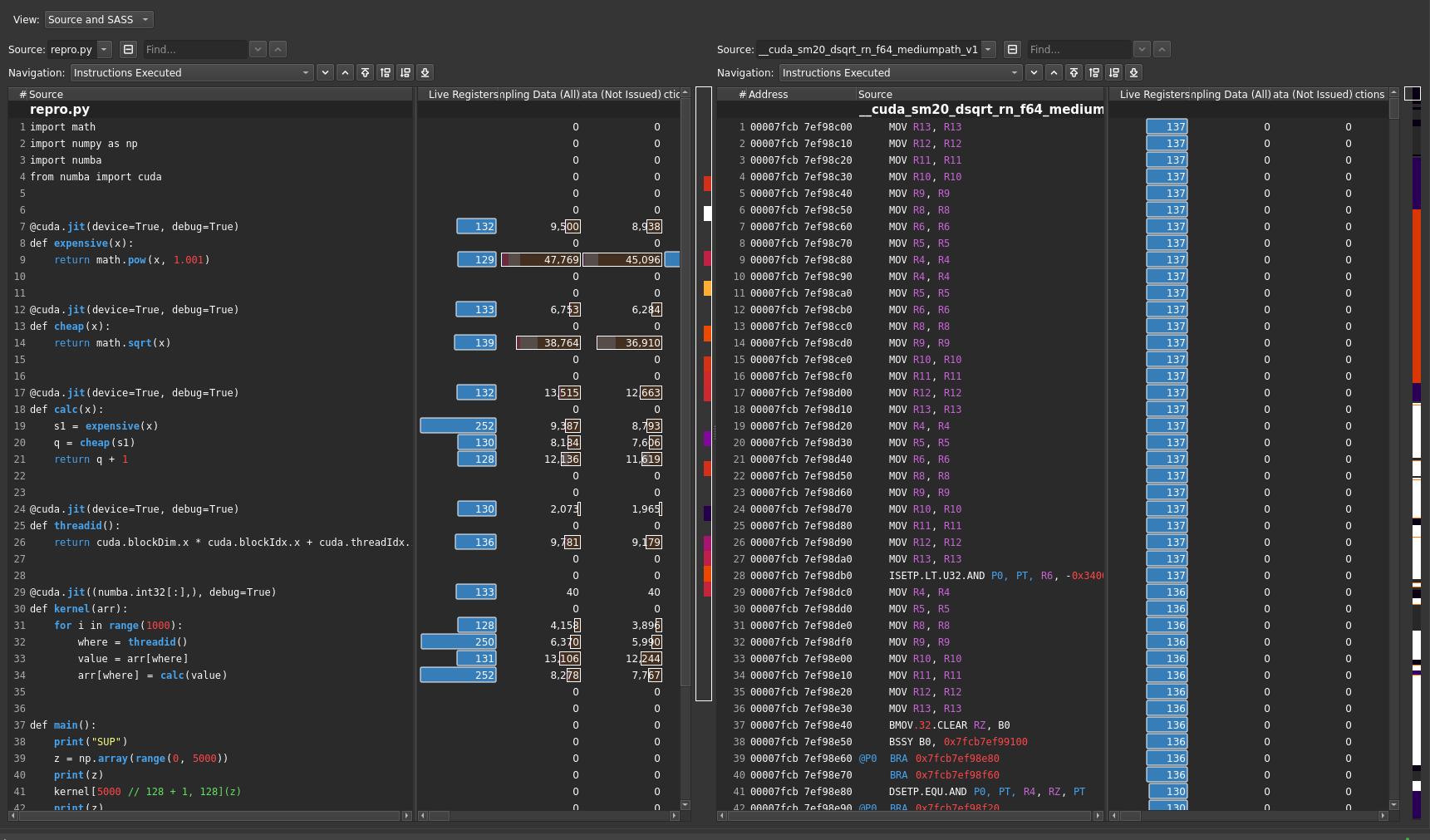
This reproduces for me with CUDA 10.1, but the issue appears to be resolved with CUDA 11.2. |
|
To summarise where I think we are:
@sklam asked earlier:
I don't know the reason for the restriction. I believe that we can conform with this restriction in Numba by changing Lines 114 to 115 in 81f7082 so that instead of passing a list of the IR for all modules into Line 139 in 81f7082 we'd have multiple PTXs to add. I hadn't done this by default so far because it seems to result in less inlining and less efficient code in the non-debug case (I did try it, but couldn't get the linker to inline the PTX as eagerly as NVVM seems to inline IR for device functions). For debug, this isn't a problem though, as we're not going to be expecting much / any inlining. We have this hack in the code: numba/numba/cuda/cudadrv/nvvm.py Lines 708 to 728 in 81f7082 which is intended to workaround the fact we are passing in multiple modules when |
Includes: - Calls `llvm_to_ptx` once for each IR module for debug. - Don't adjust linkage of functions in linked modules when debugging, because we need device functions to be externally visible. - Fixed setting of NVVM options when calling `compile_cuda` from kernel compilation and device function template compilation. - Removes debug_pubnames patch Outcomes: - The "Error: Debugging support cannot be enabled when number of debug compile units is more than 1" message is no longer produced with NVVM 3.4. - CUDA test suite passes, apart from those tests that check PTX, because get_asm_str() is returning a list of strings when debug is True. - NVVM 7.0: Everything still seems to "work" as much as it did before. Stepping may be more stable, but this needs a bit more verification (could just be my late night perception). Testing outside the test suite: - Reproducers from Issue numba#5311 in the post description, and from c200chromebook. - The code posted in Discourse thread 449, with debug=True, opt=0 added. These will need to be made into appropriate test cases - they exposed some problems with the linkage.
I've tried implementing this strategy and removing the debug_pubnames patching in: gmarkall@ce840bc It fixes the failure to compile with NVVM 3.4. Things seem to work as well as they did before with NVVM 7.0. Stepping line-by-line seems like it might be more stable, but I'm not sure if that's just my perception - I need to do some more careful experiments. |
|
PR #6841 includes a fix for the message "Error: Debugging support cannot be enabled when number of debug compile units is more than 1" using the strategy described above - since lineinfo is working with NVVM 7.0, and the error message is resolved with NVVM 3.4, I will consider this issue resolved once that PR is merged. |
Related gitter discussion starting at here and here.
Reproducer:
Run the above with:
On my OSX 10.13 with CUDA 9.2, we can see some line-info in the
profile_outputusing NVVP:The "inline-closure" version (this style: https://gist.github.com/c200chromebook/d131322c918b142f14f40c9b3583cc6d) looks like:

@c200chromebook, can you tell us what you see?
The text was updated successfully, but these errors were encountered: