Design
Consistency in distributed systems is a difficult problem to solve, especially while trying to maintain adequate levels of performance and availability. One of the notable sources of inconsistencies in contemporary event-driven and microservices architectures is the inherent lack of atomicity around messaging guarantees, leading to long-term, imperceptible corruption of system state. The phrase "eventual inconsistency" has become ever so apt in relation to the design and construction of modern applications.
By and large, these problems are not new. Discussed in seminal papers during the 1980s and '90s, the challenges of maintaining state in distribute and concurrent systems have been well-understood in the academic community, as well as in the broader industry. In the specific context of atomic messaging, numerous patterns exist for solving these problems, but overwhelmingly, they are little more than guidelines. However straightforward they may appear, their implementation is rarely trivial and most often not tested to the extent warranted by their role.
The overarching motivation behind goharvest was to create a robust, highly performant implementation of the Transactional Outbox pattern — packaged in a manner that makes it trivially reusable across a broad range of event-driven applications, irrespective of their implementation technology.
Harvesting of the outbox table seems straightforward on the face of it, but there are several notable challenges:
- Contention — although multiple processes may write to a single outbox table (typically, multiple instances of some µ-service), only one process should be responsible for publishing records. Without exclusivity, records may be published twice or out-of-order by contending processes.
- Availability — when one publisher fails, another should take over as soon as possible, with minimal downtime. The failure detection mechanism should be robust with respect to false positives; otherwise, the exclusivity constraint may be compromised.
- Causality — multiple database write operations may be happening concurrently, and some of these operations may be ordered relative to each other. Publishing order should agree with the causal order of insertion. This is particularly challenging as transactions may be rolled back or complete out of order, leaving gaps in identifiers that may or may not eventually be filled.
- At-least-once delivery — ensuring messages are delivered at least once in their lifetime.
- State — the publisher needs to maintain the state of its progress so that it can resume publishing if the process is brought down, or transfer its state over to a new publisher if necessary.
goharvest can be embedded into an existing Go process, or bootstrapped as a standalone application using the reaper CLI. The latter is convenient where the application writing to the outbox is not implemented in Go, in which case reaper can be deployed as a sidecar. goharvest functions identically in both deployment modes; in fact, reaper just embeds the goharvest library, adding some config on top.
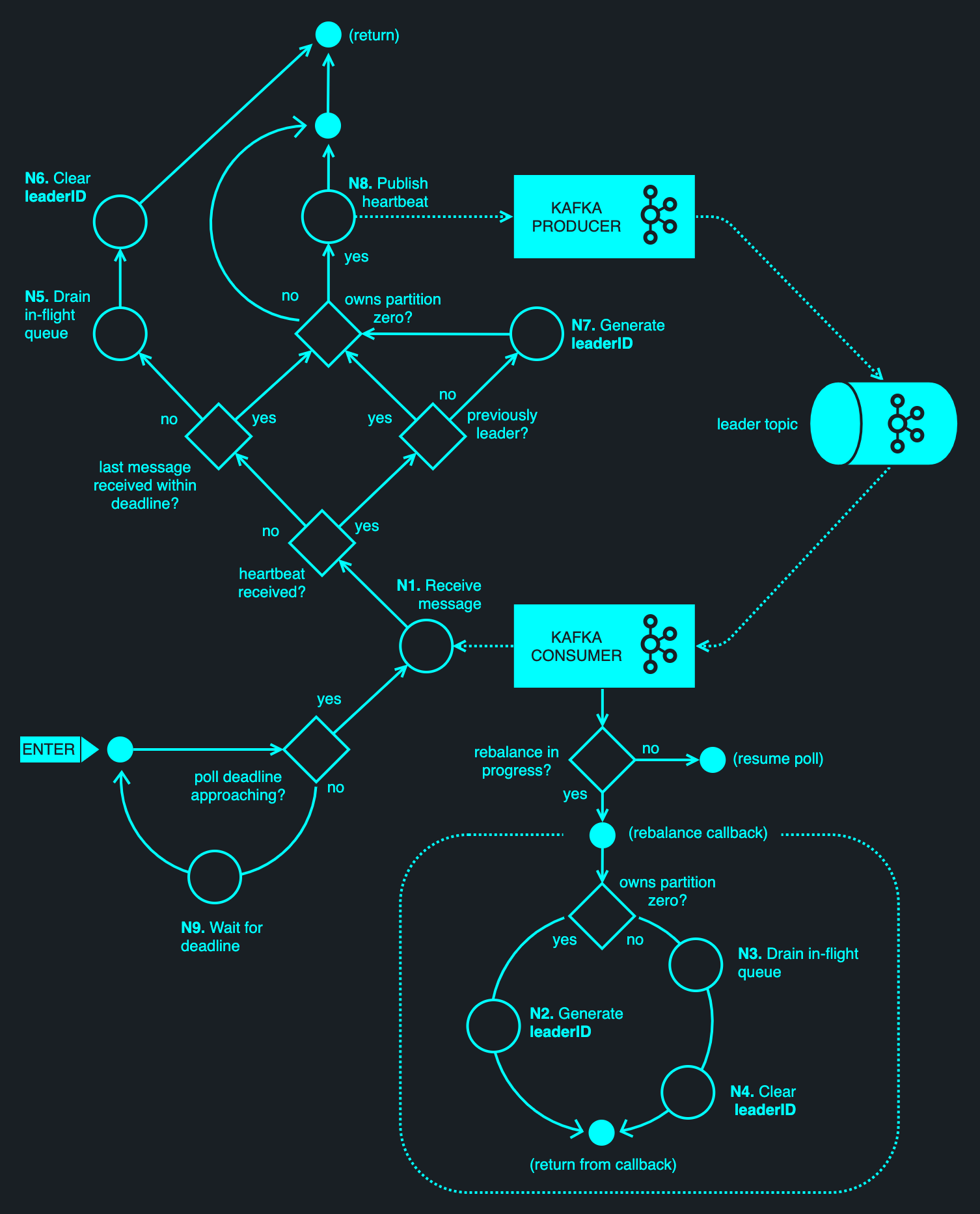
goharvest solves #1 and #2 by using a modified form of the NELI protocol called Fast NELI. Rather than embedding a separate consensus protocol such as PAXOS or Raft, NELI piggy-backs on Kafka's existing leader election mechanism — the one used for electing group and transaction coordinators within Kafka. NELI provides the necessary consensus without forcing the goharvest maintainers to deal with the intricacies of group management and atomic broadcast, and without requiring additional external dependencies.
When goharvest starts, it does not know whether it is a leader or a standby process. It uses a Kafka consumer client to subscribe to an existing Kafka topic specified by Config.LeaderTopic, bound by the consumer group specified by Config.LeaderGroupID. As part of the subscription, goharvest registers a rebalance callback — to be notified of partition reassignments as they occur.
Note: The values
Config.LeaderTopicandConfig.LeaderGroupIDshould be chosen distinctly for each logical group of competing processes, using a name that clearly identifies the application or service. For example,billing-api.
No matter the chosen topic, it will always (by definition) have at least one partition — partition zero. It may carry other partitions too — indexes 1 through to N-1, where N is the topic width, but we don't care about them. Ultimately, Kafka will assign at most one owner to any given partition — picking one consumer from the encompassing consumer group. (We say 'at most' because all consumers might be offline.) For partition zero, one process will be assigned ownership; others will be kept in a holding pattern — waiting for the current assignee to depart or for Kafka to rebalance partition assignments.
Having subscribed to the topic, the client will repeatedly poll Kafka for new messages. Kafka uses polling as a way of verifying consumer liveness. (Under the hood, a Kafka client sends periodic heartbeats, which are tied to topic polling.) Should a consumer stop polling, heartbeats will stop flowing and Kafka's group coordinator will presume the client has died — reassigning partition ownership among the remaining clients. The client issues a poll at an interval specified by Config.Limits.MinPollInterval, defaulting to 100 ms.
The rebalance callback straightforwardly determines leadership through partition assignment, where the latter is managed by Kafka's group coordinator. The use of the callback requires a stable network connection to the Kafka cluster; if a network partition occurs, another client may be granted partition ownership — an event which is not synchronized with the outgoing leader.
Note: While Kafka's internal heartbeats are used to signal client presence to the broker, they are not suitable for the safe handling of network partitions from a client's perspective. During a network partition, the rebalance listener will be invoked at some point after the session times out on the client, by which time the partition may be reassigned on the broker.
In addition to observing partition assignment changes, the owner of partition zero periodically publishes a heartbeat message to Config.LeaderTopic. The client also consumes messages from that topic — effectively observing its own heartbeats, and thereby asserting that it is connected to the cluster and still owns the partition in question. If no heartbeat is received within the period specified by Config.Limits.ReceiveDeadline (5 seconds by default), the leader will take the worst-case assumption that the partition will be reassigned, and will voluntarily relinquish leader status. If connectivity is later resumed while the process is still the owner of the partition on the broker, it will again receive a heartbeat, allowing it to resume the leader role. If the partition has been subsequently reassigned, no heartbeat messages will be received upon reconnection and the client will be forced to rejoin the group — the act of which will invoke the rebalance callback, effectively resetting the client.
Once a goharvest client assumes leader status, it will generate a random UUID named leaderID and will track that UUID internally. Kafka's group coordinator may later choose to reassign the partition to another goharvest client. This would happen if the current leader times out, or if the number of contending goharvest instances changes. (For example, due to an autoscaling event.) Either way, a leadership change is identified via the rebalance callback or the prolonged absence of heartbeats. When it loses leader status, the client will clear the internal leaderID. Even if the leader status is later reverted to a previous leader, a new leaderID will be generated. (The old leaderID is never reused.) In other words, the leaderID is unique across all views of a group's membership state.
The diagram below illustrates the NELI leader election protocol, which is provided by the goNELI library.
Problems #3, #4 and #5 are collectively solved with one algorithm, which has since been coined mark-purge/reset (MP/R). goharvest requires an outbox table with the following basic structure. (The real table has more columns; the simplified one below is used to illustrate the concept.).
| Column(s) | Type | Unique? | Description |
|---|---|---|---|
| id | serial | yes | A monotonically increasing, database-generated ID. |
| payload | doesn't matter | doesn't matter | One or more columns that describe the contents of the record and how the corresponding message should be published to Kafka. |
| ... | ... | ... | ... |
| leader_id | varchar | no | The unique identifier of the current leader process that marks a record as being in flight. |
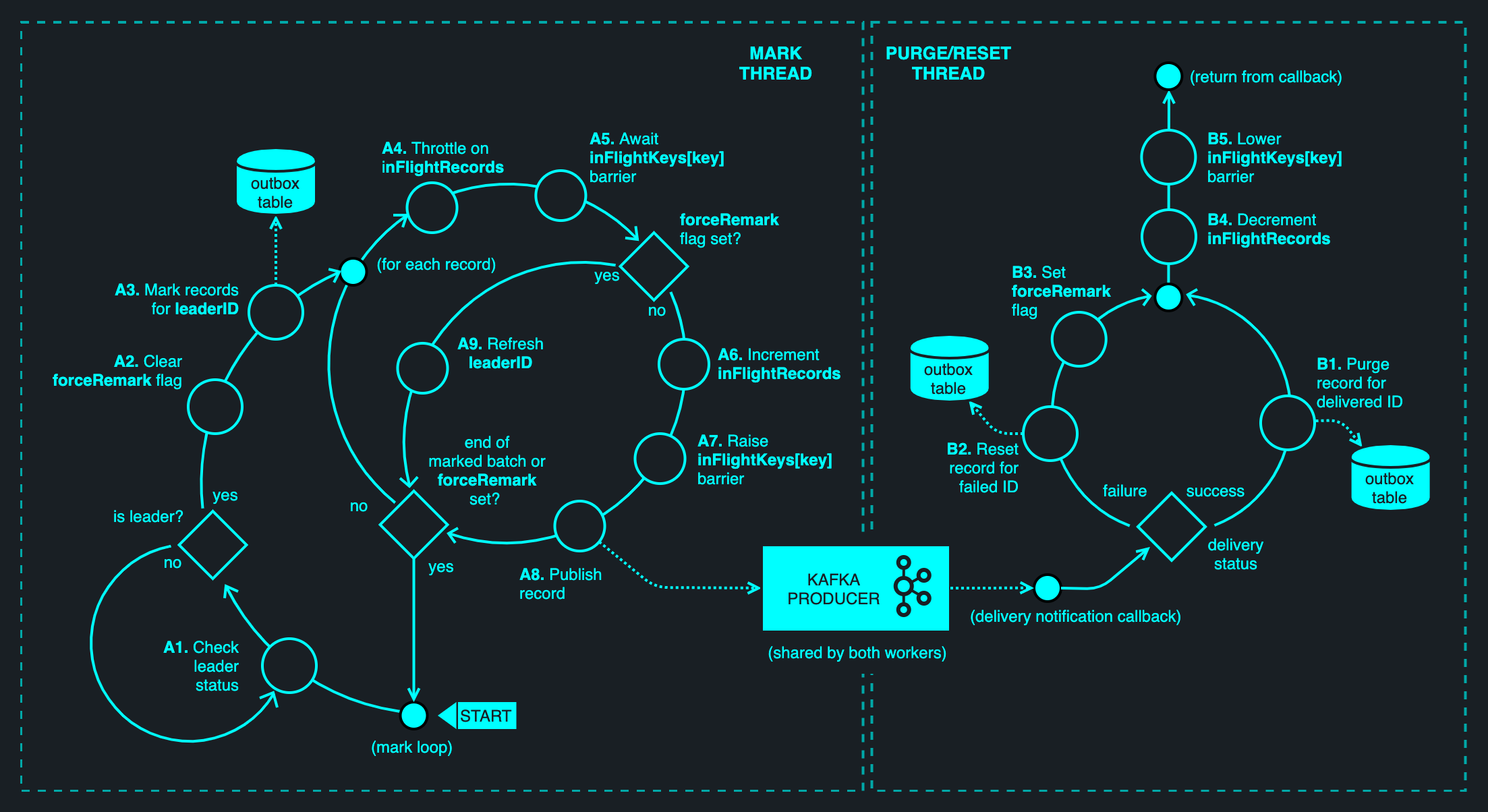
In its most basic form, the algorithm operates concurrently across two Goroutines — a mark thread and a purge/reset thread. (Using the term thread for brevity.) Note, the goharvest implementation is significantly more involved, employing a three-stage pipeline with sharding and several concurrent producer clients to maximise throughput. The description here is of the minimal algorithm.
Once leadership has been acquired, the mark thread will begin repeatedly issuing mark queries in a loop, interleaved with periodic polling of Kafka to maintain liveness. Prior to marking, the loop clears a flag named forceRemark. (More on that in a moment.)
A mark query performs two tasks in one atomic operation:
- Identifies the earliest records in the outbox table that either have a
nullleader_id, or have aleader_idvalue that is different from the currentleaderIDof the harvester. This intermediate set is ordered by theidcolumn, and limited in size — so as to avoid long-running queries. - Changes the
leader_idattribute of the records identified in the previous step to the suppliedleaderID, returning all affected records.
Note: Both Oracle and Postgres allow the above to be accomplished efficiently using a single
UPDATE... SET... RETURNINGquery. SQL Server supports a similar query, using theOUTPUTclause. Other databases will require a transaction to execute the above atomically.
The returned records are sorted by id before being processed. Although the query operates on an ordered set internally for the UPDATE clause, the records emitted by the RETURNING clause may be arbitrarily ordered.
Marking has the effect of escrowing the records, tracking the leader's progress through the record backlog. Once the query returns, the marker may enqueue the records onto Kafka. The latter is an asynchronous operation — the records will be sent sometime in the future and, later still, they will be acknowledged on the lead broker(s) and all in-sync replicas. In the meantime, the marking of records may continue (subject to the throttle and barrier constraints), potentially publishing more records as a result. For every record published, the mark thread increments an atomic counter named inFlightRecords, tracking the number of in-flight records. A throttle is applied to the marking process: at most Config.Limits.MaxInFlightRecords may be outstanding before marking is allowed to resume. This value is 1,000 records by default. (See the FAQ for an explanation). In addition to inFlightRecords, a scoreboard named inFlightKeys[key] is used to attribute individual counters for each record key, effectively acting as a synchronization barrier — such that at most one record may exist in flight for any given key. (Explained in the FAQ.)
Note: A scoreboard is a compactly represented map of atomic counters, where a counter takes up a map slot only if it is not equal to zero.
At some point, acknowledgements for previously published records will start arriving, processed by the purge/reset thread. (The combination of the producer client's outbound buffer and asynchronous delivery report handling enables the pipelining of the send and acknowledge operations.) For every acknowledged (meaning it has been durably persisted with Kafka) record, the delivery handler will execute a purge query. This involves deleting the record corresponding to the ID of the acknowledged message. Once a record is deleted, there is no more work to be done for it. The inFlightRecords counter is decremented, and the corresponding inFlightKeys[key] barrier is lowered — permitting the next record to be dispatched for the same key.
Owing to the unreliable nature of networks and I/O devices, there may be an error publishing the record. If an error is identified, we need a way of telling the marking process to re-queue it. This is done using a reset query, clearing the leader_id attribute for the record in question. Having reset the leader ID, we set the forceRemark flag, which was mentioned earlier — signalling to the mark thread that its recently marked records are no longer fit for publishing, in that an older record has since been reinstated. Afterwards, inFlightRecords is decremented and the inFlightKeys[key] barrier is lowered. On the other side, the mark thread will detect this condition upon entering the inFlightKeys[key] barrier, aborting the publishing process and generating a new leader ID. This has the effect of remarking any unacknowledged records, including the recently reset record.
The following diagram illustrates the MP/R algorithm. Each of the numbered steps is explained below.
| Variable | Type | Description | Used by |
|---|---|---|---|
leaderID |
UUID |
The currently assigned leader ID | Marker thread |
inFlightRecords |
Atomic int64 counter |
Tracks the number of records sent, for which delivery notifications are still outstanding. | Both threads |
inFlightKeys |
Atomic scoreboard of counters (or bool flags), keyed by a string record key |
Tracks the number of in-flight records for any given record key. Each value can only be 0 or 1 (for integer-based implementations), or false/true for Boolean flags. |
Both threads |
forceRemark |
Atomic bool
|
An indication that one or more sent records experienced delivery failures and have been re-queued on the outbox. | Both threads, but only the mark thread may clear it. |
consumer |
Kafka consumer instance | Interface to Kafka for the purpose of leader election. | Marker thread |
producer |
Kafka producer instance | Interface to Kafka for publishing outbox messages | Both threads. The mark thread will publish records; the purge/reset thread will handle delivery notifications. |
| Step | Description | ||||
|---|---|---|---|---|---|
| A1 | Check leader status. | ||||
| Condition | Client has leader status (meaning it is responsible for harvesting): | ||||
| A2 | Clear the forceRemark flag, giving the purge/reset thread an opportunity to raise it again, should a delivery error occur. |
||||
| A3 | Invoke the mark query, marking records for the current leaderID and returning the set of modified records. |
||||
| Loop | For each record in the marked batch: | ||||
| A4 | Drain the inFlightRecords counter up to the specified Config.MaxInFlightRecords. |
||||
| A5 | Drain the value of inFlightKeys[key] (where key is the record key), waiting until it reaches zero. At zero, the barrier is effectively lowered, and the thread may proceed. No records for the given key should be in flight upon successful barrier entry. |
||||
| Condition |
The forceRemark flag has been not been set (implying that there were no failed delivery reports): |
||||
| A6 | Increment the value of inFlightRecords. |
||||
| A7 | Increment the value of inFlightKeys[key], effectively raising the barrier for the given record key. |
||||
| A8 | Publish the record to Kafka, via the producer client shared among the mark and purge/reset threads. Publishing is asynchronous; messages will be sent at some point in the future, after the send method returns. | ||||
| Condition | The forceRemark flag has been set by the purge/reset thread, implying that at least one failed delivery report was received between now and the time of the last mark. |
||||
| A9 | Refresh the local leaderID by generating a new random UUID. Later, this will have the effect of remarking in-flight records. |
||||
| Until | The forceRemark flag has been set or there are no more records in the current batch. |
||||
| Step | Description | ||||
|---|---|---|---|---|---|
| Condition | A message was delivered successfully: | ||||
| B1 | Invoke the purge, removing the outbox record corresponding to the ID of the delivered message. |
||||
| Condition | Delivery failed for a message: | ||||
| B2 | Invoke the query, setting the leader_id attribute of the corresponding outbox record to null. This brings it up on the marker's scope. |
||||
| B3 | Set the forceRemark flag, communicating to the mark thread that at least one record from one of its previous mark cycles could not be delivered. |
||||
| B4 | Decrement the count of inFlightRecords, releasing any active throttles. |
||||
| B5 | Decrement inFlightRecords[key] for the key of the failed record, thereby lowering the barrier. |
||||
| Return from the delivery notification callback. | |||||
Causality is satisfied by observing the following premise:
Given two causally related transactions T0 and T1, they will be processed on the same application and their execution must be serial. Assuming a transaction isolation level of Read Committed (or stricter), their side-effects will also appear in series from the perspective of an observer — the
goharvestmarker. In other words, it may observe nothing (if neither transaction has completed), just T0 (if T1 has not completed), or T0 followed by T1, but never T1 followed by T0. (Transactions here refer to any read-write operation, not just those executing within a demarcated transaction scope.)
Even though marking is always done from the head-end of the outbox table, it is not necessarily monotonic due to the sparsity of records. The marking of records will result in them being skipped on the next pass, but latent effects of transactions that were in flight during the last marking phase may materialise 'behind' the marked records. This is because not all records are causally related, and multiple concurrent processes and threads may be contending for writes to the outbox table. Database-generated sequential IDs don't help here: a transaction T0 may begin before an unrelated T1 and may also obtain a lower number from the sequence, but it may still complete after T1. In other words, T1 may be observed in the absence of T0 for some time, then T0 might appear later, occupying a slot before T1 in the table. This phenomenon is illustrated below.
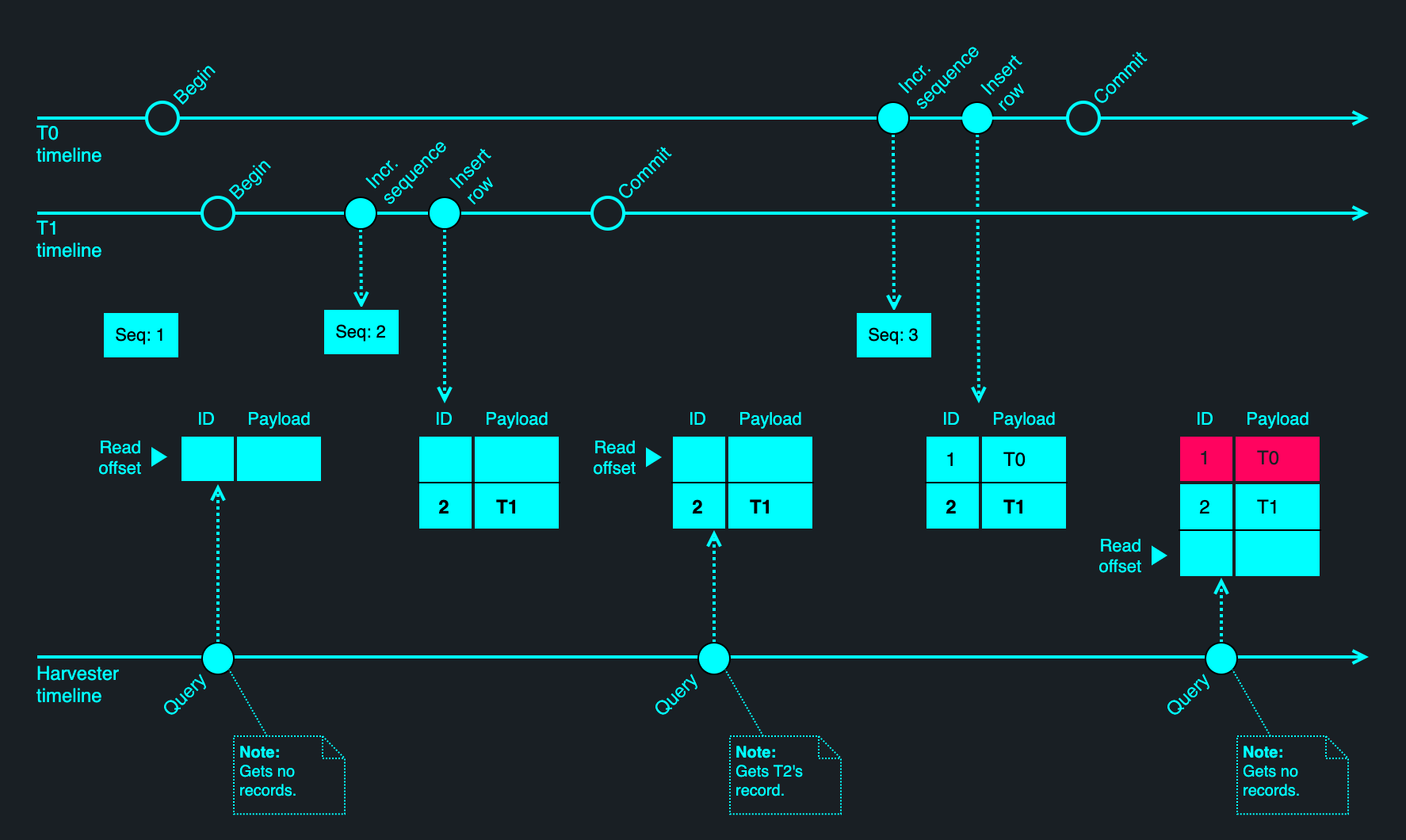
Even though 'gaps' may be filled retrospectively, this only applies to unrelated record pairs. This is not a problem for MP/R because marking does not utilise an offset; it always starts from the top of the table. Any given marking pass will pick up causally-related records in their intended order, while unrelated records may be identified in arbitrary order. (Consult the Comparison of harvesting methods for more information on how MP/R compares to its alternatives.) To account for delivery failures and leader takeovers, the use of a per-key barrier ensures that at most one record is in an indeterminate state for any given key at any given time. Should that record be retried for whatever reason — on the same process or a different one — the worst-case outcome is a duplicated record, but not one that is out of order with respect to its successor or predecessor.
State management is simplified because the query always starts at the head-end of the outbox table and only skips those records that the current leader has processed. There is no need to track the offset of the harvester's progress through the outbox table. Records that may have been in-flight on a failed process are automatically salvaged because their leader_id value will not match that of the current leader. This makes MP/R unimodal — it takes the same approach irrespective of whether a record has never been processed or because it is no longer being processed. In other words, there are no if statements in the code to distinguish between routine operation and the salvaging of in-flight records from failed processes.
![]()