Task stealing with CL deques #29
Conversation
ed28306
to
9f1912f
Compare
|
(rebased to pick up #30) |
|
I had a think about formalizing how multi_channel is turning a non blocking structure into a blocking one. If Thread A is enqueuing data and Thread B is dequeuing then Each of A1, A2, B1, B2, B3 are ordered in the sense that completion is either Ax < By or Bx < Ay. |
|
I've implemented two improvements:
The big benchmarks now look like this; Zen2 (not isolated) sandmark Broad brush, if you want to scale the task stealing is the way to go. The benchmarks for the standard sizes show: There is a single regression for our
I think we could do things about the first: we could throttle how we wake up blocked waiters and also limit the number of stealing domains. I'm in two minds about if we should pursue that in this PR or as follow ups. |




|
So I did a bit more investigation on the evolutionary_algorithm results and found a memory bug. The tasks in the deque arrays will be overwritten, however all the memory held in the task closures are kept there until the memory in the deque array is overwritten. I have implemented a fix where the deque array elements hold a reference to the item; this reference is clobbered when taking tasks. You can't touch the array itself in A rerun of the big benchmarks got me: A rerun of the standard size benchmarks got me: There remains something a bit odd about evolutionary algorithm that I don't fully understand - it looks like we do differing amounts of GC work with the old vs new code. The deques are causing about 20% more minor GCs, which is odd as I can't see significant extra allocations in the domainslib structures themselves: |





Just to connect various folks who might be interested in this, @fpottier and his students were looking at instances where Multicore OCaml explicitly takes advantage of data racy behaviours for improving performance. This looks like one. But @ctk21 mentioned that we need acquire release atomics which the OCaml memory model does not support (yet). @stedolan mentioned that while acquire load fits nicely into the model, store-release does not. |
| } | ||
|
|
||
| let create () = { | ||
| top = Atomic.make 1; |
There was a problem hiding this comment.
Why are these 1 and not 0?
|
Can you merge with the master again? The diff includes changes already included in master, and it makes it hard to read. See https://github.com/ocaml-multicore/domainslib/pull/29/files#diff-1a51aea47d0ef65c5073e293d19298451614febc83360af128ded914dbb6599bL39 |
structure with blocking
…ceived in check_waiters
…ght bits of the dls lookups; fix multi channel array size config
…he array in steal for ws_deque
f5d95d2
to
2d61ed8
Compare
Rebased to master and pushed! |
To expand a bit. We can implement the CL deque using the In other parallel data structures, for example a SPSC ring buffer, using acquire-release can be important to get a really low overhead implementation. However there is a problem to solve which is if the OCaml multicore memory-model can be extended to accommodate acquire-release atomics. |
This PR is an implementation of Chase Lev deques organised for task stealing; as is traditional in Cilk, Concurrent bags, etc.
The basic idea is:
pushwithout synchronous operations andpopwill not need to synchronize with other domains unless there is only 1 element in the deque.stealtasks from randomly chosen deques belonging to other domains.recv_block_spins.Early benchmarking results (detuned Zen2 with sandmark
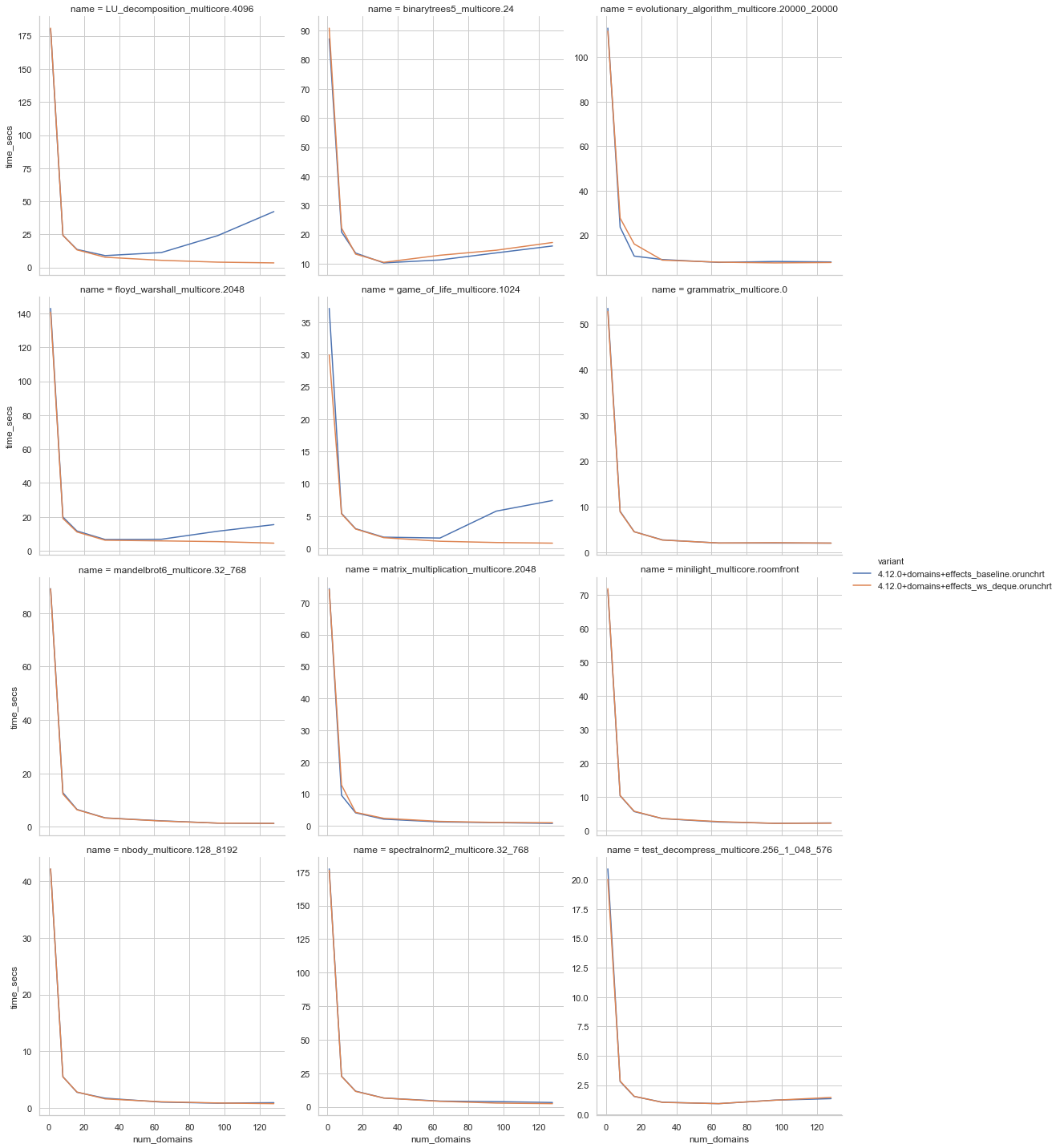
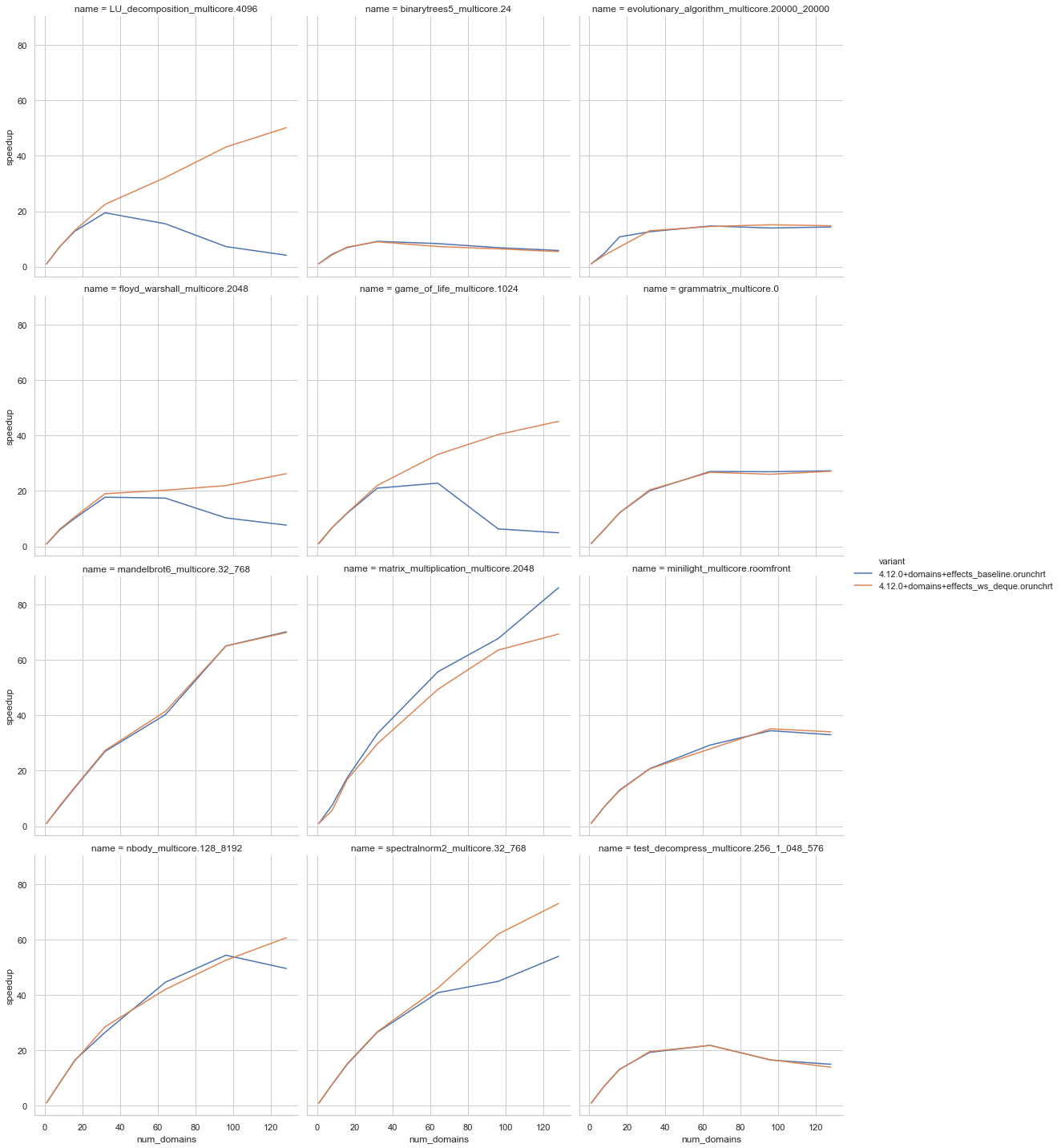
fb2a38) are encouraging:I wouldn't say the implementation is fully finished:
Atomicindirection.Some/Nonereturn from the deque to use exceptions.LU_decompositionandgame_of_lifestand out), it would be good to understand thematrix_multiplicationregression and take a look at thebinarytrees5where the deques might be a bit slower.The CL deque implementation was built on the queue in lockfree but I would recommend looking at the C code in Correct and efficient work-stealing for weak memory models