Compaction #12193
Compaction #12193
Conversation
|
Why does the RSS grow without bound when compaction isn't on? I don't expect it to shrink, but we're still collecting; why isn't each new iteration re-using the blocks collected by the previous iteration? |
That is curious. I think it's an artifact of the duration of the test. I'll set some longer runs going and see if it happens over a long period of time. |
|
I've marked myself as a reviewer, but I suspect that it may be a few weeks before I get through my current reviewing backlog. @NickBarnes would you be able to review this code? It is in your area of expertise. |
|
High-level comment: the majority of new code added now is in |
The main reason it's in |
Ok to keep the functionality in |
|
@NickBarnes so I ran that allocation test for longer and the results are pretty suspicious. Will investigate next week: |
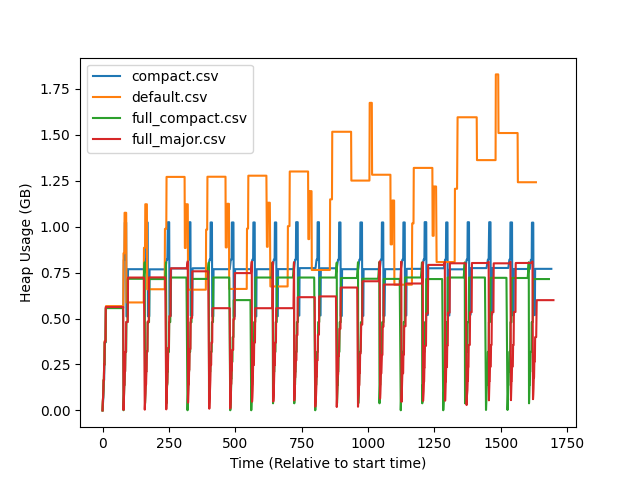
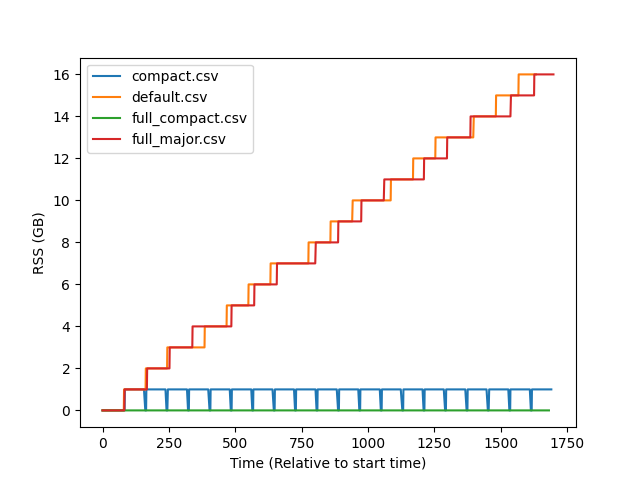
|
Your test program is basically a loop that allocates a lot of working memory on each iteration ( So the live memory throughout the program should be bounded as long as the GC does enough collection work (in particular in the versions that explicitly ask for a full GC after each iteration), and this is what we observe. (Well, maybe the "default" version actually has higher and higher peaks, this is hard to tell from the current data.) On the other hand, the RSS depends on our ability to return unused memory back to the OS, and what we observe is that the versions without compaction never do that. Is this the part that you find surprising? (I don't remember if we are supposed to return pools something when there are completely empty, which should be the case here after a full major cycle, or if we don't even try that.) (One aspect that is a bit strange is that the full_compact line in the RSS plot reads as if full_compact was always at exactly 0 bytes of RSS, which sounds impossible.) |
|
Very exciting! I'll need to re-run the benchmarks from the original discuss post now that compaction is also available. |
|
I have a naïve question. The lack of compaction had an "upside" which was the possibility of having non-movable ("pinned") blocks in memory (good for FFI). I remember some discussion about having a pinned analog of |
I have a potentially even more naïve follow up query/potential point. Sorry if this absolutely does not make sense. Lets say we have a bigarray. A bigarray is represented by a custom block. The first custom block is a pointer to some custom operations and then we have Now Now custom blocks are not scanned by the GC. So even if this custom block itself is "compacted" and moved, the place where the data of the bigarray is stored never changes and is "pinned". So in other words, for FFI, even in the face of a compacting GC as long as you are you using a bigarray your array data is already pinned. Is my understanding correct? |
Yes, this is correct. This (bigarrays) is what you must use for FFI whenever you need non-moving memory. However, it has an important cost in terms of API since you can no longer use |
|
@nojb wrote:
There is still hope! Values above 128 words (1K or so) are still not moved, as only smaller values are compacted. But for IO, you usually do need buffers larger than 1K to write into (they are usually 4K and page aligned), and so it should be compatible with this compactor. There's some relevant discussion in ocaml-multicore/eio#140. I'm very keen to have a go at eliminating Bigarray from our stack and seeing the benchmarking differences with just using |
You mean this? Lines 451 to 467 in 0a7c5fe |
|
When did they appear?! No blockers then! Let the Bigarray destruction begin! |
Some time ago in #1864 |
|
I checked through my notes, and I'd gotten two things confused:
|
There are ways to support pinning with this compaction algorithm, it's just that they make fragmentation a lot more likely or compaction much more expensive. As Anil pointed out, this is only for <1k byte allocations - it may be we decide to make it part of the FFI that these won't move or introduce a pin only for these size allocations (which would be a noop for now but would let us change that in the future). |
|
Are there updates on the suspicious results observed earlier? |
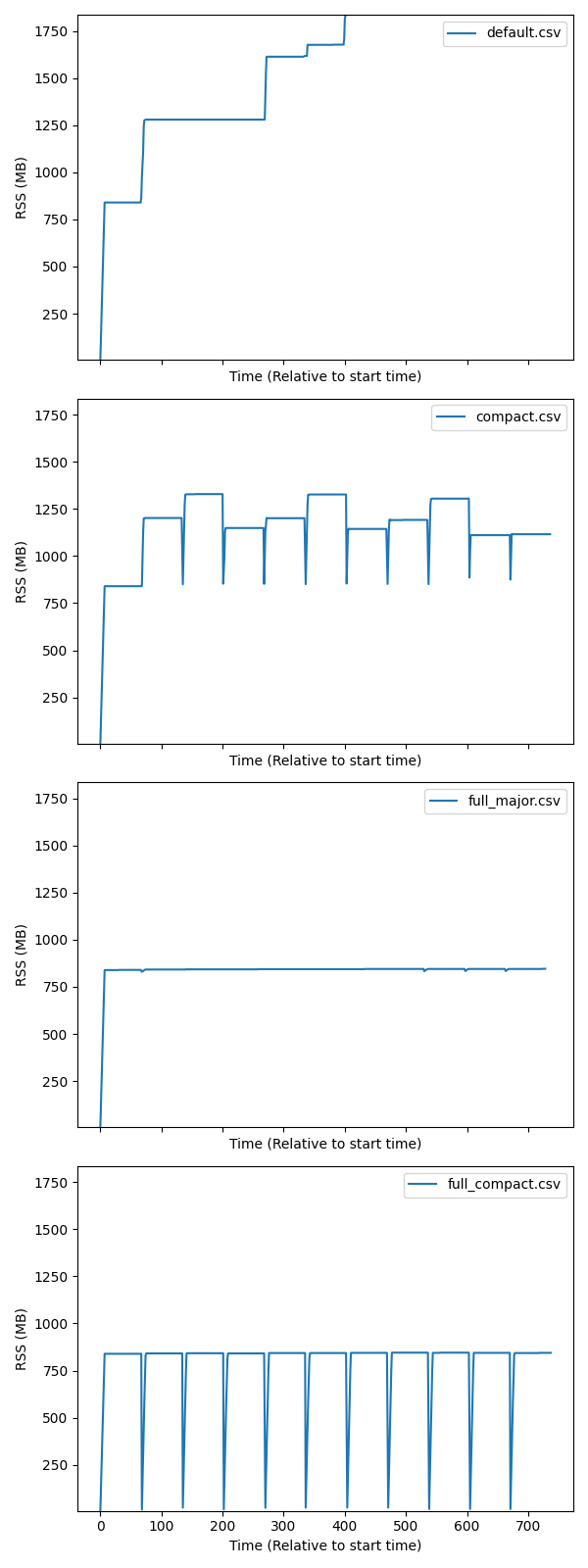
Yep, finally figured out what it was. Fixed in ff9860f . Without compaction we were not re-using (or releasing) empty pools. With that fixed the test now gives:
With just compact on its own, there's still a bunch of garbage yet to be swept which limits how much memory we can reclaim. Full major never really goes back down because there's no release to the OS. I should probably test what happens if we release back to the OS at the end of a full major. |
There was a problem hiding this comment.
I've split my review into two parts. This is the first, covering everything apart from the code between "Compaction start" and "Compaction end" in shared_heap.c. All this code looks semantically plausible except where marked - minor changes only.
The inconsistent code style is annoying, as commented: where do we place whitespace; where do we put braces; and can we please decide and then stick to it?
IIUC OCaml 4 releases memory only at the end of compaction. Are you planning to do this only as a test? |
…12193: Rewrote compact_update_ephe_list, renamed compact_update_field to compact_update_value, added compact_update_value_at, added POOL_FIRST_BLOCK, POOL_END, POOL_BLOCKS macros.
…r, free them immediately
Co-authored-by: Damien Doligez <damien.doligez@gmail.com>
proceed with compaction because we might be able to free up some memory.
354f011
to
af5d2ac
Compare
|
So being unable to get the macOS CI failure to reproduce I ran precheck against this branch and it found a segfault on the same test on alpine. After some trial and error I got that reproducing locally (it only happens when the test is restricted to a single core) and the bug is fixed in: af5d2ac (the extra barrier introduced was dropped in fca3650 ). macOS CI is green and that test runs cleanly on alpine now too. Essentially, if we pass an Should be all green now! |
|
I checked whether this tricky bugs occurs in the rest of the runtime code, and did not find any instance. |
|
As a last item, I used @artempyanykh 's allocation tester to allocate a large (
With Transparent Huge Pages enabled on my machine (kernel 6.2.0) this results in the kernel initially creating 512mb worth of (2mb) huge pages which then slowly grows with time. It hit about 9GB after 2 hours. I think a follow up item (suggested by @NickBarnes ) is we test doing an madvise MADV_COLLAPSE on contiguous ranges of pools at the end of compaction which would result in the merging being synchronous. If this works it could be an optional behaviour. I think we're ready to merge now. |
D'oh! |
|
One final paranoid run through precheck#911, but after that I'd say @sadiqj, @NickBarnes - are you both OK with the history being squashed? |
TLDR: PR reintroduces compaction for the pools in the GC's major heap (i.e small blocks < 128 words). Explicit only on calls to
Gc.compactfor now.This PR adds a parallel compactor for the shared pools forming part of the major heap. I've favoured simplicity where possible though the implementation should be reasonably performant. The
shared_heap.chas documentation describing the algorithm:https://github.com/ocaml/ocaml/blob/trunk/runtime/shared_heap.c#L960-L987
One thing to note is that the compactor works only on the current state of the major heap at the end of one major cycle. Due to the way the major GC works in OCaml 5.x , it may be several major cycles until unreachable blocks have been swept. This means that after a compaction there may still be unreachable blocks in the major heap. To ensure that only live data remains in the heap, users will need to do a full major followed by a compaction.
Items for discussion
Automatic compaction
I think it's probably worth waiting for a release before enabling automatic compaction but could be convinced otherwise.
Pool acquire/release
To enable actually releasing pools to the OS after a compaction I've removed the batching mechanism. It wasn't clear from benchmarks on https://discuss.ocaml.org/t/ocaml-5-gc-releasing-memory-back-to-the-os/11293/16 that batching was beneficial.
An alternative suggested by @stedolan is to use MADV_DONTNEED on Linux instead of unmapping, and potentially keep batching.
Benchmarks
Since there's no changes to the GC itself when compaction isn't forced, I've only included some benchmarks from a small allocator test (github.com/sadiqj/allocator-test) which cycles between creating a large heap and then throwing most of it away.
The graph shows four different runs of the test with different actions after throwing most of the data away: default is no action, a full major, a compact and a full major then compact.
For the reasons discussed earlier, full major then compaction results in much lower overall RSS.
Thanks
Thanks to @NickBarnes, @stedolan and @mshinwell for debugging help.
A ping for @damiendoligez and @kayceesrk for review. Thanks!