
Web scraping is simple. You can easily fetch many pages with CURL or any other old good client. However we don't believe it :)!
We thing that web scraping is complex if you do it commercially. Most of the times we see that, indeed people can extract pages with simple curl based client (or Floki + something), however they normally fail if it comes about clear deliverable.
We think that Crawling is hard when it comes to:
- Scalability - imagine you have SLA to deliver another million of items before the EOD
- Data quality - it's easy to get some pages, it's hard to extract the right data
- Javascript - most of the platforms would not even mention it :)
- Coverage - what if you need to get literally all pages/products, do you really plan to check it all manually using the command line?
We have created a platform which allows to manage jobs and to visualize items in the nice way. We believe it's important to see how your data looks! It's important to be able to filter it, analyzing every job and comparing jobs.
And finally it's important to be able to compare extracted data with the data on the target website.
We think that web scraping is a process! It involves development, debugging, QA and finally maintenance. And that's what we're trying to achieve with CrawlyUI project.
Live demo is available at: http://crawlyui.com/
You could run it locally using the following commands
docker-compose builddocker-compose up -d postgresdocker-compose run ui bash -c "/crawlyui/bin/ec eval \"CrawlyUI.ReleaseTasks.migrate\""docker-compose up ui worker
This should bring the Crawly UI, Crawly worker (with Crawly Jobs in example folder) and postgres database for you. Now you can access the server from localhost:80
-
Main page. Schedule jobs here!

-
All jobs page

-
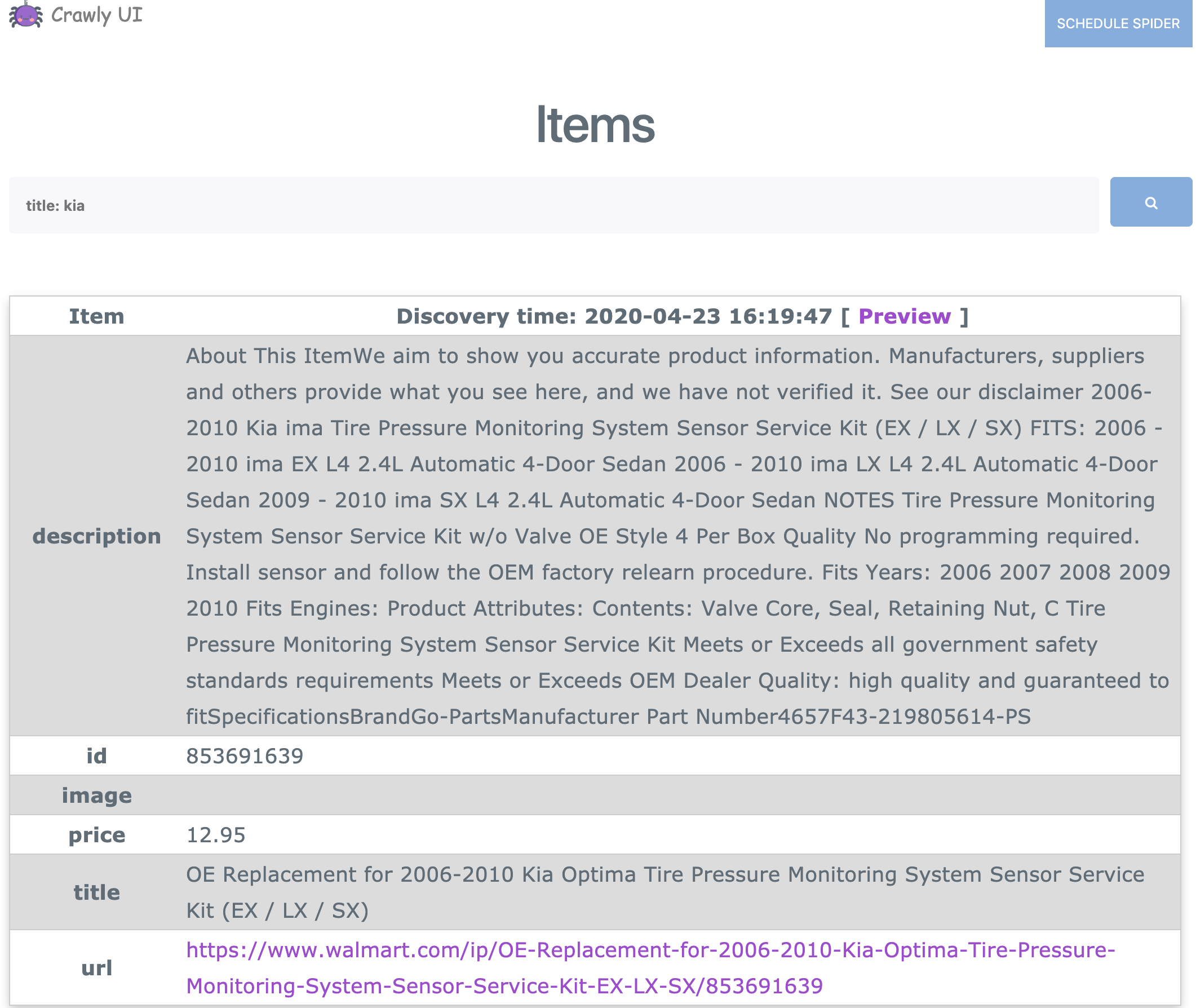
Items browser


-
Items preview





CrawlyUI is a phoenix application, which is responsible for working with Crawly nodes. All nodes are connected to CrawlyUI using the erlang distribution. CrawlyUI can operate as many nodes as you want (or as many as erlang distribution can handle ~100)
- Add SendToUI pipeline to the list of your item pipelines (before encoder pipelines)
{Crawly.Pipelines.Experimental.SendToUI, ui_node: :"<crawlyui-node-name>@127.0.0.1"}, example:
# config/config.exs
config :crawly,
pipelines: [
{Crawly.Pipelines.Validate, fields: [:id]},
{Crawly.Pipelines.DuplicatesFilter, item_id: :id},
{Crawly.Pipelines.Experimental.SendToUI, ui_node: :"ui@127.0.0.1"},
Crawly.Pipelines.JSONEncoder,
{Crawly.Pipelines.WriteToFile, folder: "/tmp", extension: "jl"}
]- Organize erlang cluster so Crawly nodes can find CrawlyUI node, in this case we use erlang-node-discovery application for this task, however any other alternative would also work. For setting up erlang-node-discovery:
- add erlang-node-discovery as dependencies:
# mix.exs
defp deps do
[
{:erlang_node_discovery, git: "https://github.com/oltarasenko/erlang-node-discovery"}
]
- add the following to the configuration:
# config/config.exs
config :erlang_node_discovery, hosts: ["127.0.0.1"], node_ports: [{<crawlyui-node-name>, 4000}]where <crawlyui-node-name> needs to match with the SendToUi pipeline (it would be {:ui, 4000}
to match with the example)
Start an iex session in your Crawly implementation directory with --cookie
(which should be same with your CrawlyUI session), you can also define a node name
with option --name and it will be your Crawly node name that shows up on the UI, example:
$ iex --name worker@worker.com --cookie 123 -S mixStart postgres with the command
$ docker-compose build
$ docker-compose up -d postgresStart an iex session in CrawlyUI directory with --name <crawlyui-node-name>@127.0.0.1
and --cookie that is the same with the crawly session, example:
$ iex --name ui@127.0.0.1 --cookie 123 -S mix phx.serverThe interface will be available on localhost:4000 for your tests.
If the crawly node does not show up on http://localhost:4000/schedule, try on your Crawly iex
session ping the CrawlyUI node with Node.ping/1, example:
iex (worker@worker.com) 1> Node.ping(:"ui@127.0.0.1")
> :pongIf you get :pong back, refresh the page and the crawly node will be there
If your item has URL field you will get a nice preview capabilities, with the help of iframe.
NOTE:
Iframes are blocked almost by every large website. However you can easily overcome it by using Ignore X-Frame headers browser extension.
- Make tests to have 80% tests coverage
- Get logs from Crawly
- Allow to stop given spiders
- Parametrize spider parameters
- Export items (CSV, JSON)
- Make better search (search query language like in Kibana)
- UI based spider generation