两年一度的ECCV2022终于在万众瞩目下召开啦,相信有不少小伙伴们对今年ECCV发布的新方向、新算法和新数据集十分感兴趣。今天小编从数据集的角度入手,给大家精选了ECCV2022发布的8个数据集,囊括了庞大的标注数据和新奇又有趣的任务,欢迎大家速速来围观!
本文还有一个超大福利:ECCV 2022数据集下载链接合辑。小编们呕心沥血地对ECCV2022的1600多篇接收文章进行了筛选,最终获取了107个数据集的下载链接,并按照任务类型进行了整理,小伙伴们快来看看有没有你们中意的数据集吧!
本文由两部分组成:
- ECCV2022精选数据集简介:包含了8个数据集的详细介绍。从任务类型和引用率的角度考虑,挑选了8个数据集进行简单的介绍(包括标注类型、应用场景、论文中的关键结果图等)。
- ECCV2022数据集合辑:包含107个数据集的下载链接。对107个数据集进行了粗粒度和细粒度的任务类型划分,提供了数据集的下载链接和相应的文章链接,并辅以简单说明。
该部分包括多个任务领域的8个数据集的详细介绍:
- HuMMan (4D人体感知和建模)
- OpenLane/Waymo (自动驾驶)
- PartImageNet (零部件分割)
- Sherlock (溯因推理)
- MovieCuts (视频剪辑类型识别)
- DexMV (机器人模仿学习)
- ViCo (视频生成-倾听者反馈)
4D人体感知和建模是视觉和图形领域的基本任务,具有多种应用。随着新传感器和算法的进步,对更通用数据集的需求越来越大。HuMMan[1]是一个大型多模态4D人体数据集,包含1000个人体对象、400k序列和60M帧。
HuMMan的特点在于: 1)多模态数据和注释,包括彩色图像、点云、关键点、SMPL参数和纹理网格; 2)传感器套件中包括主流的移动设备; 3)囊括了500个动作,涵盖了人体活动的基本动作; 4) 支持和评估多种任务,如动作识别、姿势估计、参数化人体恢复和纹理网格重建。

图1. HuMMan具有多种数据格式和注释形式:a)彩色图像,b)点云,c)关键点,d)SMPL参数,e)网格,f)纹理。每个序列还带有来自500个动作的动作标签注释。每个受试者都有两个额外的高分辨率扫描,对自然和衣着最少的身体进行扫描[1]
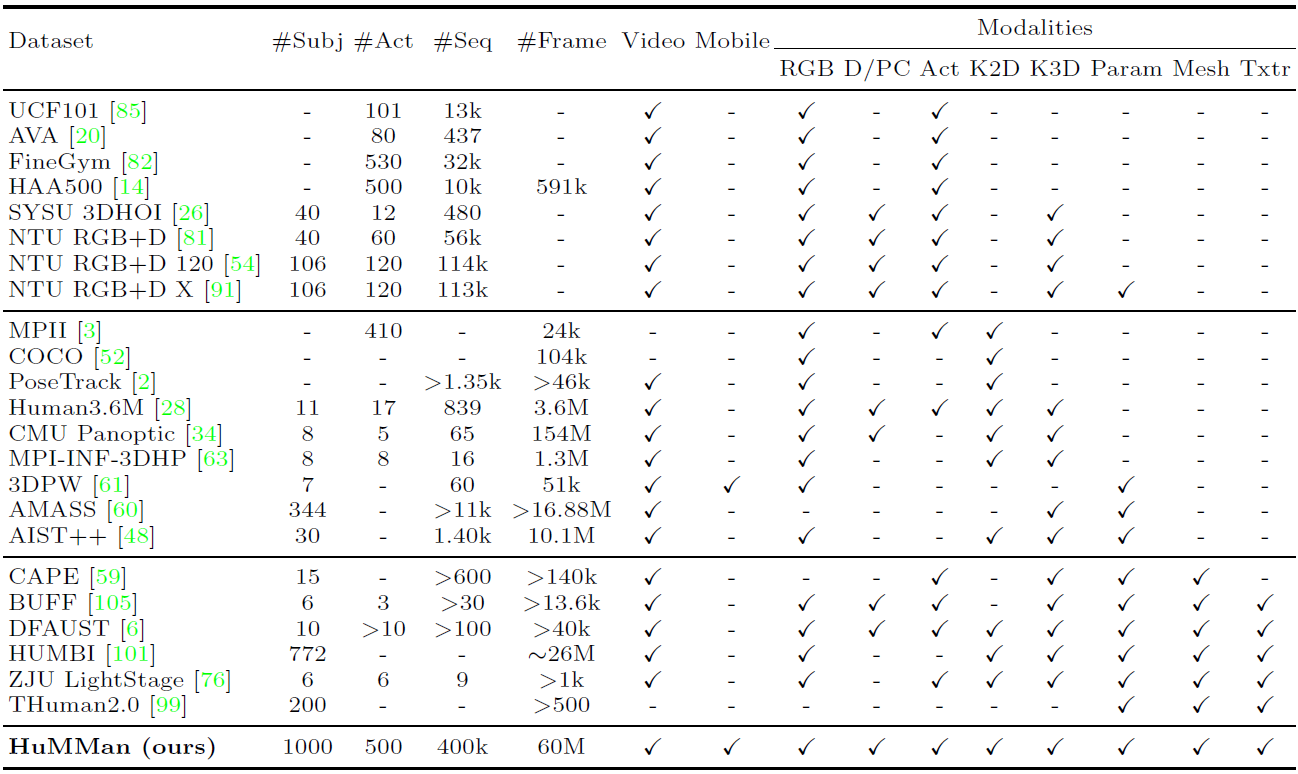
表1. HuMMan与已发布数据集的比较[1]
HuMMan在受试者数量(#Subj)、动作(#Act)、序列(#Seq)和帧(#Frame)方面具有竞争力。数据来源分为:视频,即连续数据,不限于RGB序列;移动,即传感器套件中的移动设备。
此外,HuMMan具有多种模式标注用于支持多种任务,包括:RGB,即三波段图像;D/PC,即深度图像或点云,仅考虑从深度传感器采集的真实点云;Act,即动作标签;K2D,即二维关键点;K3D,即3D关键点;Param,即统计模型(如SMPL)参数;Mesh,即网格,Txtr,即纹理。
HuMMan的大量实验表明,在多个诸如细粒度动作识别、动态人体网格重建、基于点云的参数化人体恢复和跨设备域间隙等等研究领域,仍存在较多挑战,具有很大的研究空间。
数据集链接:https://caizhongang.github.io/projects/HuMMan/
为方便AI研究员们,OpenDataLab 已收录HuMMan 数据集资源,点击数据集名称可免费、高速下载。
OpenLane[2]是迄今为止第一个真实世界3D车道数据集,也是目前为止最大规模的,拥有200K帧和880K条经过仔细注释的车道。该数据集从公众感知数据集Waymo Open dataset[3]收集有价值的内容,并为1000个segment提供车道和最近路径对象(closest-in-path object, CIPO)注释。
车道注释包括(具体可见:Lane Anno Criterion):
- 车道形状。每个2D/3D车道都显示为一组2D/3D点。
- 车道类别。每条车道都有一个类别,例如双黄线或路缘。
- Lane属性。有些车道具有右车道、左车道等特性。
- 车道跟踪ID。除路缘外,每条车道都有唯一的ID。
- 停车线和路缘石。
CIPO/场景注释包括(具体可见:Lane Anno Criterion)
- 二维边界框,其类别表示对象的重要性级别。
- 场景标记。它描述了在哪个场景中收集此帧。
- 天气标签。它描述了这个框架是在什么天气下收集的。
- 小时标签。它会注释收集此帧的时间。
图2. OpenLane的标注示例[2]
Waymo Open dataset[3]也是ECCV 2022接收文章中公开的数据集,提供了激光雷达和相机这两种传感器上的独立标注,标注类型包括:车辆和行人的3D Lidar检测和分割、2D相机检测和分割(包括图片和视频)、2D-to-3D correspondence,以及人体关键点标注等。


图3. Waymo的标注示例(https://waymo.com/open/data/perception/)
OpenLane数据集链接:https://github.com/OpenPerceptionX/OpenLane Waymo数据集链接:https://waymo.com/open/
为方便AI研究员们, OpenDataLab 已收录OpenLane数据集资源,点击数据集名称可免费、高速下载。
PartImageNet[4]是一个具有零部件分段注释的大型高质量数据集。它由ImageNet[5]中的158个类组成,大约有24000个图像。
这些类别被分为11个super-categories,零件分割是根据super-categories设计的,如下所示(类别名称后面括号中的数字表示该super-categories下包含的子类别总数):
| Category | Annotated Parts |
|---|---|
| Quadruped (46) | Head, Body, Foot, Tail |
| Biped (17) | Head, Body, Hand, Foot, Tail |
| Fish (10) | Head, Body, Fin, Tail |
| Bird (14) | Head, Body, Wing, Foot, Tail |
| Snake (15) | Head, Body |
| Reptile (20) | Head, Body, Foot, Tail |
| Car (23) | Body, Tier, Side Mirror |
| Bicycle (6) | Head, Body, Seat, Tier |
| Boat (4) | Body, Sail |
| Aeroplane (2) | Head, Body, Wing, Engine, Tail |
| Bottle (5) | Body, Mouth |
PartImageNet在众多研究领域具有广泛的潜力,包括零件发现、少样本学习和语义分割中的应用等。以下是该数据集中一些测试图像在不同模型下获得的效果:
图4. PartImageNet标注示例和模型测试结果示例(来源为数据集官网)
数据集链接:https://github.com/TACJu/PartImageNet
Sherlock[6]是一个结合图片实例级框标注和文字标注的的数据集,任务的目标是给定图像中的某部分内容,以及一段指引性的线索,让机器去推断这部分内容包含的一些信息或者正在发生的事件,即溯因推理。
语料库中包括103K幅图像中的363K个推理。每个图像包含多个边界框,每个边界框中包含文字线索和推理文本标注,总共收集了363K(线索、推理)对,形成了第一个此类外展性视觉推理数据集。
下面给出了其中一个性能最好的模型的预测示例,以及人类注释:
图5. Sherlock数据集标注示例和模型预测示例(来源为数据集官网)
数据集链接:http://visualabduction.com/
MovieCuts[7]是一个视频及剪辑标注的大型数据集,包含173967个视频剪辑,这些视频剪辑被标记q为10种不同的剪辑类型。数据集中的每个样本都由两个视频片段(将一段视频从中剪辑拆分开)及其附带的音频组成。
该数据集主要针对一种新的任务:视频剪辑类型识别。视频剪辑指的是将两段视频拼接在一起,并且拼接之后的视频看起来具有连续性,不会太突兀。视频剪辑类型识别则是要识别出两段视频是通过何种方式拼接在一起的。
图6. MovieCuts数据集中的剪辑类型[7]:剪辑类型分为两个大类:视觉驱动(第一行)和视听驱动(第二行)
该文章对一系列视听方法进行了基准测试,包括一些处理问题的多模式和多标签性质的方法。最佳模型仅达到45.7%mAP,这表明实现高精度的剪辑类型识别是一个开放且有挑战性的问题。
数据集链接:https://www.alejandropardo.net/publication/moviecuts/
虽然在计算机视觉中理解手-物体相互作用方面取得了重大进展,但机器人执行复杂的灵巧操作仍然是一项非常具有挑战性的任务。DexMV[8]就是为了人体视频中灵巧操作的模仿学习任务而创建的数据集,用于改善机器人执行复杂的灵巧操作。
DexMV包含了一个平台和pipline,包括: (a)一个多指机器人手复杂灵巧操作任务的仿真系统; (b)一个计算机视觉系统,用于记录执行相同任务的人手的大规模演示。并从视频中进行3D手和物体的姿态估计,最后将人体运动转换为机器人演示。
文章应用并比较了多种模拟学习算法和演示。结果表明,演示确实可以大幅度改进机器人学习,并解决强化学习单独无法解决的复杂任务。
图7.DexMV平台和pipline[8]: 平台由计算机视觉系统(黄色)、仿真模拟系统(蓝色)和演示翻译模块(绿色)组成。计算机视觉系统收集人类操纵视频。在仿真模拟系统中为机器人手设计了相同的任务。应用视频中的3D手对象姿势估计,然后通过演示翻译模块生成机器人演示,用于模拟学习
数据集链接:https://yzqin.github.io/dexmv/
ViCo[9]数据集主要是用于上下文理解的视觉面部表情生成,应用场景为在面对面交谈中生成听众的反应反馈(例如点头、微笑)。ViCo共涉及92种身份(67位发言者和76位听众)和483个视频音频片段,采用配对“说-听”模式,听众(listener)根据说话者(speaker)的语音以及视频实时生成态度不同的反应反馈(积极、中立、消极)。
与传统的语音到手势或说话头部生成不同,倾听者头部生成利用来自说话者的音频和视频信号作为输入,并实时提供非语言的反馈(例如头部运动、面部表情)。该数据集支持广泛的应用,例如人与人的交互、视频与视频的转换、跨模式理解和生成。
图8.真实标注和模型生成的听众反馈(来源为数据集官网)
数据集由三部分组成:
- videos/*.mp4: 所有的视频(不包含音频)
- audios/*.wav: 所有的音频
- *.csv: 返回的元数据(具体字段见表3)
| Name | Type | Description |
|---|---|---|
| attitude | str | Attitude of video, possible values: [positive, negative, neutral] |
| audio | str | Audio filename, can be located by /audios/{audio}.wav |
| listener | str | Listener video filename, can be located by /videos/{listener}.mp4 |
| speaker | str | Speaker video filename, can be located by /videos/{speaker}.mp4 |
| listener_id | int | ID of listener, value ranges in [0, 91] |
| speaker_id | int | ID of speaker, value ranges in [0, 91] |
| data_split | str | The data split of current record, possible values: [train, test, ood] |
表3.元数据包含的字段(来源为数据集官网)
数据集链接:https://project.mhzhou.com/vico
根据本次ECCV2022的107个数据集涉及到的任务类型,从几个大方向对数据集进行了粗分类:
- 分类、检测、跟踪、分割、关键点和识别(40个)
- 图像处理和生成(21个)
- 多模态(20个)
- 其他(26个)
以下表格分别列出了各个数据集的名称、链接以及对应文章的名字和链接,另外还包含了细粒度任务类型和数据集的简介,需要的朋友自取~ OpenDataLab后续也将陆续上线这些数据集的国内高速下载链接和详细介绍,欢迎大家持续关注!如果有感兴趣的内容,也欢迎联系我们,加入社区共同交流(小助手微信号:opendatalab_yunying)
| Paper Title | URL | 数据集名称 | 数据集链接 | 任务类型 | 数据集简介(包括使用场景、标注类型等) |
|---|---|---|---|---|---|
| TO-Scene: A Large-scale Dataset for Understanding 3D Tabletop Scenes | https://arxiv.org/pdf/2203.09440 | TO-Scene | https://github.com/GAP-LAB-CUHK-SZ/TO-Scene | 语义分割和物体检测 | 3D数据集,主要是桌上场景。 |
| PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark | https://arxiv.org/pdf/2203.11089 | OpenLane | https://github.com/OpenPerceptionX/OpenLane | 物体检测(车道检测) | 真实场景的车道3D数据集,用于车道检测。 |
| Toward Understanding WordArt: Corner-Guided Transformer for Scene Text Recognition | https://arxiv.org/pdf/2208.00438 | - | https://github.com/xdxie/WordArt | 场景文本识别 | |
| OPD: Single-view 3D Openable Part Detection | https://arxiv.org/pdf/2203.16421 | 1. OPDSynth 2. OPDReal |
https://3dlg-hcvc.github.io/OPD/ | 对象移动预测 | 包含了两个3D数据集,其中OPDSynth是合成的数据 , OPDReal是真实对象。 |
| ROBIN: A Benchmark for Robustness to Individual Nuisances in Real-World Out-of-Distribution Shifts | https://arxiv.org/pdf/2111.14341 | OOD-CV | http://www.ood-cv.org/ | 图片分类、目标识别、3D姿态估计 | 基准数据集,包含10个目标类别,涉及姿势、形状、纹理、背景和天气条件。 |
| A Dense Material Segmentation Dataset for Indoor and Outdoor Scene Parsing | https://arxiv.org/pdf/2207.10614 | DMS | https://github.com/apple/ml-dms-dataset | 语义分割 | 稠密材料分割数据集(DMS)由44000个RGB图像的300万个材料类别(金属、木材、玻璃等)多边形标签组成。 |
| Pose for Everything: Towards Category-Agnostic Pose Estimation | https://arxiv.org/pdf/2207.10387 | MP-100 | https://github.com/luminxu/Pose-for-Everything | 类别不确定性姿态估计(CAPE) | 数据集的媒体文件来自于已有的数据集existing datasets (COCO, 300W, AFLW, OneHand10K, DeepFashion, AP-10K, MacaquePose, Vinegar Fly, Desert Locust, CUB-200, CarFusion, AnimalWeb, Keypoint-5),标注文件是新生成的,是一个2D的姿态估计数据集,类别是不确定的。 |
| Benchmarking Omni-Vision Representation through the Lens of Visual Realms | https://arxiv.org/pdf/2207.07106 | OmniBenchmark | https://github.com/ZhangYuanhan-AI/OmniBenchmark | 图像分类 | 全领域数据集,包括21个领域级数据集,包括7372个类别和1074346个图像,且没有语义重叠。这些数据集可以全面、高效地覆盖大多数视觉领域。 |
| Online Segmentation of LiDAR Sequences: Dataset and Algorithm | https://arxiv.org/pdf/2206.08194 | HelixNet | https://github.com/romainloiseau/HelixNet | 语义分割 | 大规模开放访问的LiDAR数据集,用于评估实时语义分割算法。与其他大规模数据集不同,HelixNet包含关于传感器旋转和位置以及点释放时间的细粒度数据。 |
| 3D Compositional Zero-shot Learning with DeCompositional Consensus | https://arxiv.org/pdf/2111.14673 | Compositional PartNet | - | 3D部件分割,零样本学习 | - |
| Video Mask Transfiner for High-Quality Video Instance Segmentation | https://arxiv.org/pdf/2207.14012 | HQ-YTVIS | https://www.vis.xyz/data/hqvis/ | 视频实例分割 | - |
| CODA: A Real-World Road Corner Case Dataset for Object Detection in Autonomous Driving | https://arxiv.org/pdf/2203.07724 | CODA | https://coda-dataset.github.io/ | (自动驾驶场景下的)目标检测 | - |
| Unitail: Detecting, Reading, and Matching in Retail Scene | https://arxiv.org/pdf/2204.00298 | United Retail Datasets(Unitail) | https://unitedretail.github.io/ | 目标检测、文本检测、文本识别、图像匹配 | - |
| Waymo Open Dataset: Panoramic Video Panoptic Segmentation | https://arxiv.org/pdf/2206.07704 | Waymo | https://waymo.com/open | 全景分割 | - |
| Domain Randomization-Enhanced Depth Simulation and Restoration for Perceiving and Grasping Specular and Transparent Objects | https://arxiv.org/pdf/2208.03792 | STD | https://github.com/PKU-EPIC/DREDS | 深度估计 | - |
| COO: Comic Onomatopoeia Dataset for Recognizing Arbitrary or Truncated Texts | https://arxiv.org/pdf/2207.04675 | COO | https://github.com/ku21fan/COO-Comic-Onomatopoeia | 不规则文本识别 | - |
| MOTCOM: The Multi-Object Tracking Dataset Complexity Metric | https://arxiv.org/pdf/2207.10031 | MOTCOM | https://vap.aau.dk/motcom | 多目标跟踪 | - |
| GIPSO: Geometrically Informed Propagation for Online Adaptation in 3D LiDAR Segmentation | https://arxiv.org/pdf/2207.09763 | Synth4D | https://github.com/saltoricristiano/gipso-sfouda | 3D语义分割 | - |
| Fine-grained Egocentric Hand-Object Segmentation: Dataset, Model, and Applications | https://arxiv.org/pdf/2208.03826 | EgoHOS | https://github.com/owenzlz/EgoHOS | 语义分割(手-目标交互) | - |
| Few-Shot Video Object Detection | https://arxiv.org/pdf/2104.14805 | FSVOD-500 | https://github.com/fanq15/FewX | few-shot 视频目标检测 | - |
| Gen6D: Generalizable Model-Free 6-DoF Object Pose Estimation from RGB Images | https://arxiv.org/pdf/2204.10776 | GenMOP | Gen6D - OneDrive (sharepoint.com) | 姿态估计 | "应用场景为:六自由度物体姿态估计 数据集中提供了多个场景/光照条件下的视频片段以及对应的对象姿态标注" |
| PartImageNet: A Large, High-Quality Dataset of Parts | https://arxiv.org/pdf/2112.00933 | PartImageNet | PartImageNet - Google 云端硬盘 | 语义分割,图像分类 | 提供了多个类别的图像,同时提供了每张图像中的目标的身体的各个部分的分割标注 |
| Multi-Domain Multi-Definition Landmark Localization for Small Datasets | https://arxiv.org/pdf/2203.10358 | PARE | GitHub - davidcferman/pareidolia-landmarks | 人脸关键点检测 | 小数据集虚拟人脸关键点检测 内容包含人脸图像,box2d,关键点 |
| UnrealEgo: A New Dataset for Robust Egocentric 3D Human Motion Capture | https://arxiv.org/pdf/2208.01633 | UnrealEgo | https://4dqv.mpi-inf.mpg.de/UnrealEgo/ | 姿态估计 | 自我中心的三维人体姿态估计 |
| Neural-Sim: Learning to Generate Training Data with NeRF | https://arxiv.org/pdf/2207.11368 | YCB-in-the-Wild | https://github.com/gyhandy/Neural-Sim-NeRF | 目标检测 | 该数据集由大约1300个测试图像组成,每个对象有超过200个图像。所有的图像都是使用智能手机相机在一个常见的室内环境中拍摄的:客厅、厨房、卧室和浴室,在自然姿势和照明下。 |
| Invariant Feature Learning for Generalized Long-Tailed Classification | https://arxiv.org/pdf/2207.09504 | 1.ImageNet-GLT 2.MSCOCO-GLT |
https://github.com/KaihuaTang/Generalized-Long-Tailed-Benchmarks.pytorch | 图像分类(广义长尾分类(GLT)) | 从原有的数据集重新构建的适合长尾分类的数据集 |
| Quasi-Balanced Self-Training on Noise-Aware Synthesis of Object Point Clouds for Closing Domain Gap | https://arxiv.org/pdf/2203.03833 | SpeckleNet | https://drive.google.com/drive/folders/1wcERGIKvJRlCbSndM_DCSfcvjiGvv_5g | 对象点云的语义分析 | 使用 Mesh2Point 管道扫描ModelNet并生成新的数据集SpeckleNet |
| Facial Depth and Normal Estimation using Single Dual-Pixel Camera | https://arxiv.org/pdf/2111.12928 | - | https://github.com/MinJunKang/DualPixelFace#dataset | 人脸识别 | 用多相机结构光系统收集了101个人的超过135K的DP面部数据 |
| Few-shot Object Counting and Detection | https://arxiv.org/pdf/2207.10988 | 1. FSCD-147 2. FSCD-LVIS |
https://drive.google.com/drive/folders/14qzZaV4S8EBUj3yEkgrDQC7iErHxSPjl?usp=sharing 或 https://drive.google.com/drive/folders/1tlHZIg6X3jp6qARTxKh0kMsNvuIQop9P?usp=sharing | 小样本目标计数和检测 | |
| Salient Object Detection for Point Clouds | https://arxiv.org/pdf/2207.11889 | PCSOD | https://git.openi.org.cn/OpenDatasets/PCSOD-Dataset/datasets | 点云显著性检测 | |
| ClearPose: Large-scale Transparent Object Dataset and Benchmark | https://arxiv.org/pdf/2203.03890 | ClearPose | https://drive.google.com/drive/folders/1Cp2cwwQmntE0aUkmHOLKIlG4Jiz9PQH8 | 深度补全,对象姿态估计 | - |
| 3D Interacting Hand Pose Estimation by Hand De-occlusion and Removal | https://arxiv.org/pdf/2207.11061 | Amodal InterHand Dataset | https://connecthkuhk-my.sharepoint.com/personal/js20_connect_hku_hk/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Fjs20%5Fconnect%5Fhku%5Fhk%2FDocuments%2FAIH%5Fdataset&ga=1 | 3D 交互手部姿势估计 | - |
| D2-TPred: Discontinuous Dependency for Trajectory Prediction under Traffic Lights | https://arxiv.org/pdf/2207.10398 | VTP-TL | https://github.com/VTP-TL/D2-TPred | 车辆轨迹预测(vehicle trajectory prediction) | 用于自动驾驶场景,类似于waymo,标注包括车辆的轨迹、标注框,以及信号灯的位置、状态、持续时长等 |
| On Label Granularity and Object Localization | https://arxiv.org/pdf/2207.10225 | iNatLoc500 | - | 弱监督目标定位(weakly-supervised object localization) | iNatLoc500包含500个类别,针对于弱监督目标定位提出。和现有数据集相比,具有数据量大,多样性强的特点。 |
| VizWiz-FewShot: Locating Objects in Images Taken by People With Visual Impairments | https://arxiv.org/pdf/2207.11810 | - | https://vizwiz.org | 少样本目标定位(few-shot localization) | 这个新数据集针对于少样本目标定位提出,包含了100个类别,同时还有实例分割的标注,同时在分割中还要求定位目标中的空洞 |
| ESS: Learning Event-based Semantic Segmentation from Still Images | https://arxiv.org/pdf/2203.10016 | DSEC-Semantic | https://dsec.ifi.uzh.ch/dsec-semantic/ | 语义分割 | DSEC-Semantic是一个基于事件的(event-based)实例分割数据集,文章提出在常规的实例分割数据集上使用了N/A监督域泛化的迁移方法,将语义分割标注转换成N/A标注的事件类型 |
| Towards Generic 3D Tracking in RGBD Videos: Benchmark and Baseline | https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136820108.pdf | Track-it-in-3D | https://github.com/yjybuaa/Track-it-in-3D | 3D物体跟踪 | 通用3D对象跟踪的标准基准数据集,其中包含300个RGBD视频序列,带有密集的3D注释和相应的评估工具。 |
| Tackling Long-Tailed Category Distribution Under Domain Shifts | https://arxiv.org/pdf/2207.10150 | 1. AWA2-LTS 2. ImageNet-LTS |
https://github.com/guxiao0822/LT-DS/tree/main/dataset | 图像分类中的长尾分布 | 从原始的 AWA2 和 ImageNet转换而来。 |
| SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation | https://arxiv.org/pdf/2207.14315 | VisA | http://github.com/amazon-research/spot-diff | 视觉异常检测 | - |
| Contextual Text Block Detection towards Scene Text Understanding | https://arxiv.org/pdf/2207.12955 | 1.SCUT-CTW-Context 2.ReCTS-Context |
https://drive.google.com/drive/folders/1jmtSOHgufN-m-OT28zoxVvRYDqegNSXv | 上下文文本检测 | 文本检测数据集 |
| Paper Title | URL | 数据集名称 | 数据集链接 | 任务类型 | 数据集简介(包括使用场景、标注类型等) |
|---|---|---|---|---|---|
| Perceptual Artifacts Localization for Inpainting | https://arxiv.org/pdf/2208.03357 | PAL4Inpaint | https://github.com/owenzlz/PAL4Inpaint | 图像修复 | - |
| Fine-Grained Scene Graph Generation with Data Transfer | https://arxiv.org/pdf/2203.11654 | - | https://github.com/waxnkw/IETrans-SGG.pytorch/blob/master/DATASET.md | 场景图生成(SGG) | - |
| Event-Based Fusion for Motion Deblurring with Cross-modal Attention | https://arxiv.org/pdf/2112.00167 | REBlur | - | 图像去模糊 | 真实事件模糊数据集,该数据集由照明控制光学实验室中的事件相机捕获。 |
| RealFlow: EM-based Realistic Optical Flow Datasets Generation from Videos | https://arxiv.org/pdf/2207.11075 | - | https://github.com/megvii-research/RealFlow | 图像和标签生成 | 从视频中生成的图片数据集 |
| CelebV-HQ: A Large-Scale Video Facial Attributes Dataset | https://arxiv.org/pdf/2207.12393 | CelebV-HQ | https://celebv-hq.github.io/ | (视频)人脸生成,(视频)人脸编辑 | - |
| Highly Accurate Dichotomous Image Segmentation | https://arxiv.org/pdf/2203.03041 | DIS5K | https://xuebinqin.github.io/dis/index.html | "二分式图像分割~dichotomous image segmentation 含义是将图像的前景中的显著物体和背景分割开来,分割图中只区分前景和背景,所以称为二分(dichotomous )" | - |
| LEDNet: Joint Low-light Enhancement and Deblurring in the Dark | https://arxiv.org/pdf/2202.03373 | LOL-Blur | https://shangchenzhou.com/projects/LEDNet/ | 图像低光增强和去模糊 | |
| Detecting and Recovering Sequential DeepFake Manipulation | https://arxiv.org/pdf/2207.02204 | Seq-Deepfake | https://rshaojimmy.github.io/Projects/SeqDeepFake | "任务类型:Detecting Sequential DeepFake Manipulation 含义:检测人脸伪造的一系列操作。一张原始人脸图经过多步伪造可以生成一张新的人脸图,而这个任务是要输入生成的人脸图,检测出其是由那几步伪造操作生成的。" | - |
| Not Just Streaks: Towards Ground Truth for Single Image Deraining | https://arxiv.org/pdf/2206.10779 | GT-RAIN | https://visual.ee.ucla.edu/gt_rain.htm/ | 图像去雨 | - |
| Housekeep: Tidying Virtual Households using Commonsense Reasoning | https://arxiv.org/pdf/2205.10712 | Housekeep | https://yashkant.github.io/housekeep/ | 室内三维重建 | - |
| Transform your Smartphone into a DSLR Camera: Learning the ISP in the Wild | https://arxiv.org/pdf/2203.10636 | ISPW | - | 图像处理(图像增强) | - |
| A Real World Dataset for Multi-view 3D Reconstruction | https://arxiv.org/pdf/2203.11397 | A Real World Dataset for Multi-view 3D Reconstruction | http://www.ocrtoc.org/#/3D-Reconstruction | 3D重建 | "桌面物体3D重建, 标注包含:对象的3D模型、RGB图像、深度图" |
| REALY: Rethinking the Evaluation of 3D Face Reconstruction | https://arxiv.org/pdf/2203.09729 | REALY | https://www.realy3dface.com/ | 3D人脸重建 | "单视图3D人脸重建 标注包含100个人的高清人脸扫描网格与对应的低分辨率扫描网格" |
| Capturing, Reconstructing, and Simulating: the UrbanScene3D Dataset | https://arxiv.org/pdf/2107.04286 | UrbanScene3D | UrbanScene3D-Dataset - Google 云端硬盘 | 场景重建 "数据集用于城市场景感知与重建, 包含了128k张高分辨率图像,以及高精度的LiDAR扫描结果" | |
| StyleGAN-Human: A Data-Centric Odyssey of Human Generation | https://arxiv.org/pdf/2204.11823 | Stylish-Humans-HQ Dataset(SHHQ) | StyleGAN-Human: A Data-Centric Odyssey of Human Generation | 人体图像生成 | 数据集中收集了230K的高清人体图象 |
| D2HNet: Joint Denoising and Deblurring with Hierarchical Network for Robust Night Image Restoration | https://arxiv.org/pdf/2207.03294 | D2-Dataset | D2-Dataset-release - OneDrive | 图像增强 | 包含了6853组的高清图像以及其相应的各种程度的模糊图像 |
| Towards Efficient and Scale-Robust Ultra-High-Definition Image Demoiréing | https://arxiv.org/pdf/2207.09935 | UHDM | https://xinyu-andy.github.io/uhdm-page/ | 图像增强 | 探索超高清图像的莫尔条纹去除。提出了第一个超高清 demoiréing 数据集 (UHDM),其中包含 5,000 个真实世界的 4K 分辨率图像对 |
| NeRF for Outdoor Scene Relighting | https://arxiv.org/pdf/2112.05140 | NeRF-OSR Dataset | https://nextcloud.mpi-klsb.mpg.de/index.php/s/mGXYKpD8raQ8nMk?path=%2FData | 户外场景编辑~Photorealistic editing of outdoor scenes | 通过照片进行场景重建 |
| Towards Racially Unbiased Skin Tone Estimation via Scene Disambiguation | https://arxiv.org/pdf/2205.03962 | FAIR | https://trust.is.tue.mpg.de/ | 虚拟面部头像~Virtual facial avatars | - |
| D2C-SR: A Divergence to Convergence Approach for Real-World Image Super-Resolution | https://arxiv.org/pdf/2103.14373 | D2CRealSR | https://drive.google.com/file/d/1ZTjB6q94ge2h9ixf1osEGXXnfuLTYVzO/view | 真实场景超分辨率~real-world image resolution | |
| Realistic Blur Synthesis for Learning Image Deblurring | https://arxiv.org/pdf/2202.08771 | RSBlur | https://drive.google.com/drive/folders/1sS8_qXvF4KstJtyYN1DDHsqKke8qwgnT | 图像去模糊 | - |
| Paper Title | URL | 数据集名称 | 数据集链接 | 任务类型 | 数据集简介(包括使用场景、标注类型等) |
|---|---|---|---|---|---|
| HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling | https://arxiv.org/pdf/2204.13686 | HuMMan | https://caizhongang.github.io/projects/HuMMan/ | 动作识别、姿势估计、参数化人体恢复和纹理网格重建 | 是一个人类姿态的4D数据集,包括了图像、点云、关键点、SMPL参数和纹理网络。 |
| The Abduction of Sherlock Holmes: A Dataset for Visual Abductive Reasoning | https://arxiv.org/pdf/2202.04800 | Sherlock | http://visualabduction.com/ | 视觉推理 | 包含103K个图像的注释语料库,用于测试机器在文字图像内容之外进行诱因推理的能力。总共收集了363K(线索、推理)对,形成了第一个此类外展性视觉推理数据集。 |
| BEAT: A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis | https://arxiv.org/pdf/2203.05297 | BEAT | https://pantomatrix.github.io/BEAT/#download | 可控手势合成、跨模态分析和情感手势识别 | 包含76小时的高质量多模态数据,这些数据是从30个说话者用八种不同的情感和四种不同的语言交谈中获取的,具有3200万帧级情感和语义相关注释 |
| Making the Most of Text Semantics to Improve Biomedical Vision-Language Processing | https://arxiv.org/pdf/2204.09817 | MS-CXR | https://aka.ms/ms-cxr | 多模态 | - |
| Contrastive Vision-Language Pre-training with Limited Resources | https://arxiv.org/pdf/2112.09331 | - | - | 多模态预训练 包含了100M从互联网上爬取的图像-文本对 | |
| A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge | https://arxiv.org/pdf/2206.01718 | A-OKVQA | https://allenai.org/project/a-okvqa/home | 多模态:视觉问答(VQA) A-OKVQA是一种新的基于知识的视觉问答基准。 | A -OKVQA 是OK-VQA的升级后继者,包含一组多样化的 25K 问题,需要广泛的常识和世界知识才能回答 |
| Learning Visual Styles from Audio-Visual Associations | https://arxiv.org/pdf/2205.05072 | - | https://tinglok.netlify.app/files/avstyle | 声音驱动的图像程式化 | 从视听学习视觉风格 |
| Exploring Fine-grained Audiovisual Categorization with the SSW60 Dataset | https://arxiv.org/pdf/2207.10664 | Sapsucker Woods 60 (SSW60) | https://ml-inat-competition-datasets.s3.amazonaws.com/ssw60/ssw60.tar.gz | 视听细粒度分类~audiovisual fine-grained categorization | - |
| A Dataset for Interactive Vision-Language Navigation with Unknown Command Feasibility | https://arxiv.org/pdf/2202.02312 | MoTIF | https://github.com/aburns4/MoTIF | 视觉语言导航~Vision-language navigation | - |
| BRACE: The Breakdancing Competition Dataset for Dance Motion Synthesis | https://arxiv.org/pdf/2207.10120 | BRACE | https://github.com/dmoltisanti/brace | 音乐生成舞蹈~audio-conditioned dance motion | - |
| Sound-guided Semantic Video Generation | https://arxiv.org/pdf/2204.09273 | High Fidelity Audio-Video Landscape Dataset | https://kr.object.ncloudstorage.com/eccv2022/dataset/DATASET.csv | 音频驱动的图像生成~sound-guided video generation | - |
| Responsive Listening Head Generation: A Benchmark Dataset and Baseline | https://arxiv.org/pdf/2112.13548 | ViCo | https://onedrive.live.com/?authkey=%21AAg50go2z9lM5f4&id=6C455EA73DD2B60D%218877&cid=6C455EA73DD2B60D | 人与人之间的交互、视频到视频的翻译、跨模态理解和生成 | |
| NewsStories: Illustrating articles with visual summaries | https://arxiv.org/pdf/2207.13061 | NewsStories | https://storage.googleapis.com/gresearch/news-stories/full_newsstories_filtered_split.json | 用视觉摘要说明文章 | |
| MUGEN: A Playground for Video-Audio-Text Multimodal Understanding and GENeration | https://arxiv.org/pdf/2204.08058 | MUGEN | https://mugen-org.github.io/download | 多模态任务 | - |
| PIP: Physical Interaction Prediction via Mental Simulation with Span Selection | https://arxiv.org/pdf/2109.04683 | SPACE+ | - | 物理相互作用预测(physical interaction prediction) | SPACE+是一个为物理相互作用预测而提出的数据集,这个数据集包含了20亿+的视频帧,同事提供了RGB图像、分割图、光流等多种模态的标注 |
| AudioScopeV2: Audio-Visual Attention Architectures for Calibrated Open-Domain On-Screen Sound Separation | https://arxiv.org/pdf/2207.10141 | - | https://google-research.github.io/sound-separation/papers/audioscope-v2/ | Audio-visual sound separation | 这个数据集在YFCC100M的基础上提出,新加入了屏幕上的物体声音标注,针对的任务是音频-视觉分离任务 |
| Sports Video Analysis on Large-Scale Data | https://arxiv.org/pdf/2208.04897 | NSVA | https://github.com/jackwu502/NSVA | 基于体育视频的自动文本描述 | 这个数据集包含了NBA的视频,并且使用文本描述进行标注,任务目标是根据视频自动生成文本标注 |
| A Sketch Is Worth a Thousand Words:Image Retrieval with Text and Sketch | https://arxiv.org/pdf/2208.03354 | - | https://janesjanes.github.io/tsbir/ | 基于语句和草图的图像检索 | 这个数据集包含了5000张对COCO测试集图像的草图和语句描述,任务的目标是根据草图和图像描述进行图像检索 |
| StoryDALL-E: Adapting Pretrained Text-to-image Transformers for Story Continuation | https://arxiv.org/pdf/2209.06192 | DR DiDeMoSV | https://github.com/adymaharana/storydalle | 故事续编(story continuation) | 这个数据集针对的任务是故事可视化(story visualization),即给定一个句子,输出一张图片。在这个任务的基础上,这个数据集支持了故事续编(story continuation)任务,即给定一张源图片,在这张源图片的基础上续编故事 |
| OCR-free Document Understanding Transformer | https://arxiv.org/pdf/2111.15664 | - | https://github.com/clovaai/donut | 文本图像理解(understanding document images) | 这个工作提出了一种人工图像生成方法,通过生成不同语言和不同域的图像,来帮助文本图像理解模型的预训练 |
| Paper Title | URL | 数据集名称 | 数据集链接 | 任务类型 | 数据集简介(包括使用场景、标注类型等) |
|---|---|---|---|---|---|
| MovieCuts: A New Dataset and Benchmark forCut Type Recognition | https://arxiv.org/pdf/2109.05569 | MovieCuts | https://www.alejandropardo.net/publication/moviecuts/ | 视频剪辑类型识别~Video Cut Types Recognition | 本文提出了一种新的任务:视频剪辑类型识别,视频剪辑指的是将两段视频拼接在一起,并且拼接之后的视频看起来具有连续性,不会太突兀。视频剪辑类型识别则是要识别出两段视频是通过何种方式拼接在一起的。 |
| GEB+: A Benchmark for Generic Event Boundary Captioning, Grounding and Retrieval | https://arxiv.org/pdf/2204.00486 | Kinetic-GEB+ | https://github.com/showlab/GEB-Plus | 通用事件边界描述,通用事件边界定位 ,基于通用事件边界描述的视频检索。说明:事件边界指的是视频中某一事物状态发生变化的时间边界,比如某个事物在视频里的0:11时刻发生了变化,那么0:11就是一个事件边界。1、事件边界描述指的是根据视频的事件边界的前后帧的内容生成的文字描述,主要是描述这个时刻存在哪些事物,这些事物处于什么状态;2、事件边界定位指的是根据输入的事件边界描述,在视频中寻找该事件在视频中对应的边界(即发生的时刻)。 3、基于通用事件边界描述的视频检索指的是根据输入的事件边界描述,在若干个视频中寻找出包含了该事件的视频。 | |
| Learning to Drive by Watching YouTube Videos: Action-Conditioned Contrastive Policy Pretraining | https://arxiv.org/pdf/2204.02393 | - | https://github.com/metadriverse/ACO#dataset | 基于视觉的运动策略学习~ visuomotor policy learning | |
| GAMa: Cross-view Video Geo-localization | https://arxiv.org/pdf/2207.02431 | GAMa | https://github.com/svyas23/GAMa | 地理定位 | |
| My View is the Best View: Procedure Learning from Egocentric Videos | https://arxiv.org/pdf/2207.10883 | EgoProceL | https://sid2697.github.io/egoprocel/ | 流程学习(某项任务的逻辑流程图) | - |
| GIMO: Gaze-Informed Human Motion Prediction in Context | https://arxiv.org/pdf/2204.09443 | GIMO | https://github.com/y-zheng18/GIMO | 行为预测(机器人,ar/vr) | - |
| HDR-Plenoxels: Self-Calibrating High Dynamic Range Radiance Fields | https://arxiv.org/pdf/2208.06787 | - | - | 高动态范围(HDR)成像 | 包含了用多种相机参数拍摄的多角度的图像数据 |
| Fine-Grained Visual Entailment | https://arxiv.org/pdf/2203.15704 | - | https://github.com/SkrighYZ/FGVE | 视觉蕴涵 | 重新标注了Flickr30K |
| TIDEE: Tidying Up Novel Rooms using Visuo-Semantic Commonsense Priors | https://arxiv.org/pdf/2207.10761 | - | https://drive.google.com/file/d/1KFUxxL8KU4H8dxBpjhp1SGAf3qnTtEBM/view | 整理房间 | 根据AI2THOR数据集修改创建 |
| The Anatomy of Video Editing: A Dataset and Benchmark Suite for AI-Assisted Video Editing | https://arxiv.org/pdf/2207.09812 | Anatomy of Video Editing | https://github.com/dawitmureja/AVE | 视频编辑任务 | 从196176个电影场景中采样的镜头中注释了超过1.5万个标签,与电影摄影相关的概念 |
| EgoBody: Human Body Shape and Motion of Interacting People from Head-Mounted Devices | https://arxiv.org/pdf/2112.07642 | EgoBody | https://egobody.ethz.ch/ | 推理交互~interactions reasoning | 机器人交互过程中以自我为中心进行人体姿态估计、运动估计等 |
| StyleBabel: Artistic Style Tagging and Captioning | https://arxiv.org/pdf/2203.05321 | StyleBabel | - | 细粒度的艺术风格属性描述~fine-grained artistic style attribute description | - |
| AssistQ: Affordance-centric Question-driven Task Completion for Egocentric Assistant | https://arxiv.org/pdf/2203.04203 | AssistQ | https://docs.google.com/forms/d/e/1FAIpQLSf6dtWUpzwAj0xId05UybQmQ7KVsltqpjCt-oMOVpWT4ybGNw/viewform?usp=send_form | 以供给为中心的问题驱动的任务完成~Affordance-centric Question-driven Task Completion | 新提出的task |
| Towards Accurate Active Camera Localization | https://arxiv.org/pdf/2012.04263 | 1. The ACL-Synthetic 2. ACL-Real datasets" |
https://drive.google.com/file/d/1OIKUeQDfdNuxwyTlXP3KpJyk4p-Nsyjn/view?usp=sharing | 主动相机定位~active camera localization | |
| FS-COCO: Towards Understanding of Freehand Sketches of Common Objects in Context | https://arxiv.org/pdf/2203.02113 | FS-COCO | https://github.com/pinakinathc/fscoco | 写意场景素描理解~freehand scene sketch understanding | |
| DexMV: Imitation Learning for Dexterous Manipulation from Human Videos | https://arxiv.org/pdf/2108.05877 | DexMV | https://yzqin.github.io/dexmv/ | 模仿学习~understanding hand-object interactions | DexMV是平台和pipeline,改善机器人执行复杂的灵巧操作 |
| PACS: A Dataset for Physical Audiovisual Commonsense Reasoning | https://arxiv.org/pdf/2203.11130 | PACS | https://drive.google.com/drive/folders/1TjOKBTU9dsytHJIb919V4wXFR1Zm5TsJ?usp=sharing | 物理常识推理~real-world physical commonsense reasoning | - |
| POP: Mining POtential Performance of new fashion products via webly cross-modal query expansion | https://arxiv.org/pdf/2207.11001 | Visuelle 2.0 dataset | https://github.com/HumaticsLAB/POP-Mining-POtential-Performance | 新时尚产品性能预测~New Fashion Product Performance Forecasting | - |
| Dress Code: High-Resolution Multi-Category Virtual Try-On | https://arxiv.org/pdf/2204.08532 | Dress Code | https://github.com/aimagelab/dress-code | 虚拟试衣~Image-based virtual try-on strives | - |
| Domain Knowledge-Informed Self-Supervised Representations for Workout Form Assessment | https://arxiv.org/pdf/2202.14019 | Fitness-AQA | https://docs.google.com/forms/d/e/1FAIpQLScMR4LQ0uGatjrbuiMCCpYrQxGv1Lsq4XxIWJ_632c0mlpxow/viewform | 自监督表示 | - |
| AnimeCeleb: Large-Scale Animation CelebHeads Dataset for Head Reenactment | https://arxiv.org/pdf/2111.07640 | AnimeCeleb | https://docs.google.com/forms/d/e/1FAIpQLSecwndYXhzBbwXhpZRguZxMTqrrJwEI3Az7USsUkpQtx05q8Q/viewform | 动画头部重演 | - |
| Geometric Features Informed Multi-person Human-object Interaction Recognition in Videos | https://arxiv.org/pdf/2207.09425 | MPHOI-72 | - | 人-物体交互检测(human-object interaction recognition) | MPHOI-72是一个针对HOI任务提出的数据集,这个数据集的特点是提供了多人-多物体的交互场景以及标注 |
| Break and Make: Interactive Structural Understanding Using LEGO Bricks | https://arxiv.org/pdf/2207.13738 | - | https://github.com/shubham1810/trove_toolkit | Break and Make(对积木进行拆散和重组) | 这篇文章提出了两个由乐高积木组成的数据集,一个由乐高爱好者开发完成,一个由作者团队用模拟器模拟生成,用于提出的break and make任务 |
| TRoVE: Transforming Road Scene Datasets into Photorealistic Virtual Environments | https://arxiv.org/pdf/2208.07943 | - | https://github.com/shubham1810/trove_toolkit | synthetic data generation(新数据生成) | 这篇工作提出了一种生成新的人工生成数据的pipeline,在cityspaces和KITTI-STEP上生成的人工数据有更高的质量 |
| AutoTransition: Learning to Recommend Video Transition Effects | https://arxiv.org/pdf/2207.13479 | - | https://github.com/acherstyx/AutoTransition | video transitions recommendation (VTR,视频转换推荐) | - |
| Grounding Visual Representations with Texts for Domain Generalization | https://arxiv.org/pdf/2207.10285 | CUB-DG | https://github.com/mswzeus/GVRT | 域泛化(domain generalization) | 这个数据是基于CUB提出的一个在域泛化场景下,和语句标注场景下的数据集,每个图片包含了十句语言描述 |
参考文献 [1] Cai Z, Ren D, Zeng A, et al. HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling[J]. arXiv preprint arXiv:2204.13686, 2022.
[2] Chen L, Sima C, Li Y, et al. PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark[J]. arXiv preprint arXiv:2203.11089, 2022.
[3] Mei J, Zhu A Z, Yan X, et al. Waymo open dataset: Panoramic video panoptic segmentation[J]. arXiv preprint arXiv:2206.07704, 2022.
[4] He J, Yang S, Yang S, et al. Partimagenet: A large, high-quality dataset of parts[J]. arXiv preprint arXiv:2112.00933, 2021.
[5] Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database[C]//2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009: 248-255.
[6] Hessel J, Hwang J D, Park J S, et al. The abduction of sherlock holmes: A dataset for visual abductive reasoning[J]. arXiv preprint arXiv:2202.04800, 2022.
[7] Pardo A, Heilbron F C, Alcázar J L, et al. Moviecuts: A new dataset and benchmark for cut type recognition[J]. arXiv preprint arXiv:2109.05569, 2021.
[8] Qin Y, Wu Y H, Liu S, et al. Dexmv: Imitation learning for dexterous manipulation from human videos[J]. arXiv preprint arXiv:2108.05877, 2021.
[9] Zhou M, Bai Y, Zhang W, et al. Responsive Listening Head Generation: A Benchmark Dataset and Baseline[J]. arXiv preprint arXiv:2112.13548, 2021.